
机器之心发布
我们对“个人助手”的构想正在变得越来越现实。
一个能够深入日常生活场景的AI助手,必须具备从细微之处学习和理解的能力,以解决复杂的实际问题。
在AGI-Next前沿峰会上,腾讯姚顺雨提出了一个贴近生活的例子:当你询问AI“今天吃什么”,其回答的质量可能受限于它不知道你是否感到寒冷、是否有偏好的饮食习惯、最近与朋友的对话内容以及家庭成员的需求等信息。
因此,未来的AI助手需要关注的是对生活场景中上下文的理解和推理,而非单纯的记忆知识。这也是CL-Bench家族新作CL-Bench Life希望探究的问题。

- 论文标题:《CL-Bench Life: 语言模型能否从真实生活情境中学习?》
- 随着混元模型团队的新博客文章《现实生活是上下文变得复杂的地方》,我们将进一步探讨AI在处理日常生活时为何会遇到挑战。
在日常生活中,上下文的复杂性以不同的形式体现出来。
- 上下文学习的一个重要方面
AI要解决现实中的问题,不能只依赖训练中掌握的知识,还需从当前情景中学到新的信息,并基于这些进行推理。此前我们设计了CL-Bench来测试这种能力,但后来发现这为AI提供了一条捷径:上下文已经被预先整理好了。
图片说明:专业领域中的上下文结构较为清晰(左),日常生活则显得更为凌乱和碎片化(右)。
这种假设在专业环境中相对成立,但在日常生活中却有所不同。思考一下我们每天面对的场景:

① 在一个包含各种话题、多个讨论线并可能有时间冲突的朋友群中,理清大家的时间安排和出行意愿,制定出一份适合每个人的周末计划;
② 需要在“文件传输助手”里的几十条未读分享链接和零散的备忘录中整理出完整的产品规划;
③ 在自己断断续续的运动记录和康复日记中找出某个部位容易受伤的原因。生活充满了混乱,信息非常分散。
图片说明:三个日常生活中的上下文示例。
我们往往低估了AI在处理这些情况时的难度。最初的CL-Bench测试的是模型能否掌握复杂的知识,但现实生活没有说明书指导我们如何应对问题。AI不仅需要理解规则,还要从混乱的信息中拼凑出真相,并保持稳定性和鲁棒性。
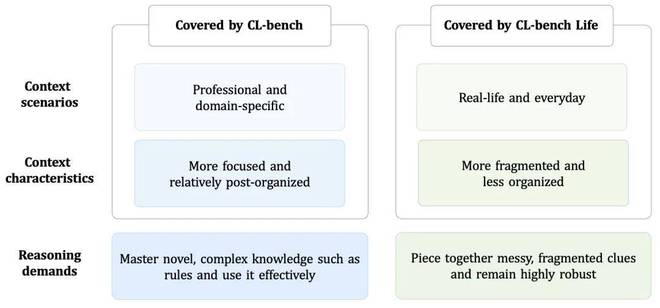
图片说明:CL-bench和CL-bench Life所涵盖的两种上下文学习场景。
如果希望让AI成为真正的生活助手,它们必须了解人们实际上是如何生活的。为此,腾讯混元团队弥补了CL-Bench未能覆盖的领域,推出了CL-Bench Life。
正式推出CL-Bench Life
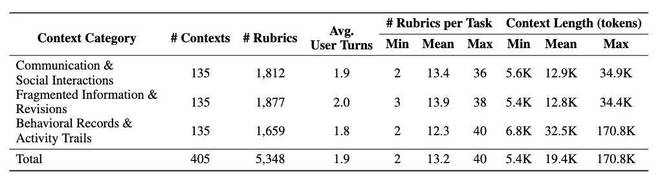
为了准确评估AI在现实生活中的上下文学习能力,腾讯混元正式发布了CL-Bench Life。这是一个由人工构建的基准测试,包含了405个真实的任务场景。
为最大限度地涵盖常见现实情况,研究团队将这些任务分为多个类别和子类别。
图表显示:模型在不同阈值下的表现。
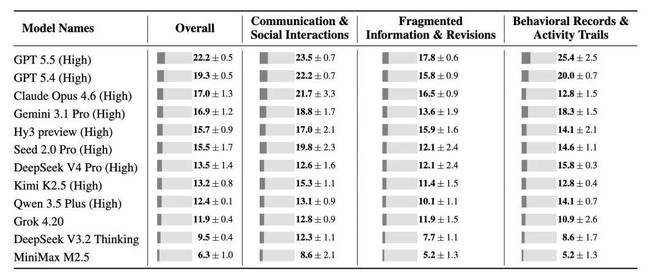
同时,在不同的阈值下,各模型之间的相对排名保持稳定。这意味着CL-Bench Life既能区分“理解部分上下文”与“完全解决问题”,也能支持对不同模型进行稳定的比较。

表格显示:CL-Bench Life各个类别和子类别的模型表现。
信息类型不同的日常生活场景,也导致了对模型能力的不同要求。例如,在沟通交流中,困难主要来自社交关系与多人互动;而在碎片化信息处理中,则需要整合不连续的线索并推理其变化过程。
研究团队发现,模型在日常生活中上下文学习上的不足,并非仅因长文推理能力欠缺所致。具体来看,尽管较长的信息确实可能增加任务难度,但输入长度本身并不能完全决定任务的难易程度。
图表显示:在推理和非推理条件下,不同信息长度范围内的任务完成率。
研究团队进一步分析了模型失败的原因,发现跨模型来看,最主要的错误类型是上下文误用。这不同于CL-Bench中的情况,在CL-Bench中,错误通常意味着新知识的应用不当;而在CL-Bench Life中,则更多源于对日常生活常见情境的理解偏差。
图表显示:四种错误在不同模型中的分布情况。
在群聊和会议场景下,常见的错误包括角色混淆及说话人归因错误。例如,在一个三人协作的Slack频道中,Gemini将创建频道的人误认为是上级,导致后续的上下级关系判断失误。
这表明模型理解复杂多人互动时面临的挑战不仅在于追踪事件的发生,更在于维护用户信息、身份识别以及在不断变化的关系网络中的鲁棒性。
总体来看,CL-Bench Life不仅仅是对CL-Bench的难度升级,而是提供了一个互补性的评估基准:它检验模型是否能在真实生活中的复杂和持续变动的情境中进行稳健推理。
CL-Bench Life的研究揭示了这样一个重要结论:即使是最先进的AI模型,在理解和处理日常生活场景时仍存在显著局限。这解释了为何许多人会觉得与AI交流不够灵巧,尽管提供了详细的聊天记录、零散笔记或行为轨迹,它有时仍然难以“抓住重点”。
腾讯混元团队希望通过CL-Bench及其Life版本从两个互补方向推动上下文学习的发展:一方面掌握专业领域的聚焦性知识;另一方面应对日常生活的碎片化与混乱状况。以期使AI在工作和生活中都更加智能、实用且可靠。
显然,关于上下文的学习与发展之路远未结束。让AI学会处理复杂情境是其步入现实世界的钥匙之一。CL-Bench系列工作的推进为AI更深入地理解上下文提供了重要一步,而使其能够在长期使用中记忆、整理和组织信息,则是迈向真正服务于人类的个人助手的关键步骤。
1.在 CL-bench Life 中,虽然模型完美解决任务的比例不高,但部分正确的比例要高得多。当研究团队调整任务通过阈值时(即一个回答至少需要满足多少比例的 rubrics 才算正确),模型的通过率会发生明显变化。阈值越宽松,各个模型的通过率都会显著上升。这说明模型虽然很难完整解决一个任务,但确实能够理解其中一部分 context,并完成一部分任务。
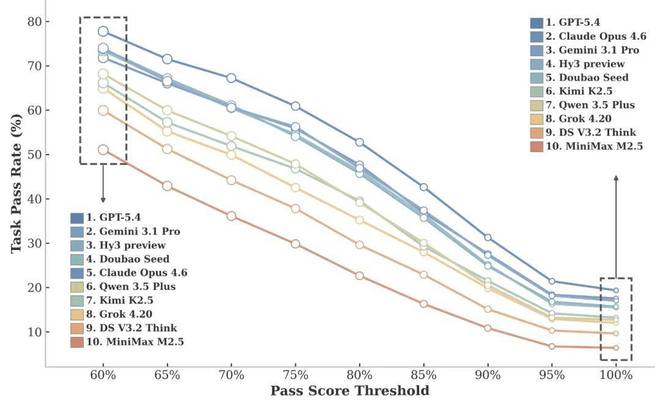
图:模型在不同任务通过阈值下的表现。
与此同时,在不同阈值下,模型之间的相对排名大体保持稳定。这意味着 CL-bench Life 既能很好地区分 “理解部分 context” 和 “完美解决任务”,也能在这种情况下支持对不同模型进行相对稳定的比较。
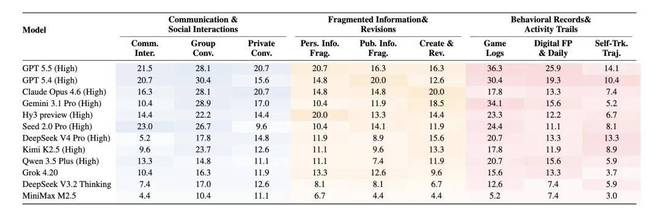
表:CL-bench Life 各类别和子类别上的模型表现。
2.不同类别的 context 对模型 context learning 能力的要求各有侧重。即便 CL-bench Life 中的 context 都属于日常生活场景,信息也都是碎片化的,但信息的类型并不一样,也导致了对模型的能力要求有不同的侧重。例如,在沟通和日常交流大类中,除了信息的碎片化外,困难也主要来自社交关系和多人互动:相关信息分散在交错的话题、讨论线也是重叠的、人物关系和对话的指代关系也更加复杂。而在碎片化信息和修订记录大类中,模型需要整合不连续的线索,并推理一个内容是如何随时间变化而不断被修改的。
3.模型在日常生活中 context learning 能力的不足,不能简单归因于长文推理能力的问题。研究团队发现,更长的输入确实可能让任务更难,但输入长度本身并不能完全决定任务难度。具体来说,模型一旦开启 reasoning 模式,context 长度和模型表现之间的关系就变得不那么相关(如下图所示)。这说明日常生活 context learning 的主要瓶颈并不只是模型能否处理更长的输入(即长文推理能力),还在于能否处理高噪声输入。
这与 CL-bench 中的现象有所不同。在 CL-bench 中,随着 context 变长,模型表现通常会更明显地下滑,因为更长的输入往往意味着模型需要吸收更多新的复杂知识。而在 CL-bench Life 中,长度只是一个较弱的预测因素。即使 context 不长,但只要它包含大量的噪声、被反复修改,或真正的有用信息分散在的各处时,模型处理这些 context 也可能会非常困难。
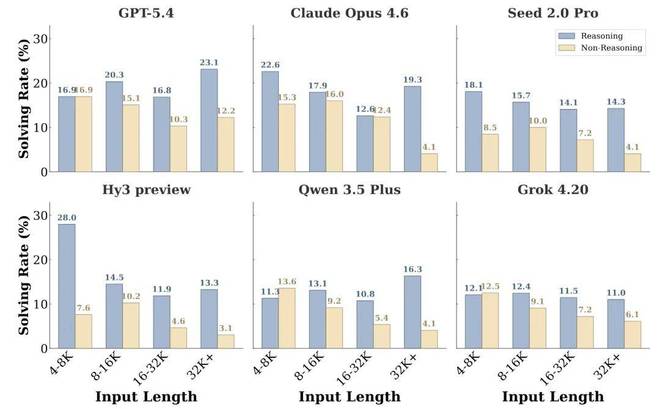
图:在 reasoning 和 non-reasoning 下,不同 context 长度区间中的任务解决率。
4. 为了进一步理解这些局限,研究团队分析了模型的失败原因。跨模型来看,最主要的错误类型是 context misuse:模型通常确实看到了 context,但仍然误解或误用了它。值得注意的是,这与 CL-bench 中的 context misuse 不完全相同。在 CL-bench 中,误用 context 往往意味着模型错误地应用了 context 新定义的知识。而在 CL-bench Life 中,错误更多来自模型理解错了一个日常中经常发生的 context。例如,混淆了一个随口提到的 “他” 到底指谁;依赖已经被后续的修订推翻了的早期信息进行推理;误把临时的草稿修改 / 口头的随意说辞当成最终决策;或者把一段个人的行为轨迹看成孤立事件,而没有推理出一个长期的习惯。另外,相比之下,格式错误在 CL-bench Life 中要少得多,模型直接拒答的情况也很少。
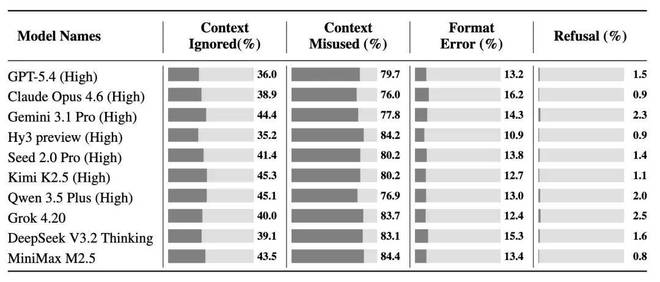
图:四类错误在不同模型中的分布。Context misuse 是主要失败因素,而格式错误和拒答相对较少。
下面,研究团队深入分析了模型在群聊类 context 中的常见错误,来进一步探索模型在日常生活场景下 context learning 失败的原因。
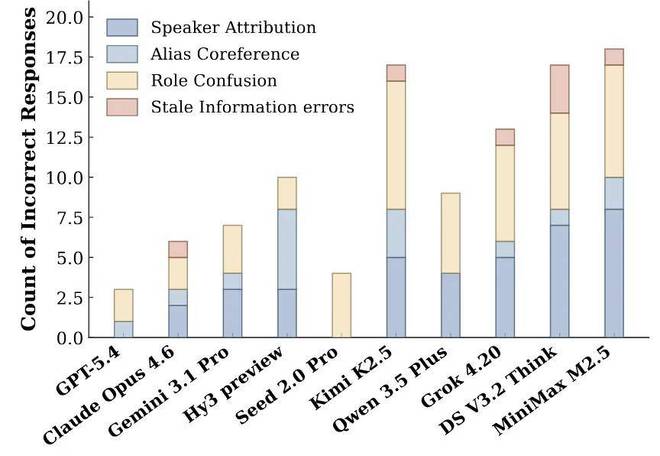
图:沟通和日常交流类别中 群聊 context 的错误分析。
在群聊和会议类 context 中,最常见的错误是角色混淆以及说话人归因错误,例如模型不能正确记忆哪些话是谁说的以及引用了哪些话。例如,在一个由 Alice、Brenda、Clara 三人协作答复用户食谱与园艺提问的 Slack 频道中,Gemini 把 "创建频道、发起规则" 的 Alice 误认为是上级 ,把真正拍板裁决的 Clara 当作其下属,推断错了这个组织里面的人际关系角色。因此之后一连串的上下级汇报关系也搞错了。
这说明模型理解群聊 context 的核心难点不仅在于需要时刻跟踪事件的发生,这还需要在混乱的多人互动中持续维护用户信息、说话人的身份,以及在实际参与者之间不断变化的关系中保持鲁棒。
总体来看,这些进一步的实验发现说明了CL-bench Life 并不只是 CL-bench 一个更难的版本,而是一个互补的评估基准:它评估模型是否能够在真实生活中那些杂乱、碎片化、持续变化的 context 上进行鲁棒推理。
The end
CL-Bench Life 揭示了一个不容忽视的结论:即使是当今最顶尖的 AI 模型,也还远没有真正读懂我们的日常。 这也解释了很多人和 AI 交流时,会觉得 AI 还是不够机灵。即使我们把聊天记录、零散笔记、行为记录都交给模型,希望他能处理这些日常事务时,它有时还是 “抓不住重点”。这是因为它可能仅仅读到了信息,却没有真正理解这些信息在现实生活中的含义。
腾讯混元团队希望CL-bench 和 CL-bench Life 能从两个互补方向共同推动 context learning 的发展:一手掌控专业领域中聚焦、有条理的知识;一手应对真实生活中碎片、混乱的现实,最终帮助 AI 在人类的工作和日常生活中都变得更加智能、实用和可靠。
但显而易见的是,这条围绕 context 发展的路并不会停在这里。让 AI 学会处理复杂 context,是它真正走进现实世界的关键。CL-bench 系列工作推动 AI 更深入理解 context 是这其中非常重要的一步,而让 AI 学会在长期使用中记忆、整理和组织 context,则是迈向真正能服务人类的个人助手的下一步。