
北京大学计算机学院的金芝教授和李戈教授是这项研究的主要作者,而张克驰博士生则是论文的第一作者。他本科毕业于北京大学信息科学技术学院,专注于代码智能体及大型代码模型的研究,并已在自然语言处理和软件工程领域的重要国际会议上发表了多篇论文。他的代表性成果 CodeAgent 在 ACL2024 上发布,是早期提出并研究代码智能体概念的工作之一。
当前,在代码大模型与代码智能体技术快速发展的同时,一个显著的问题逐渐显现:尽管一些模型在经典代码生成基准测试中表现出色,但在真实软件工程环境中却显得力不从心。
这种表现差异的根本原因在于,现实中的软件开发并非孤立的编程任务,而是一个需要长期上下文理解、反复验证和不断修正的过程性挑战。
模型不仅需具备编写代码的能力,还需要能够准确解读需求信息,在仓库中定位文件位置,在恰当的时间利用工具,并根据反馈进行解释与调整错误,甚至在必要时停止操作。
因此,尽管某些模型在评测基准测试中的表现令人印象深刻,但它们的训练和评估体系往往侧重于单一任务代码生成,而不是复杂的真实世界软件工程应用场景。
为应对这一挑战,北京大学金芝教授和李戈教授团队提出了一种名为 SEAlign 的软件工程智能体对齐框架。该框架通过识别并优化轨迹中的关键决策点,显著提高了模型在真实环境中解决问题的能力。实验结果表明,使用 SEAlign 优化后的开源模型,在 SWE-bench 和其他实际场景中均表现出色。

ICSE(国际软件工程会议)是软件工程领域的重要学术活动之一,并被中国计算机学会列为A类推荐的国际学术会议。本年度ICSE共收到了来自全球各地1469篇论文投稿,最终有321篇获得接受,其中仅有22篇被评为杰出论文。

- 论文题目: SEAlign: 对软件工程代理进行训练对齐
- 相关研究发表在了 ICSE 2026 的会议中,并荣获 ACM SIGSOFT Distinguished Paper Award(杰出论文奖)。
当前模型难以适应真实世界中的软件开发环境是一个亟待解决的问题。
现有的代码模型训练主要集中在编程竞赛和算法题的生成上,这些任务通常目标明确、上下文简单,并且依赖较少。相比之下,实际软件工程则需要在复杂仓库环境中持续决策。
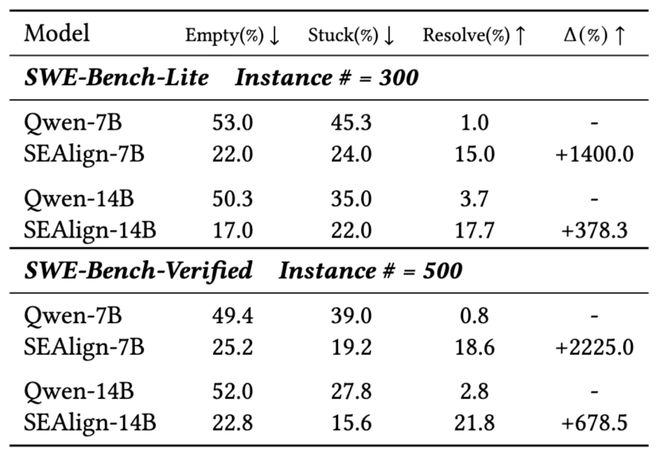
通过实验数据可以看出,即使是在 Benchmark 任务中表现出色的 Qwen2.5-Coder-Instruct-14B 模型,在配合 OpenHands 框架后,仍然难以有效解决 SWE-Bench-Verified 中的实际问题。这表明现有训练方式主要教会了模型“如何编写代码”,而没有充分训练其“如何驱动软件工程智能体”。
论文进一步分析了实验中的失败原因,并将其归结为三类行为失误。
一种是未能准确遵循指令:即使模型能够写出看似合理的代码,但如果不能理解真正的问题需求,则无法解决问题。
另一种则是错误地使用工具:包括选择不合适的工具、输入非法参数或查看无关文件等行为。
还有一种情况是重复循环操作:如果模型未能根据反馈更新其决策过程,它可能会陷入无效的迭代之中。
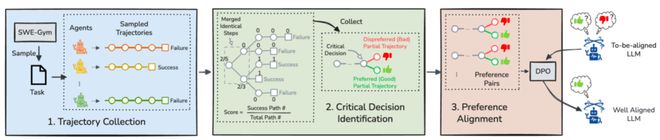
SEAlign 的目标在于优化智能体在关键步骤中的表现。
该框架的核心理念在于识别并改善那些决定成功的关键节点。与以往代码对齐方法不同的是,SEAlign 更关注于模型是否会在关键时刻做出合理决策而非仅仅生成正确代码。
SEAlign 方法设计的独特之处在于它将软件工程能力建模为一种关键点决策过程,并采用近似控制论的方法来优化这些节点,从而提升了模型在复杂任务中的适应性与稳定性。
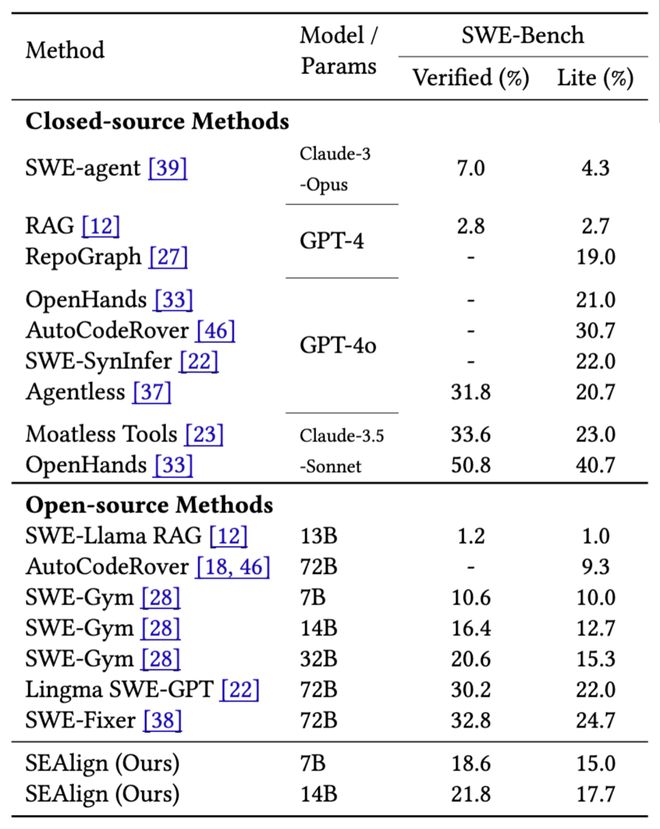
实验结果显示,在 SWE-Bench 系列测试中,SEAlign 展现出了显著的改进效果。即使使用少量数据训练,它也能让开源模型表现出色,并且部分指标接近商业闭源模型的表现。
例如,在 Qwen2.5-Coder-Instruct-14B 模型上的 SWE-Bench-Lite 测试中,SEAlign 将问题解决率从原来的3.7%提升到了17.7%,而在 SWE-Bench-Verified 上则由原先的2.8%提高至了21.8%。
此外,在 HumanEvalFix 修复任务测试中,对比于基线模型的表现,SEAlign 不仅提升了通过率还降低了无效补丁的比例。这表明 SEAlign 对改进模型在工具辅助及多步骤交互场景中的行为过程具有显著效果。
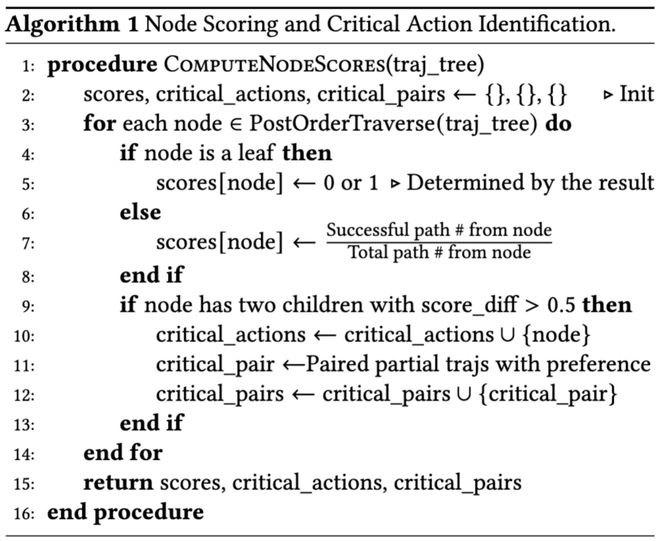
论文的消融实验也进一步证明了关键动作识别的重要性。
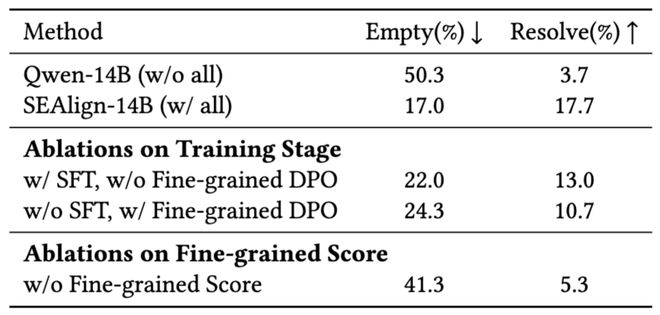
实验显示,如果只进行 SFT 而不执行细粒度 DPO,则解决率仅为13.0%;若仅执行 DPO 则降至10.7%,而采用完整方案则能达到17.7%。
该实验还表明,如果不做关键动作识别直接对齐整个轨迹,则效果会显著下降至5.3%。
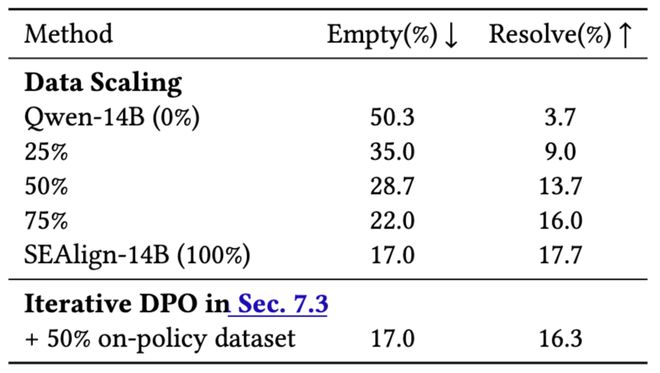
同时随着训练数据量的增加,模型的表现也在稳步提升。从仅使用25%的数据到100%,SWE-Bench-Lite 上的问题解决率由最初的3.7%提高到了17.7%。
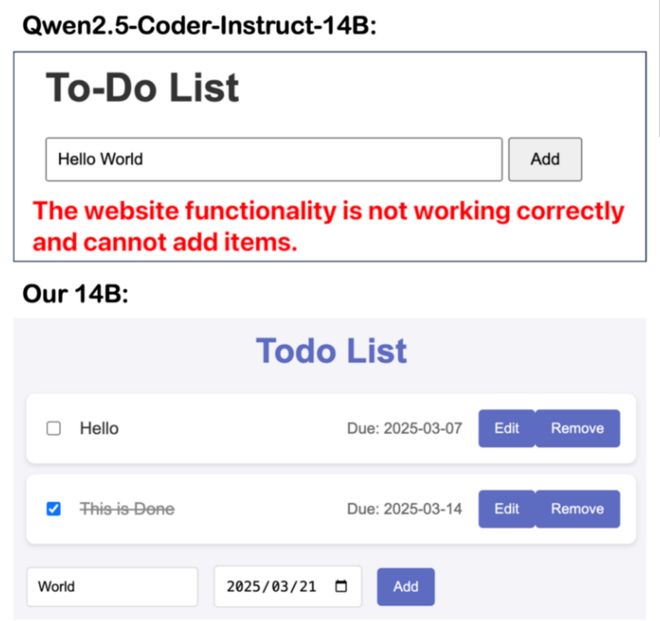
此外,在实际用户体验测试中,SEAlign-14B 相较于原始 Qwen-14B 模型也有显著提升。在五项简单的应用开发任务上,功能完整性、代码质量和美观度评分均有较大改善。
实验结果
总的来说,SEAlign 证明了模型在真实世界软件工程中的核心能力不仅仅在于编写高质量代码,更在于如何在复杂的开发流程中做出正确的决策。
围绕轨迹对齐、工具使用和关键阶段控制等策略进行优化,SEAlign 对于智能体模型走向实用化有着重要意义。它为提升代码模型的稳定性和泛化性能提供了有效途径。
这些方法不仅有助于推动代码智能体技术的进步,也为未来构建更加智能化且高效的软件开发环境奠定了坚实基础。
为了验证 SEAlign 学到的不是对某一个类 Benchmark 的过拟合,论文进一步在 HumanEvalFix 这一类程序修复任务上进行实验。
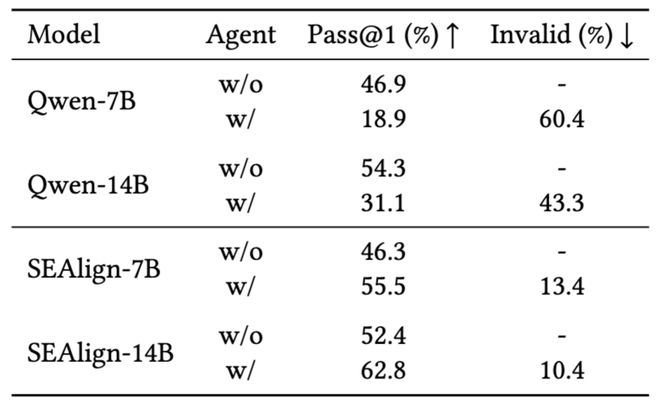
对 Qwen-2.5-Coder-Instruct-14B 而言,不使用 Agent 框架时代码修复通过率(Pass@1)为54.3%,一旦放入 Agent 工作流中,反而掉到31.1%,说明它虽然会直接写代码,却并不擅长在工具交互流程中行动。
相反,SEAlign-14B 在无 Agent 时的通过率为52.4%,加入 Agent 后则提升到62.8%,同时无效补丁率( invalid patch rate )降到10.4%。
这表明 SEAlign 的收益并不只体现在 SWE-Bench 这种复杂仓库任务上,也确实提高了模型在工具辅助、多步交互场景下的稳定性与泛化能力。
消融实验
论文的消融实验进一步说明,SEAlign 的关键在于其对细粒度关键动作优化本身。
- 只做 SFT 不做细粒度 DPO:SWE-Bench-Lite 上的解决率为13.0%;
- 只做 DPO 不做 SFT:解决率降至10.7%;完整方案则达到17.7%;
- 更关键的是,如果去掉关键动作识别,直接把整条成功轨迹和失败轨迹拿去做偏好优化,效果会明显退化到5.3%。
数据规模实验也显示出较清晰的趋势:随着训练数据从 25% 增加到 50%、75% 和 100%,SWE-Bench-Lite 上的解决率从 3.7% 稳步提升到17.7%。
从基准测试 Benchmark 到实际应用:真实用户体验评价
除了标准的智能体 Benchmark,论文还手工设计了五类简单的应用开发任务,包括 to-do list、贪吃蛇小游戏、天气应用、Hacker News 查询应用和个性化主页,并邀请 5 名有至少一年开发经验的志愿者从功能完整性、代码质量和美观度三个维度进行评分。
平均结果显示,SEAlign-14B 相比原始 Qwen-14B 都有明显提升:功能完整性从1.8提升到3.1,代码质量从2.7提升到3.5,美观度从2.0提升到3.2,SEAlign 更接近真实用户感知的开发体验改进。
未来展望
总体来看,SEAlign 揭示了一个极具现实价值的核心命题:代码模型在真实软件工程中的关键能力,不仅在于写好代码本身,更在于如何在工程流程中持续做出正确决策。
围绕轨迹对齐、工具使用、关键阶段控制与过程级的模型训练优化,SEAlign 对于代码智能体和模型的协同演进,以及保证智能体模型在长序列复杂任务上能够平稳运行都至关重要。这也为代码模型走向实用化、工程化提供了一条可行路径。