
当前,各大企业纷纷加大在人工智能领域的投入,转型几乎已成为行业共识。尽管模型和智能代理技术不断进步,但高昂的成本、落地难题以及数据不足等问题依然存在,行业发展仍需迎头赶上。
京东则在其AI战略上已明确方向:利用供应链优势推进具身智能发展,让AI真正进入物理世界。最近推出的JoyAI-Image-Edit一体化图像模型,特别适用于生成电商所需图片及训练具身智能的素材。
最近,京东开源了名为JoyAI-Image-Edit的新一代图像处理技术,该技术结合空间智能和图像编辑功能,使AI能够理解和编辑现实世界中的空间关系。
通过这一模型,AI得以理解三维空间,并生成更合理的图像内容,同时提供精确的图片编辑服务。

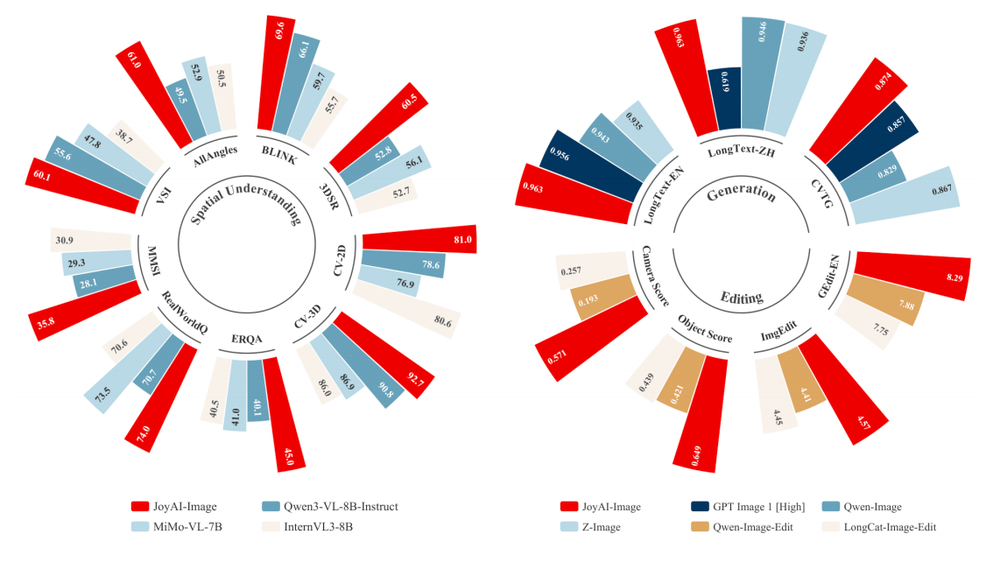
根据公开测试结果,JoyAI-Image-Edit在各项指标上均表现出色,跻身国际顶尖行列:它刷新了同类型开源模型的性能上限,在空间理解和图像生成方面达到了世界领先水平。特别是在长文本生成和中英文双语处理能力上,与闭源模型Gemini 2.5 Pro不相上下。
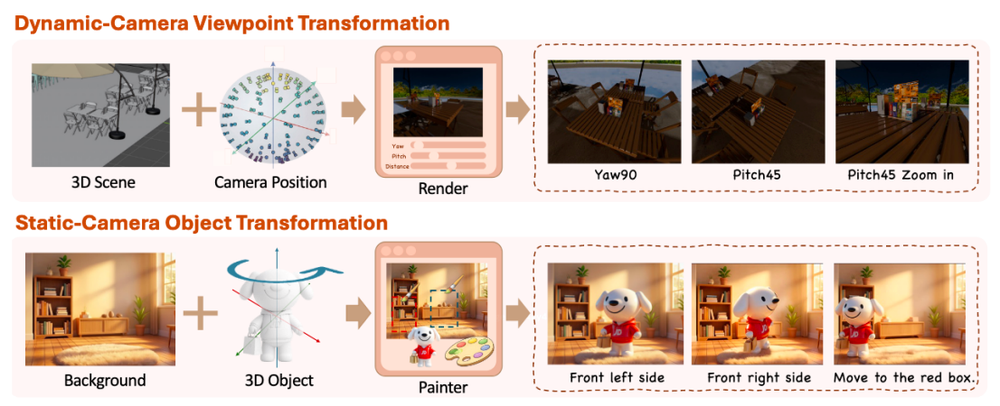
在实际测试中,该模型在调整物体位置等场景下保持了良好的结构一致性。
即使是在那些占据画面比例较小且形状复杂的物品移动或旋转时,它也能有效避免透视错乱和遮挡问题,并确保整体画面自然流畅。

输入图与指令(左)、输出图(右)
这些能力尤其适用于电商内容制作及具身智能训练等场景,同时也可应用于建筑设计、游戏开发以及影视制作等领域。这与京东现有的AI战略形成了直接呼应。
01.
将“空间智能”融入模型设计:
从“修图工具”到具备动态空间处理能力
图像编辑能力开始分层
典型的图像编辑软件在理解和处理复杂的空间关系时存在局限,容易出现比例失真、遮挡错误等问题。这些问题的根本原因在于缺乏对几何特性的精准理解。
JoyAI-Image-Edit通过专门针对空间操作进行优化,除支持传统的十五类通用编辑任务外,还增强了物体移动和旋转等高级功能,并能解析带有精确几何参数的指令,使整个编辑过程更具可控性。
在架构设计上,该模型采用了MLLM+VAE+扩散模型(MMDiT)的整体框架。
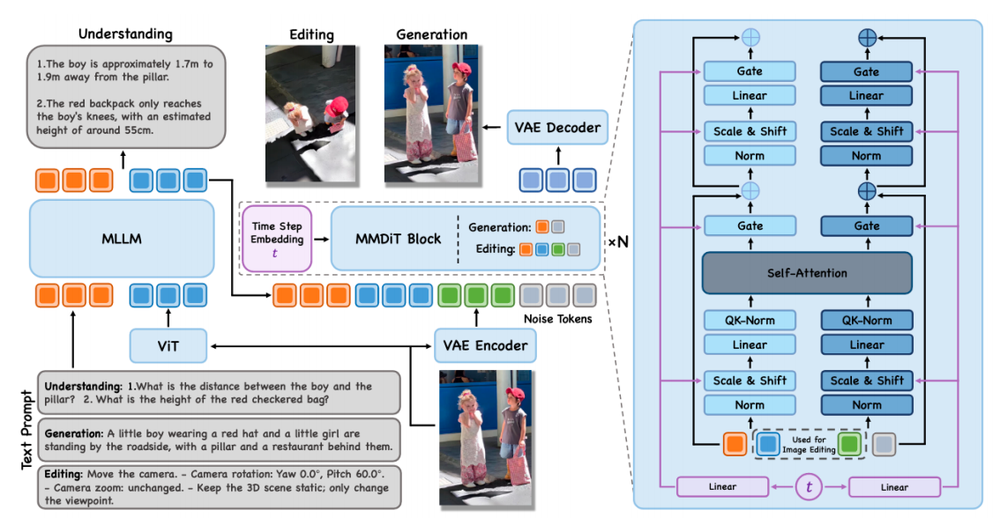
具体而言,MLLM负责空间感知与语义建模,而扩散模型则执行生成和编辑任务。在训练过程中,模型将直接学习真实世界的几何关系,并在此基础上不断优化其性能。
数据集的重建是提升空间能力的关键——包括OpenSpatial-3M在内的大规模数据集、多视角生成数据以及记录精确位姿参数的空间编辑数据等,都为模型提供了必要的训练素材。
通过这种设计,在2D语义感知、3D空间理解和4D时空推理等多个层面的测试中,JoyAI-Image-Edit在九项关键指标上均取得了显著进步。其平均得分达到64.4分,与闭源模型Gemini 2.5 Pro持平。
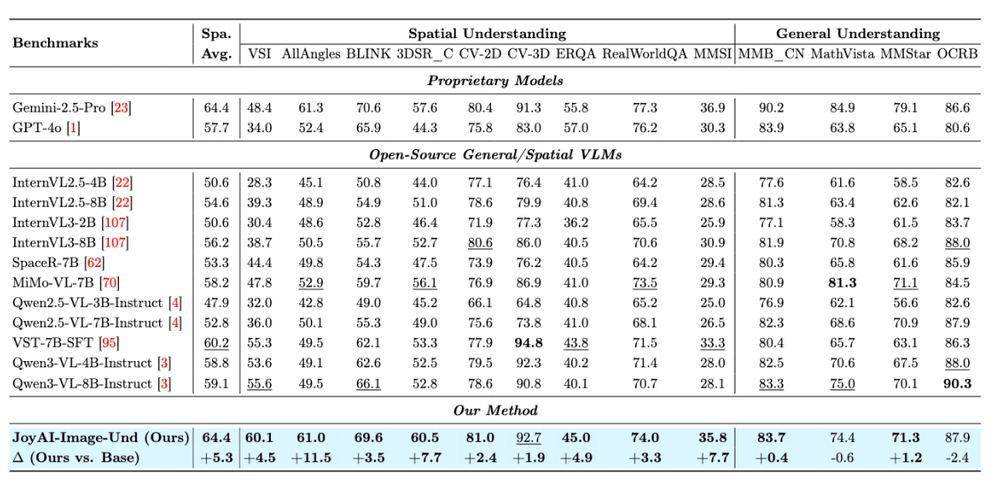
在SpatialEdit-Bench的评估中,该模型的空间编辑能力尤为突出:物体整体得分为0.649,相机视角调整得分为0.571,明显领先于其他图像编辑工具。其精度超越了Veo3.1、ViduQ2-Turbo和Kling等视频世界模型。
同时,在GEdit(侧重中文指令的评估)和ImgEdit(注重全面能力测试)两个权威榜单中,JoyAI-Image-Edit也取得了8.27和4.57分的成绩,刷新了开源图像编辑工具的最佳表现记录。
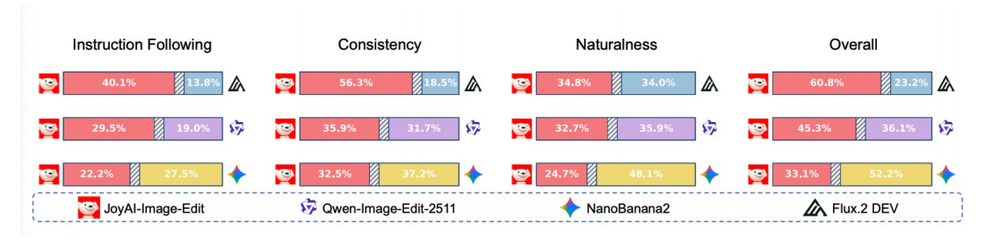
在一项包含249个黑盒测试集的人工评分中,JoyAI-Image-Edit的表现优于Qwen-Image-Edit-2511以及Flux2.Dev

这表明将空间理解、生成和编辑整合到同一框架内可以大幅提升模型的功能。
当图像处理不再只是简单的修改时,其能力边界也随之扩大。
02.
电商与具身智能场景中的高适应性,
空间技术开始带来直接效益
成熟的空间编辑技术首先在依赖“真实世界”数据的领域展现了显著优势。
在电子商务中,商品多角度展示、虚拟试穿以及摆放位置调整等任务对图像的一致性有极高的要求。
JoyAI-Image-Edit的空间编辑功能——包括移动物体、旋转视角及理解几何参数——在电商场景下提供了巨大的应用潜力。
例如,在处理服饰和鞋类产品时,经常需要展示不同角度或姿态。使用此模型可以在原始图片基础上一键调整衣物折叠方向、鞋子摆放位置或手提包的携带方式,而无需重新拍摄,并且能保持一致的比例、光影效果及背景设计。

输入图(左)、输出图(右)、指令:将运动鞋旋转以展示正面
对于家电、家具和小型电子产品而言,空间编辑功能允许商品在不同场景中“自动换位”或进行视角切换,如沙发摆放角度的调整或咖啡机的台面布局变换等。

结合模型的通用编辑能力,还可以实现文字标注、色彩微调及背景修饰等一系列“一键精修”的操作,满足多种需求。

这样一来,电商团队能够快速生成高质量的商品图片,减少拍摄成本,并确保展示效果的一致性。
在具身智能训练领域,这些功能同样适用。
机器人需要大量的真实世界数据进行训练,但获取这类数据的成本高昂且耗时较长。该模型可以生成具备高度一致性的图像数据,用于补充训练资料,从而提高效率和效果,并有助于解决数据稀缺的问题。
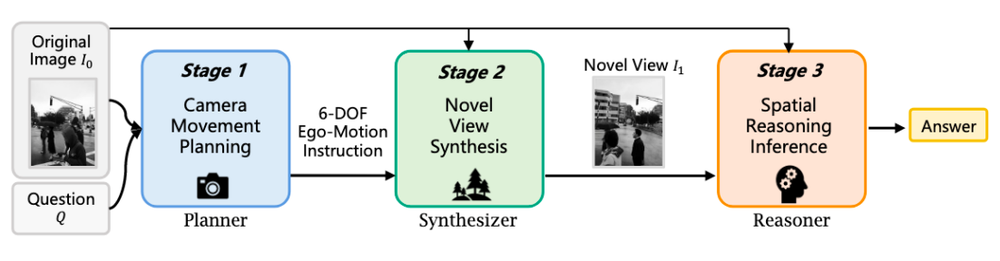
同时,通过生成新的视角来辅助空间推理(Thinking with Novel Views),模型不仅能够支持内容创作,还能提升对环境的理解能力,为机器人“理解世界”提供帮助。
因此,在电商及具身智能领域,JoyAI-Image-Edit是实现空间理解与编辑的重要工具。
03.
开源模型的推出,京东AI布局渐显
此次开源JoyAI-Image-Edit标志着京东在构建面向现实世界的强大人工智能体系中的又一重要步骤。然而,这并非其唯一的动作。
除了这款图像处理工具,京东还发布了名为JoyAI-LLM Flash的模型,该模型在同等参数规模下显著提升了性能和效率,降低了开发者使用门槛,避免了单纯依赖大规模参数的竞争模式。
同时,在供应链及线下场景中,京东也在积极布局:一方面建立了全球最大的具身智能数据采集中心,并结合自研模型进行训练;另一方面通过JoyInside将AI能力嵌入家电、机器人等终端设备,使其能够在实际环境中运行并收集用户反馈。
结合开源模型的实际应用以及这些应用场景的动作来看,京东正在努力构建从模型到终端的闭环体系。
开源或许只是开始,而深入产业场景中的实践则为观察京东AI能力的应用路径提供了更多视角。
04.
总结:京东开源与落地并重
通过此次JoyAI-Image-Edit的开源行动可以看到,京东在人工智能领域采取了明确的战略:一方面开放技术资源降低门槛;另一方面将AI嵌入供应链、物理世界及实际产业场景中,形成从数据到模型再到终端应用的闭环。
可以说,京东在实施其人工智能战略时非常务实。借助于强大的供应链体系,在AI时代下,这一优势被进一步放大——商品、物流和设备可以无缝集成AI技术,并持续优化其功能。
当前,人工智能正成为推动京东增长的另一关键引擎。
供应链是京东最硬的一张牌。在AI时代,这张牌的价值进一步放大——模型可以嵌入商品、物流与设备,数据可以持续回流,能力可以不断迭代。
在今天,AI有望成为京东的另一张“增长引擎牌”。