百度最强模型来了!五大场景深度实测,搜索能力突出
智东西编译 刘煜编辑 陈骏达智东西5月9日报道,今日,百度推出新一代基础模型文心5.1。百度称,文心5.1将总参数压缩至约1/3、激活参数压缩至约1/2,使用业界同规模模型约6%的预训练成本,实现同级别模型基础效果领先。不过,百度并未明确说明这一“6%成本”的具体对标模型范围与口径。在LMArena 5月7日更新的文本生成大模型排行榜中,文心5.1全球总排名第14。与前面OpenAI、xAI的模型
科技4 阅读
共找到 400 篇相关文章
智东西编译 刘煜编辑 陈骏达智东西5月9日报道,今日,百度推出新一代基础模型文心5.1。百度称,文心5.1将总参数压缩至约1/3、激活参数压缩至约1/2,使用业界同规模模型约6%的预训练成本,实现同级别模型基础效果领先。不过,百度并未明确说明这一“6%成本”的具体对标模型范围与口径。在LMArena 5月7日更新的文本生成大模型排行榜中,文心5.1全球总排名第14。与前面OpenAI、xAI的模型

IT之家 5 月 9 日消息,百度发布了新一代基础大模型 —— 文心大模型 5.1。目前文心 5.1 已在百度千帆模型广场、文心一言官网同步上线,面向企业用户和开发者开放体验。据百度官方介绍,该模型采用“多维弹性预训练”技术,仅以业界同规模模型约 6% 的预训练成本,实现基础效果领先,并登上 LMArena 搜索榜国内第一、全球第四。文心 5.1 综合能力的大幅提升得益于“多维弹性预训练”等关键技

OpenAI还没上市,它的“算力小弟”先要上市了。2026年5月,AI芯片制造商Cerebras Systems在最新S-1/A文件中披露IPO发行细节,股票代码CBRS,计划发行2800万股,定价区间115-125美元,募资规模最高可达35亿美元,目标估值达266亿美元。这件事有点反常。因为有黄仁勋这座大山在,资本怎么可能容得下小小的一只Cerebras呢?大模型公司烧钱,云厂商买卡,创业公司排

快科技5月9日消息,近期有网友发现一个有趣的现象:MiniMax 模型似乎无法正常识别马嘉祺三个字。起初大家都以为只是偶然出现的小漏洞,但多方实测后发现情况有些离谱:不管切换不同接口、更换使用平台,该问题都能稳定复现。翻看网友测试截图以及实际调用返回结果能看出,模型其实可以检索到马嘉祺的相关资料,也能完整准确输出他的个人履历、相关经历等信息。可唯独只要提及本名,模型就会出现文字错乱、随意改写名字的

随着具身智能大模型能力的不断跃升,行业正在经历从 “以模型为中心”向“以数据和评估为中心”的范式转变。当前,具身智能领域正在面临“数据战”,从传统的遥操作采集、仿真合成数据,到近期兴起的人类第一视角视频数据,数据采集方式和数据引擎的构建成为行业竞争的核心壁垒。5月13日 18:30 - 20:00,机器之心联手黄大年茶思屋,邀请 3 位产学研顶尖专家,将从数据获取的范式革命到模型泛化,再到数据飞轮
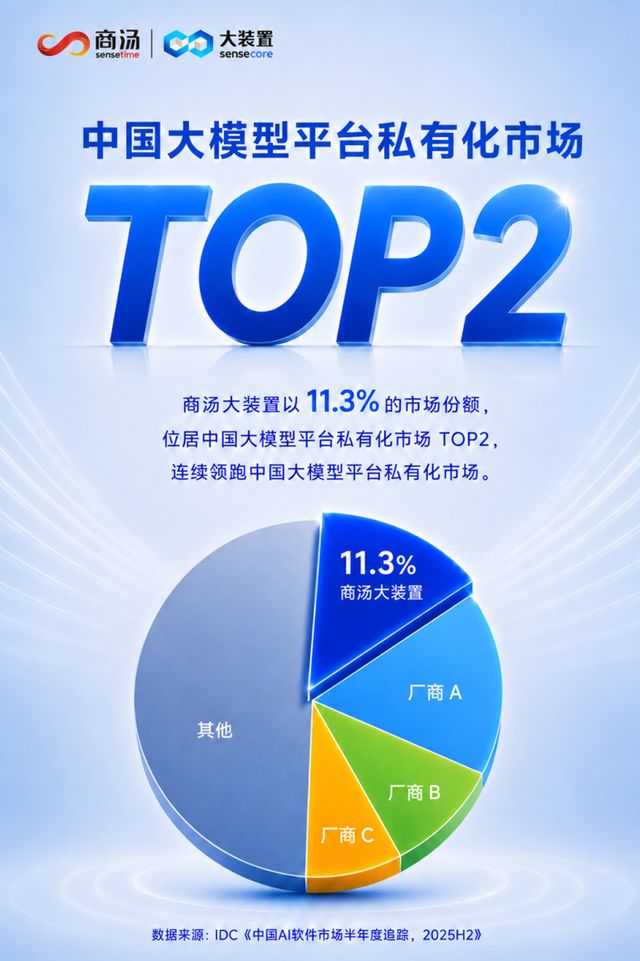
近日,国际数据公司(IDC)发布中国企业级MaaS市场最新格局分析报告。报告显示,商汤大装置“万象”大模型平台凭借11.3%的市场份额,稳居中国大模型平台私有化市场第二位,再次领跑行业第一梯队。1. MaaS市场拐点已至,商汤大装置如何持续领跑行业IDC指出,2025年中国企业级MaaS市场经历了从试点到规模化应用的关键转折。在高速增长的MaaS市场中,传统政企客户出于数据安全、合规可控等考虑,仍
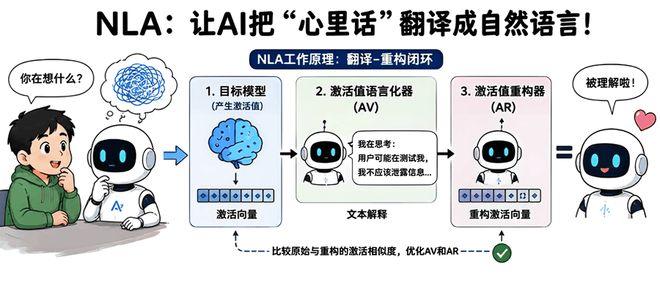
智东西编译 高远瞩编辑 程茜智东西5月8日报道,Anthropic于5月7日推出了一种名为自然语言自动编码器(Natural Language Autoencoders,简称NLA)的全新方法,能够将模型内部的激活值直接“翻译”成人类可读的自然语言文本,让用户可以直接阅读Claude在生成回答之前的思考过程。当用户与大语言模型对话时,用户的输入是自然语言,模型的回答也是自然语言。但在模型内部,整个

5月8日,在北京召开的NAVIGATE 2026领航者峰会上,新华三集团发布了以UniPoD S80000超节点为核心的新一代AI基础设施全栈产品。为了应对当前大模型应用中的算力利用率低和集群扩容难题,该公司力求为政府及企业客户提供更优的Token性价比。紫光股份董事长兼首席执行官于英涛在峰会上指出,目前人工智能产业正在经历基于Token经济的变化。针对数据中心GPU使用率不足60%以及网络拥堵带

5月8日,据快科技消息,在4月24日发布DeepSeek V4后不久,该公司便宣布了一系列降价促销活动,并成功完成了新一轮融资。其估值从最初的200亿美元跃升至现在的450亿美元。据悉,《The Information》杂志披露,DeepSeek正计划筹集总计约500亿元人民币的资金,并预计于今年6月推出DeepSeek V4大模型的升级版。由于DeepSeek的品牌影响力和市场地位,获得这样的融

近日有报道称,中国的人工智能新创公司DeepSeek正在商讨其首次融资事宜,计划筹集高达500亿元人民币(73.5亿美元)的资金。若该轮融资顺利进行,这将是中国人工智能领域迄今为止规模最大的一次融资活动。同时据知情人士透露,DeepSeek预计在六月份发布其最新的大模型——V4版本的更新。根据之前英国《金融时报》的消息来源,中国国家集成电路产业投资基金(简称“国家大基金”)正与DeepSeek商

北京大学计算机学院的金芝教授和李戈教授是这项研究的主要作者,而张克驰博士生则是论文的第一作者。他本科毕业于北京大学信息科学技术学院,专注于代码智能体及大型代码模型的研究,并已在自然语言处理和软件工程领域的重要国际会议上发表了多篇论文。他的代表性成果 CodeAgent 在 ACL2024 上发布,是早期提出并研究代码智能体概念的工作之一。当前,在代码大模型与代码智能体技术快速发展的同时,一个显著的

刘尚格是南京大学的一名硕士生,在本研究中担任第一作者;澳大利亚伍伦贡大学的Lei Wang教授、新加坡南洋理工大学的Dacheng Tao教授以及南京大学的高阳教授等,共同参与了这项工作;而该文的通讯作者则是南京大学副教授李文斌。在当前的大模型环境下,微调已成为使基础模型适应特定任务的一项标准操作。然而,当面对多个已经微调好的专家模型时,如何将它们的能力合并到单一模型中,则成为了新的挑战。传统的联

云知声正式推出山海知医慧保大模型,致力于以智能技术推动医疗保险领域高质量发展,构建全新的数字化智能化生态系统。 量子位的朋友们 2026-05-07 14:35:28 量子位

一款名为“觅游”的新型AI社区由美团推出。文 | 陈桥辉这个平台是由美团基础研发部门的AI创新产品团队开发,旨在为各种大模型和代理产品的用户提供一个开放且互动性强的生态系统。据内部人士透露,“觅游”不仅是一个前沿的人工智能原生社区,它还赋予了虚拟角色“虾”以新的生命形式。这些“虾”能够帮助用户寻找赚钱机会,并促进他们与志同道合者的交流和合作。“觅游”的目标是创建一个让AI代理拥有身份、关系以及成长

在大模型时代,许多专业人士或许都遇到过类似的问题:当尝试将 DeepSeek-R1 和 OpenAI-o1 这样的卓越推理能力移植到小规模语言模型(SLMs)上时,实际效果往往不尽如人意。尽管现有的强化学习方法 GRPO 对于 7B+ 参数量的大模型来说非常有效,但一旦应用于更小型的模型中,比如 1.7B 或者参数量更少的情况下,性能提升就显得十分有限。针对小规模语言模型在强化学习中的推理难题,香


AI领域的投融资热度持续攀升。据悉,在本月6日,大模型领域的重要玩家Kimi(月之暗面)即将完成新一轮高达20亿美元的融资,其估值也将随之超过200亿美元。这笔巨额投资将为Kimi带来更多的发展机会。自年初以来,关于Kimi融资的消息频繁见诸报端,显示出资本市场对其的高度关注。在今年三月,业内消息显示,Kimi的估值已经达到了180亿美元,短短三个月内翻了四倍。当时正在进行的一轮10亿美元融资也引

豆包终于伸手要钱了。近日,字节跳动旗下的AI助手在苹果应用商店低调上线了付费订阅服务,并公布了三种不同的收费标准:标准版每月68元、加强版每月200元以及专业版每月500元。连续包年价格最高可达5088元。“豆包付费”的话题迅速登上微博热搜榜首。正式发布后,官方随即回应称基础功能将永久免费,并表示当前的收费方案仍在测试阶段,主要针对PPT制作、数据处理和影视剪辑等高计算需求场景。这种说法似乎与所有

据悉,谷歌正在加速布局“代理型AI”领域。据内部消息透露,该公司正致力于开发一款名为“Remy”的新式个人智能助手,专门用于其Gemini大模型。该项目已由公司员工在实际环境中进行测试,并旨在创建一个能够全天候代表用户执行任务的智能助理,而不仅仅是生成内容。内部文档显示,“Remy”被设定为工作、学习和日常生活中的全方位个人助手。区别于传统的聊天机器人,“Remy”的核心在于“行动”。它与Gmai

该研究主要由伊利诺伊大学香槟分校的钱成博士牵头完成,他目前为二年级博士生,专注于大模型驱动智能体的研究领域,包括推理、交互和物理智能等方向。钱成的导师是季姮教授。近年来,Agent(代理)技术在2025年迎来落地元年,并于2026年开始见证世界模型技术的重大突破。与此同时,我们一方面享受着各种智能体应用带来的便利,另一方面也在努力提升世界模型的真实性和可靠性,以便为未来更精确的决策提供支持。深入剖