
新智元报道
当硅谷公司Taalas将大模型「物理焊死」进芯片引发全球半导体行业的关注时,上海交通大学、辉羲智能及微软亚洲研究院的研究团队已更进一步——他们采用ROM+SRAM异构架构,使端侧LLM推理速度提升至20,000 tokens/s,极大地提升了端侧算力。
最近,硅谷初创公司Taalas提出的「模型即芯片」方案引起了全球半导体界的深入讨论和反思。
他们绕过了所有热门概念,直接将AI大模型物理焊接在硅片上!
芯片运行Llama 3.1 8B的速度达到了17,000 tokens/秒。
这比业界顶尖的英伟达GPU快了近十倍。

英伟达同样积极行动,GTC 2026前夕,英伟达明确表示即将发布的Feynman架构将与Groq LPU技术深度融合。
LPU架构通过预先编排的固定指令流驱动模型,并摒弃了传统的HBM主存方式,转而采用片上SRAM存储权重,极大地突破了原有的访问速度和带宽限制。
这些迹象表明,在Scaling Law推动的大模型时代,传统的通用指令集已成为性能提升的障碍。
如何从物理层面彻底解决大语言模型(LLM)部署中的「内存墙」问题,已经成为定义生成式AI未来发展的重要环节。
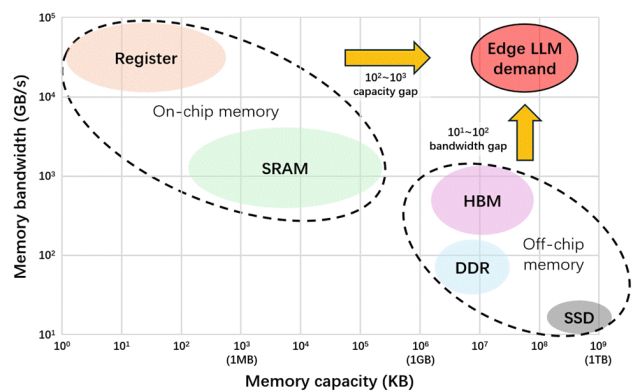
当前端侧存储方案难以同时满足LLM推理所需的存储容量和访问带宽需求。
实际上,针对 LLM 的存取特性,上海交通大学、辉羲智能及微软亚洲研究院的研究团队早已着手进行了一项创新的层次化存储研究。
通过ROMA与TOM系列研究,该团队展示了与Taalas不谋而合的架构洞察:利用颠覆性的只读存储(ROM)应用和「算法-架构」深度协同,成功将LLM 的端侧推理速度提升至20,000 tokens/s,在具身智能等前沿领域展现了巨大的潜力。

ROMA:打破传统存储层次
重塑端侧能效
在大模型端侧部署的实际操作中,传统的内存层次结构正面临前所未有的挑战。
研究团队提出的ROMA(只读记忆加速器)架构,为解决端侧场景的特殊需求提供了一套系统的解决方案。
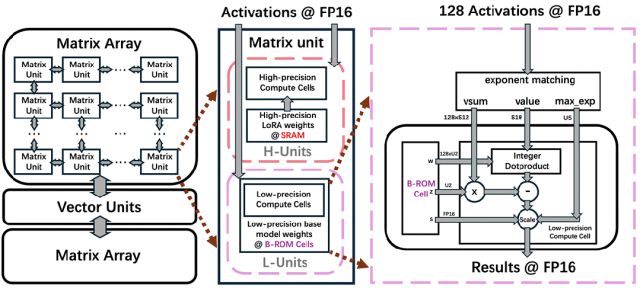
ROMA采用ROM+SRAM的设计方案
1.引入只读存储(ROM):从根本上解决了存取效率问题
研究人员发现,大模型推理中的能耗瓶颈主要源自权重数据在外部内存与计算单元之间的频繁传输。
ROMA另辟蹊径,利用高集成度和低功耗的只读存储(ROM)作为权重载体,将模型参数固结于芯片内部,显著降低了存取能耗。
2.QLoRA 赋予灵活性:在「固化」中寻找演进空间
完全硬连线的芯片往往难以适应算法快速迭代的需求。ROMA巧妙地引入了QLoRA机制,通过结合ROM(基础模型)和SRAM(LoRA适配器),确保了芯片既有强大的性能又保留了高度的应用灵活性。
开发者只需部署极小规模的LoRA插件即可实现不同任务间的快速切换。
3.架构与物理设计协同:极致的硬件实现
在真正实现片上全模型存储的过程中,团队进行了深度的架构和物理设计优化。
独创B-ROM 设计将计算单元与存储阵列进行紧密耦合布局,大幅缩短了信号传输路径。
这种协同设计使 ROMA 在有限芯片面积内高效容纳并实时调度数亿参数模型。
最终,ROMA的规格和性能指标接近Taalas:采用7nm工艺库,芯片面积约500 mm²,可以完整容纳4bit LLaMA3.2-3B 或 2bit LLaMA3-8B,推理性能达到20,000 tokens/s;而同样使用ROM+SRAM架构的Taalas则采用6nm工艺,面积约为800mm²,可容下3-6bit llama3.1-8B,性能接近20,000 tokens/s。
TOM:深入挖掘三值化大模型
带来的存储红利
在 ROMA 的基础上,最新的TOM(三值导向存储)架构进一步优化了算法底层的存储特征,并扩展至BitNet/Ternary量化场景中,利用低比特权重的稀疏性继续提升ROM的存储密度。
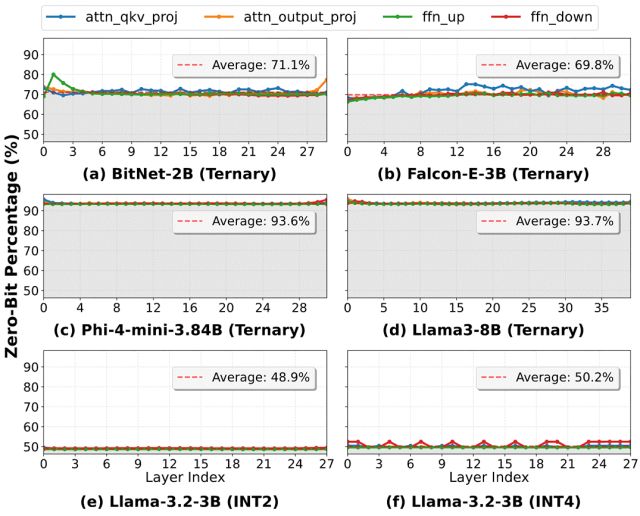
低比特模型零值分布特性带来的ROM存储密度提升潜力
1.揭示 BitNet 的硬件友好性:开启「逻辑代存」新范式
研究团队发现,三值化({-1, 0, 1})模型如BitNet-b1.58表现出极佳的硬件适应性。
基于这一发现,TOM摒弃了传统存储阵列,通过逻辑合成技术直接利用标准逻辑门实现权重固化存储。
这一新范式下,硬件可以直接识别并物理消除权重中「0」元素的存储电路。这得益于三值模型中零值参数天然稀疏特性及定制编码方法(使用「10」而非「11」来表示 -1),从而大幅提升了 0-bit 的整体占比。
2.深度合并与复用:极限压缩芯片面积
为了进一步提升面积效率,TOM引入了精细的逻辑优化策略:通过识别并提取不同权重存储逻辑中的公共子序列,对重复的逻辑门进行深入合并和复用。
这种从物理层面对存储逻辑的「极限去重」使 TOM 相比 ROMA 实现了片上存储密度数倍提升与芯片面积大幅削减。
这再次证明了算法-硬件联合设计在突破AI算力边界时的核心重要性。
具身智能与极端场景
ROM 架构的「降维打击」
「模型即芯片」方案针对当前端侧应用中的两大痛点做出了精准捕捉:
1.具身智能的实时确定性需求
在机器人、无人设备等场景中,毫秒级响应延迟往往决定了系统的物理安全性。
ROMA 提供的20,000 tokens/s 的推理速度确保了在这些场景中的实时确定性需求。
将成熟且稳定的模型能力固化在本地隔离电路中,不仅省去了频繁联网带来的能耗问题,更从物理层面杜绝了数据泄露的风险。
启动端侧内存层次结构的新纪元
从Taalas的创新到研究团队ROMA与TOM系列工作的深入探索,我们见证了一个重要的AI硬件架构转变。
这种引入ROM+SRAM异构存储层次结构和极致挖掘三值逻辑存储特性的创新为端侧大模型部署提供了全新的路径。
ROMA和TOM的研究诞生于「模型即芯片」的设计思维,最早可追溯至微软亚洲研究院(MSRA)时期。
核心作者中,王文强与曹士杰曾作为MSRA实习生在徐宁仪老师的指导下进行研究;张毅佳在上海交通大学攻读博士期间同样师从徐老师,并先后在 MSRA 系统组和辉羲智能实习。
研究团队长期从事算法-芯片联合设计的研究,在AI芯片架构设计、大模型轻量化等方面积累了丰富的经验。
这种由资深架构师、企业研究员与学术新生代组成的多层纽带,使团队能够高效结合前沿实战思维和理论创新,并在大模型范式下实现了从通用计算向 LLM 原生架构的协同突破。
上海交通大学计算机学院定制计算中心(Customized Computing Center - CCC)专注于解决数据中心、边缘设备及传感器面临的各种计算挑战。
结语
辉羲智能致力于成为全球领先的具身智能AI计算平台供应商,通过卓越算力推动人工智能发展。成立三年以来,公司已成功流片并量产交付了大算力端侧旗舰芯片R1,在具身智能领域实现了从“芯片-平台-产品”的全栈自主国产化路径。
ROMA:https://arxiv.org/pdf/2503.12988
TOM:https://arxiv.org/abs/2602.20662
ROMA与TOM系列研究的诞生,植根于“模型即芯片”的设计思维。
团队的这种强调算法与硬件深度耦合的思维来源,最早可追溯至微软亚洲研究院(MSRA)时期。
核心作者中,王文强与曹士杰曾先后作为MSRA实习生在徐宁仪老师指导下开展研究,积淀了深厚的工业界系统经验;张毅佳在上海交大攻读博士期间师从徐老师,并先后在 MSRA 系统组与辉羲智能实习。
研究团队长期从事算法-芯片联合设计的研究,在AI芯片架构设计、大模型轻量化等方面有丰富经验。
这种由资深架构师、企业研究员与学术新生代构成的多重纽带,让团队得以将前沿的实战思维与学术界的理论创新高效结合,在大模型范式下实现了从通用计算向 LLM 原生架构的协同突破。
团队介绍
关于上交大团队:团队来自上海交通大学计算机学院定制计算中心(Customized Computing Center - CCC,ccc.sjtu.edu.cn),CCC聚焦于解决数据中心、边缘设备和传感器的所面临的各种计算挑战。
关于辉羲智能:辉羲智能致力于成为全球领先的具身智能AI计算平台供应商,以卓越算力促进人工智能发展。成立三年,公司已实现大算力端侧旗舰芯片R1的成功流片与量产交付,率先在具身智能领域走通“芯片-平台-产品”的全栈自主国产化路径。
参考资料:
ROMA:https://arxiv.org/pdf/2503.12988
TOM:https://arxiv.org/abs/2602.20662