- 允中 发自 凹非寺
量子位 | 公众号 QbitAI
图像领域迎来新的竞争者!
最近,Luma AI推出全新图像模型Uni-1,直接挑战谷歌Nano Banana Pro和GPT Image 1.5的地位。

Uni-1是一款集成了图像理解和生成功能的统一模型。
官方展示中显示,这款模型具备多种能力,包括角色姿态转换、故事板创作、草稿与材质结合生成等。

在多个权威任务评估中,Uni-1不仅能够匹敌Nano Banana Pro和GPT Image 1.5,在某些方面甚至超过了它们的性能。
比如在一个具体的案例中,Uni-1在风格一致性、元素融合以及细节还原等方面表现突出。
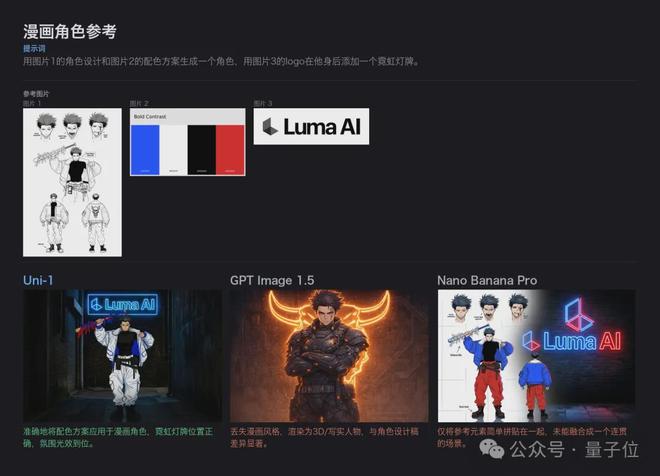
更为引人注目的是,尽管没有大公司投入大量资源,这支由不到15位华人研究人员组成的团队却取得了如此卓越的成绩。
Uni-1发布后获得广泛的赞誉,谷歌DeepMind首席科学家Oliver Wang也对该模型表示认可:
英伟达机器人主管Jim Fan同样对Uni-1寄予厚望:

接下来让我们通过更多实例来感受一下Uni-1的实际效果。
解锁多元创作场景
马年新春贺卡
先来一个简单的测试:
创建一张含有“新春快乐”、“马年大吉·万事如意”和“二〇二六”的春节贺卡,需要准确地呈现中文文字与传统剪纸风格的结合。

Uni-1生成的贺卡不仅文字清晰且排版合理,而且完美再现了中国传统元素。相比之下,GPT Image 1.5的文字布局混乱,Nano Banana Pro在文字渲染上也有瑕疵。
在处理中文文本时,Uni-1展现出了其强大的能力——这一直是图像模型的一大挑战。
多参考图场景合成
给定五张参考图(包括两只猫、两名男士和Luma AI的标志),要求合成一个会议场景。
Uni-1能够精准地将每一张图片中的特征融入同一个画面,如猫的颜色花纹、人物的脸部特征以及公司的logo等元素都被完美展现出来。
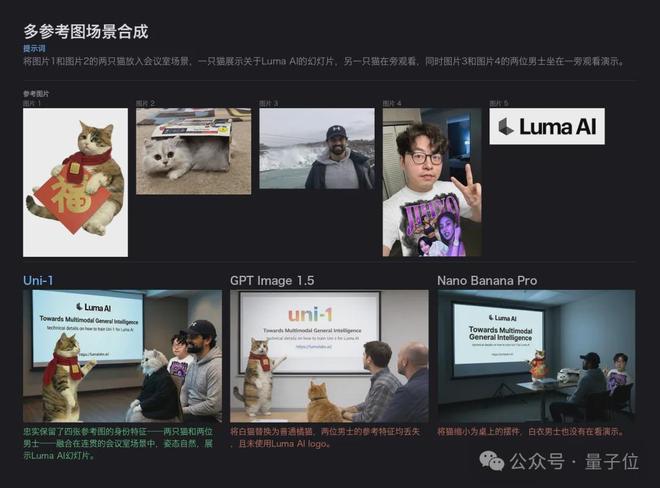
GPT Image 1.5只是简单拼贴参考图,Nano Banana Pro则无法做到合理融合。
当面对“THE BEES NEED YOU”公益海报提取信息的任务时,Uni-1不仅能够准确还原整个布局、文字和颜色配比,还能完美复制背景中的黑色草地剪影以及正确的纵横比例。GPT Image 1.5在部分文字上出现了错误的色彩选择,并且缺失了底部的文字内容;Nano Banana Pro也未能完整呈现所有信息。
信息图提取
接下来展示的是Uni-1的漫画生成能力——将一张草稿图(一只猫站在书架旁,旁边有人呼喊“Hey! Get down from there!”)转化为专业级漫画作品。

Uni-1成功地把草稿中的意图转化成了专业的漫画形式:准确再现了分格构图、对话气泡的位置和方向,并且保留了所有细节——从猫的耳朵到翘起的尾巴,再到书架上的书籍甚至手机屏幕显示的数字911。
接下来要展示的是一个更为复杂的任务:
创作一套展现一个人一生在钢琴前度过的6帧故事板。这套图像需要表现从童年到老年各个阶段的变化,并且人物形象和背景随着时间推移而变化,但脸部保持一致。
草稿转漫画
这样的跨画面统一性和叙事能力是目前大多数模型难以实现的挑战之一。

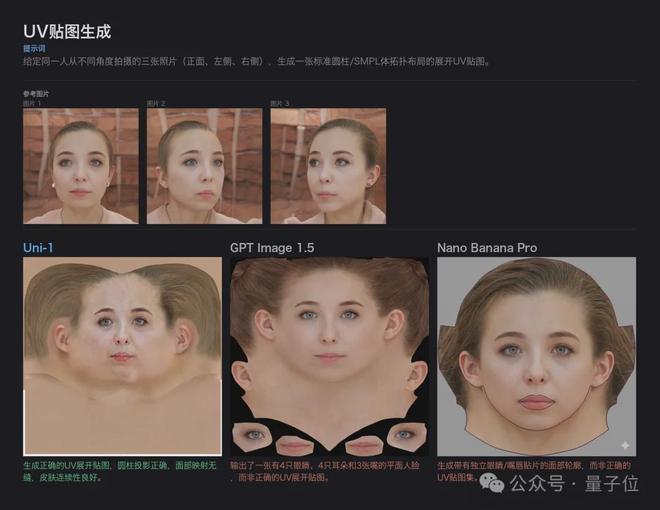
接下来的任务涉及三维建模——利用三张不同视角的人脸照片生成一张符合标准规范的UV贴图。
为了完成这一任务,Uni-1不仅需要精确对齐面部特征和保持左右对称性,还要确保肤色的一致性。在这个方面,Uni-1的表现优于GPT Image 1.5和Nano Banana Pro:前者在正脸与侧脸的贴图上存在不一致的问题;后者则未能生成符合标准布局的结果。
Uni-1能够完成如此复杂的3D任务,证明它不仅仅擅长图像绘制,更具备对三维空间结构深层次的理解能力。
令人好奇的是,这样一个由不到15人组成的团队是如何在没有大规模资源支持的情况下取得这样杰出成就的?

答案或许在于这支团队的核心成员:
UV贴图生成
宋佳铭来自清华大学和斯坦福大学,并发明了DDIM(Denoising Diffusion Implicit Models)模型。
这一技术已被广泛应用于各种基于扩散模型的图像生成工具中,极大提升了生成效率。其论文至今已获得超过万次引用并赢得了ICLR 2022杰出论文奖。
沈博魁同样毕业于斯坦福大学,并获得了CVPR 2018最佳论文奖——这是计算机视觉领域的顶级会议之一,每年仅有少数几篇论文能获此殊荣。此外他还入选了RSS 2022最佳学生论文决赛。
这两位华人学者联手带领小团队开辟了一条不同于大型科技公司的创新路径:
不是将理解和生成任务分开处理,而是通过一个统一的模型来同时完成这两项工作。
不到15人,凭什么?
Uni-1的核心理念在于为逻辑大脑赋予“心灵之眼”。
传统的做法中,图像理解(比如看图说话、物体检测)和图像生成(如文生图、图片编辑)是两个独立的部分。然而Uni-1采用了一种单一的解码器自回归Transformer架构,使得文本与图像信息可以在同一序列上进行处理。
这样一来,不需要分别训练“理解模块”和“生成模块”,而是在一个统一框架中同时建模时间、空间以及逻辑。
更有趣的是,Luma发现当模型学会绘制之后,“看图”的能力也会随之增强——这与人类的认知模式不谋而合。
在推理式图像生成任务中,Uni-1会在合成图像之前进行结构化内部推理:先分析指令、规划构图,再完成渲染输出。

这种“思考在行动前”的能力让模型在RISEBench(评估时间推理、因果关系推理、空间推理和逻辑推理四个方面)测试中取得了领先的成绩。
在开放词汇密集检测基准上,Uni-1同样显示出了强大的竞争力——要知道这通常是由专为理解设计的模型主导的任务领域。一个统一的模型能够在理解和生成任务上均表现良好,本身就说明了它的重要性和潜力。

将Uni-1置于更广阔的AI行业背景中来看,有两点值得注意:
首先,统一模型可能是未来视觉AI的发展方向。
当理解与生成不再是两个独立的系统,而是同一模型的不同方面时,许多过去需要多步骤处理的任务可以在一个模型内优雅地完成。Uni-1已经在这些任务上展现了这种优势。
其次,顶尖的人工智能研究不一定依赖于庞大团队和无限计算资源。
尽管规模较小,但这个华人科研小组却在由Google和OpenAI主导的赛道上做出了世界级成果。这再次证明,在正确的技术路径下,优秀人才密度可以弥补资源上的不足。
Luma表示,Uni-1只是一个开始。未来计划将这一统一框架扩展到视频、语音等领域,并最终构建一个能够“看、说、推理和想象”的多模态系统。
从这样一个由不到15位华人组成的团队起步,这个目标似乎并不遥远。
在推理式生成任务中,Uni-1会在合成图像前进行结构化的内部推理:先分解指令、规划构图,然后再渲染输出
这种“先想后画”的能力,让它在RISEBench(评估时间推理、因果推理、空间推理和逻辑推理四个维度的基准测试)上取得了世界最优成绩
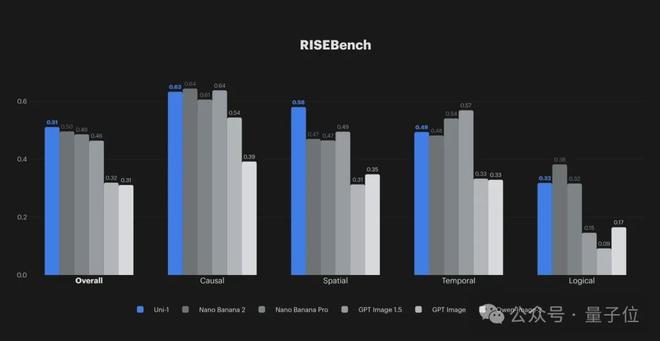
在开放词汇密集检测(ODinW-13)基准上,Uni-1同样展现出了强劲的竞争力——要知道,这是一个传统上由纯理解模型主导的领域。一个统一模型能在理解任务上也不输专门的理解模型,本身就已经是一个重要的信号。
为什么这很重要?
把Uni-1放到更大的AI行业图景中看,有两件事值得关注:
第一,统一模型可能是下一代视觉AI的方向。
当理解和生成不再是两个独立系统,而是同一个模型的两面,很多过去需要复杂pipeline的任务——多轮编辑、参考图合成、风格迁移——都可以在一个模型内优雅地完成。Uni-1已经在这些任务上展示了这种优势。
第二,顶尖AI研究不一定需要万人团队和无限算力。
不到15人的华人研究团队,在一个被Google和OpenAI主导的赛道上做出了世界级的成果。这再次证明:在正确的技术路线上,优秀的人才密度可以弥补资源的差距。
Luma表示,Uni-1只是第一步。下一阶段,这个统一框架将从静态图像扩展到视频、语音、交互式世界模拟——最终目标是构建能够“看、说、推理、想象”的统一多模态系统。
从一个不到15人的华人团队开始,这个目标或许并不遥远。
Luma AI官方博客:https://lumalabs.ai/uni-1