 本文由智东西作者江宇编辑漠影撰写。
本文由智东西作者江宇编辑漠影撰写。
在大型企业中,人工智能的竞争日益激烈,几乎所有人都达成共识,即必须进行转型。尽管模型正在进化,代理应用也逐渐落地,但高昂的成本、艰难的实施过程以及数据不足等问题仍然阻碍了行业的进步。
京东在AI领域的布局已经非常明确:围绕其供应链优势,推进具身智能技术的应用,使人工智能真正进入物理世界。近日发布的一体化图像模型JoyAI-Image-Edit正是这一策略的具体体现,适用于电商和具身智能训练场景的图像生成与编辑。
最近,京东将其图像处理模型JoyAI-Image-Edit开源,并引入了空间智能技术,使人工智能能够更好地理解和编辑真实世界中的空间关系。
简单来说,这款模型的核心在于其对三维空间的理解能力,从而让生成的图像更加合理且精确。

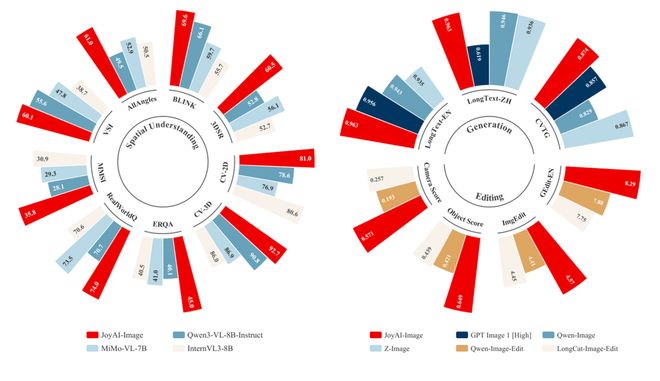
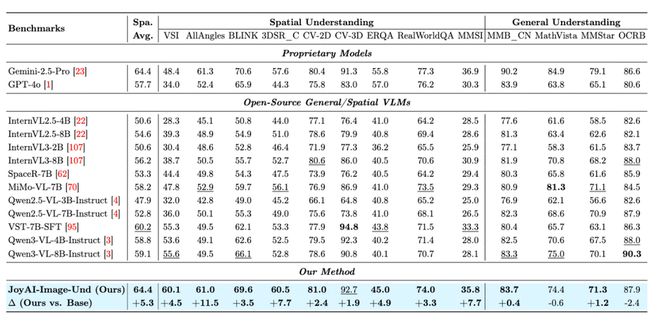
从公开测试结果来看,JoyAI-Image-Edit在各项指标上领先于竞争对手,并进入了国际顶尖行列。例如,在理解空间方面刷新了同级别的开源模型记录,达到了世界领先的水平;在长文本生成和图像编辑等方面也表现出色。
智东西团队对其进行了实际测试,发现该模型能够在调整物体位置时保持结构的一致性。
值得注意的是,在这些实验中,被移动的物体所占画面的比例较小且形状不规则。即便如此,模型在物体移动或旋转的过程中依然能够避免透视变形和遮挡问题的发生。

左图是输入图像及指令,右图则是经过处理后的输出结果。
这类能力尤其适用于电商内容生产和具身智能训练场景,并可进一步应用于建筑设计、游戏开发和影视制作等领域。这两方面与京东现有的AI布局形成了直接的关联。
一、“空间智能”成为模型的重要组成部分:从“会修改图像”到“能操作空间”,图像编辑能力开始分化
常规图像编辑技术的一个主要缺点在于处理三维空间关系的能力较弱,例如替换物体或调整姿态时容易出现比例失真、遮挡和光照不一致等问题。
JoyAI-Image-Edit则着重于提高这一方面的性能。除了支持常见的15种编辑任务外,它还能够执行移动物体、旋转视角等操作,并能理解诸如“向右移动0.3米”、“转动45度”这样的具体指令。
在技术架构上,该模型采用了MLLM+VAE+扩散模型的组合设计。
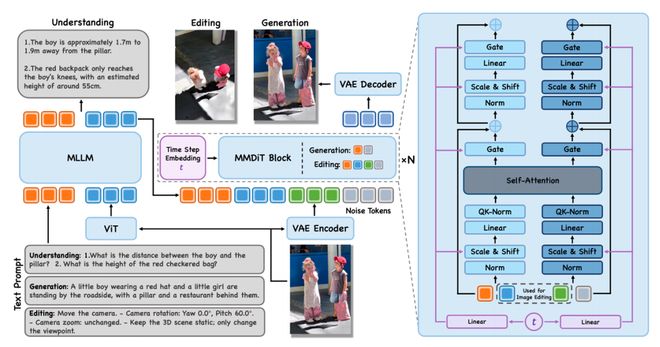
具体而言,MLLM负责空间理解和语义建模工作,而扩散模型则用于生成和编辑图像。通过这种方式,在生成过程中直接使用了空间信息,形成了“理解-生成-再理解”的循环结构。
这种性能的提升得益于数据体系的设计变革:包括OpenSpatial-3M在内的多个大规模数据集以及多视角生成数据等资源都被用来指导模型学习真实世界中的几何关系。
由于这些设计特点,JoyAI-Image-Edit在2D语义感知、3D空间理解和4D时空推理等多个领域的测试中均表现出色,在9个与空间理解相关的基准测试上得分最高,平均分达到了64.4,并且追平了封闭源代码的Gemini-2.5-Pro模型。
在SpatialEdit-Bench这样的评估体系下,JoyAI-Image-Edit的表现尤为突出。它在对象整体评分和相机视角评分等方面都领先于其他图像编辑工具。
同时,在GEdit和ImgEdit这两个权威排行榜上,该模型也刷新了记录,并且得分分别为8.27和4.57。
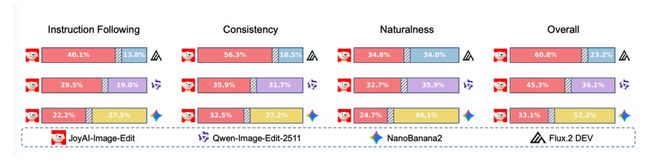
在一项包含249个测试集的黑盒人工评测中,JoyAI-Image-Edit的表现优于Qwen-Image-Edit-2511以及Flux2.Dev等竞争对手。

总体来说,将空间理解、生成和编辑功能整合到同一系统里可以使得模型不仅能够“描绘”图像内容,还能明确物体的位置变化是否合理。
当图像处理不再局限于简单的修改而具备了实际的操作能力时,其应用范围也随之扩大。
二、电商与具身智能场景的应用广泛
空间编辑技术最先受益于那些依赖现实世界数据的领域。
在电子商务中,商品多角度展示、虚拟试衣和摆放位置调整等任务都需要高度一致的空间关系。
JoyAI-Image-Edit的空间能力在电商场景的应用中带来了显著的效果:能够移动物体、旋转视角并理解具体的几何参数。
比如,对于服装或鞋子类商品而言,展示不同角度和姿态是常见的需求。使用该模型可以一键调整衣物的折叠方式或是鞋的位置,并且保持整体的一致性。

左图显示原始输入图像及指令,右图则是处理后的结果。
对于家电、家具或电子产品,则可以通过空间编辑功能在不同场景下展示商品的不同布局,如沙发在客厅和卧室中的摆放位置等。

结合模型的通用编辑能力,还可以进行文字标注、色彩微调以及背景修饰等工作,实现一次性满足多种需求的效果。

这样一来,电商平台可以更高效地生成高质量的商品图,降低拍摄成本并保持展示效果的一致性。
在具身智能训练方面,这些能力同样适用。
对于机器人等设备来说,真实世界数据的获取成本高昂且耗时。利用该模型可以生成大量具有空间一致性的高质量图像数据,为机器人的学习和决策提供支持。
通过生成新的视角辅助进行空间推理,不仅可以用于内容生产,还能够反向提高机器人对现实世界的理解和识别能力。
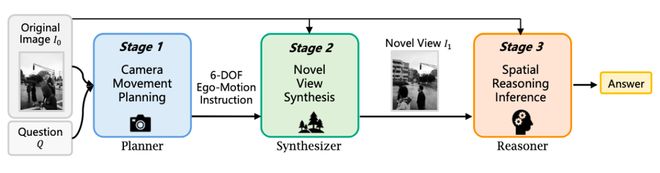
因此,在电商和具身智能领域中,该模型都是实现高效操作的关键工具。
三、开源项目揭开京东AI全景布局
开源JoyAI-Image-Edit是京东在大型实体世界应用人工智能战略的一部分。然而,这只是其众多举措之一。
在此之前不久,京东还开放了另一个模型JoyAI-LLM Flash,该模型同样表现出色,在同等参数规模下提供了更优的性能和效率,并降低了开发者的使用门槛。
同时,京东也在供应链及线下场景中采取了一系列措施:一方面建立了全球最大的具身智能数据采集中心以促进训练;另一方面通过JoyInside将AI技术嵌入家电、机器人以及玩具终端设备,让模型直接应用于实际环境中与用户交互。
从开源模型的应用和这些具体部署来看,京东正在尝试在模型开发、数据收集及硬件使用上形成闭环。
开源可能是第一步,而通过持续挖掘AI技术在各类产业场景中的应用价值,则展现了其潜在的落地路径。
总结:一手开放共享,一手深度实践
京东在此次开源JoyAI-Image-Edit的过程中体现了明确的战略方向——一方面降低模型使用门槛;另一方面将AI能力嵌入到供应链、物理世界及具体产业场景中,形成从数据到终端的全链条闭环。
此举不仅展示了其实用主义的作风,也预示了京东在未来利用人工智能驱动业务增长的巨大潜力。
作为其核心竞争力之一,强大的物流和商品供应网络如今在AI时代得到了进一步强化——模型可以被嵌入到各种设备中,而数据则会不断回流用于持续优化。
在当前环境下,AI有望成为京东推动业务增长的新动力源。
在今天,AI有望成为京东的另一张“增长引擎牌”。
注:文中部分输入图来源于Arena