
FlashAR:仅用0.05%数据,让预训练好的自回归图像模型飞起来
背景:自回归图像生成的崛起与推理瓶颈大语言模型的成功让 "next-token prediction" 这套范式从文本延伸到了图像领域。把图像用视觉分词器编码成离散 token,再一个接一个的预测出来 —— 这就是自回归(AR)图像生成的核心思路。从早期的 PixelCNN、iGPT、Parti,到近期的 Emu3.5、LlamaGen、Lumina-mGPT、GLM-Image,AR 模型的生成
科技1 阅读
共找到 8 篇相关文章
背景:自回归图像生成的崛起与推理瓶颈大语言模型的成功让 "next-token prediction" 这套范式从文本延伸到了图像领域。把图像用视觉分词器编码成离散 token,再一个接一个的预测出来 —— 这就是自回归(AR)图像生成的核心思路。从早期的 PixelCNN、iGPT、Parti,到近期的 Emu3.5、LlamaGen、Lumina-mGPT、GLM-Image,AR 模型的生成
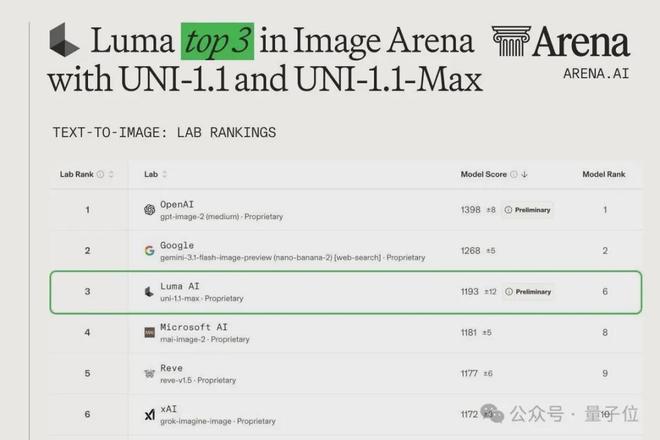
允中 发自 凹非寺量子位 | 公众号 QbitAI一支不到15人的团队,把图像模型做到了全球第三5月6日凌晨,Luma AI正式宣布开放Uni-1.1 API几乎在同一时间,由第三方机构Arena.ai发布的图像生成榜单,完成了最新一轮的“大洗牌”——Luma凭UNI-1.1与UNI-1.1-Max直接冲进全球前三,仅次于OpenAI(gpt-image-2)Google(nano-banana-

当前,各大企业纷纷加大在人工智能领域的投入,转型几乎已成为行业共识。尽管模型和智能代理技术不断进步,但高昂的成本、落地难题以及数据不足等问题依然存在,行业发展仍需迎头赶上。京东则在其AI战略上已明确方向:利用供应链优势推进具身智能发展,让AI真正进入物理世界。最近推出的JoyAI-Image-Edit一体化图像模型,特别适用于生成电商所需图片及训练具身智能的素材。最近,京东开源了名为JoyAI-I

本文由智东西作者江宇编辑漠影撰写。在大型企业中,人工智能的竞争日益激烈,几乎所有人都达成共识,即必须进行转型。尽管模型正在进化,代理应用也逐渐落地,但高昂的成本、艰难的实施过程以及数据不足等问题仍然阻碍了行业的进步。京东在AI领域的布局已经非常明确:围绕其供应链优势,推进具身智能技术的应用,使人工智能真正进入物理世界。近日发布的一体化图像模型JoyAI-Image-Edit正是这一策略的具体体现,

近日,硅谷初创企业Luma AI发布了其最新图像模型Uni-1,该模型结合了图像理解和图像生成的功能,具有强大的思考和创作能力。据测试结果显示,Uni-1的性能与Google的Gemini 3 Pro相当,在高分辨率图像生成方面成本降低了大约10%到30%,并且在空间理解能力方面超越了谷歌Nano Banana 2和OpenAI GPT Image 1.5。Luma AI成立于2021年,最初以D
允中 发自 凹非寺量子位 | 公众号 QbitAI图像领域迎来新的竞争者!最近,Luma AI推出全新图像模型Uni-1,直接挑战谷歌Nano Banana Pro和GPT Image 1.5的地位。Uni-1是一款集成了图像理解和生成功能的统一模型。官方展示中显示,这款模型具备多种能力,包括角色姿态转换、故事板创作、草稿与材质结合生成等。在多个权威任务评估中,Uni-1不仅能够匹敌Nano Ba

图像领域又迎来了一位挑战者! 今天,Luma AI推出了其全新模型Uni-1,直接与谷歌的Nano Banana Pro和GPT Image 1.5展开竞争。 Uni-1是一个集图像理解和生成于一体的统一模型。 据官方展示,该模型具备角色姿态迁移、故事板构建、草稿结合材质参考生成等多种能力。 在一系列权威任务评估中,Uni-1不仅能与Nano Banana Pro和GPT Image 1.5匹

机器之心编辑部突破性的质量,实惠的价格。经过一段时间的期待,Nano Banana 2终于面世了。谷歌首席执行官皮查伊在他的帖子中表示:“这是我们至今为止最好的图像模型。”https://x.com/sundarpichai/status/2027057726170509724目前,该模型已经在 Gemini 应用、Google 搜索(覆盖141个国家)和 Flow 上启用,并且在 Google