
机器之心编辑部
今日的人工智能领域热闹非凡,先是 OpenAI 推出了备受瞩目的 GPT5.5,紧接着 DeepSeek v4 也如约而至。
在这波庆祝热潮中,Anthropic 发布了一份郑重的声明,虽然没有推出新产品,但内容同样引人注目:关于 Claude Code 的性能问题确实存在,但这背后有其缘由……
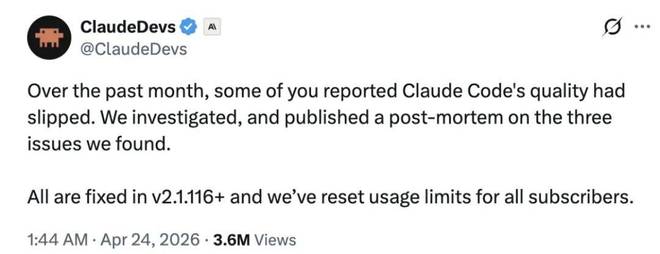
过去一个月里,部分用户反馈了 Claude Code 质量下降的问题。经过调查后,Anthropic 发布了一份详细的复盘报告,并总结了三个主要发现。
故事的开端要追溯到今年三月,当时一些网友在 Hacker News 和 Reddit 等平台上表达了对 Claude Code 性能下滑的不满。
随着讨论热度上升,Anthropic 的工程负责人 Boris Cherny 在 GitHub 上回应了网友们的疑问,解释说他们只做了界面层面的调整,并不影响模型的核心功能或性能。
尽管如此,用户们依然不买账。原因很简单:尽管官方给出了答复,但问题依旧存在,这让大家感到不满和困惑……
直到今天,Anthropic 官方终于做出了正式回应。
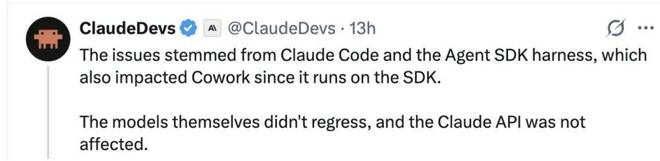
根据他们的解释,这些问题源于 Claude Code 和 Agent SDK 的运行框架(Harness),而 Cowork 也基于同样的 SDK 运行,因此同样受到了影响。「模型本身并没有退化,Claude API 则未受影响。」
关于「发现的三个问题」,具体内容如下:
- 其一,推理努力度调整失败。
在三月初,Anthropic 将 Claude Code 的默认推理强度从「high」调至「medium」,以减少用户在高强度模式下遇到的延迟问题。然而这一改动被证明是个错误。
直到四月初,在收到更多用户的反馈后,他们撤回了上述调整,并恢复了原来的状态。但不幸的是,这次变更影响到了 Sonnet 4.6 和 Opus 4.6 版本。
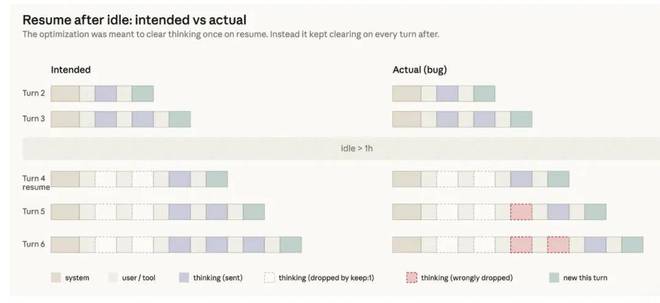
- 其二,缓存机制中出现了一个 Bug。
在三月尾声时,Anthropic 进行了一项改动以优化会话闲置期间的清理逻辑。然而这一改动却意外地触发了一个 Bug,导致每次对话都会清除之前的「思考」内容,让模型看起来像是「健忘且重复」。
问题被发现后,他们于四月修复了该漏洞,但同样影响到了 Sonnet 4.6 和 Opus 4.6 版本。
四月中旬,Anthropic 在系统提示词中加入了一条「降低冗长度」的指令:
- 三是系统提示词变更
「限制回复长度:在工具调用间,文本不应超过25个单词;除非任务要求更多细节,否则最终回答应控制在不超过100个单词。」
然而与其他提示词改动叠加后,这一调整反而降低了代码任务的表现,限制了模型处理复杂任务的深度,导致编码质量下降。
于是,在四月底时,Anthropic 撤回了上述变更,但问题再次影响到了 Sonnet 4.6、Opus 4.6 及 Opus 4.7 版本。
这一系列变动分别在不同时间点进行,并作用于不同的用户群体,最终导致了广泛且不一致的性能下降现象。
因此,在最初的调查中,Anthropic 难以将这些问题与正常的用户体验波动区分开来。同时内部使用情况和测试也无法及时复现这些问题,从而未能提前发现并解决这些困扰用户的状况。
为了表示歉意,截至四月底,所有订阅用户都将重置他们的使用限额。
此外,为了避免未来再次出现类似问题,Anthropic 宣布将采取一系列改进措施:
确保更多员工直接使用与外部用户相同的公共版本,并且改进内部使用的代码审查工具;同时,在进行系统提示词更改时实施更严格的控制和测试流程;
- 针对可能影响模型性能的变更,引入更长的观察期以及更精细的灰度发布策略。
- 总体而言,Anthropic 的这次回应显得较为诚恳。他们是否能够通过这些措施解决当前的问题,并赢得用户的信任?这值得我们关注和讨论!
- 对于可能影响模型智能水平的变更,将引入更长的观察期和更细致的灰度发布,以便更早发现问题。
不得不说,难得看到「高傲」的 Anthropic 如此正视自己的问题,看来大家的「吐槽」还是有效果的。
那么你呢,觉得此次 Anthropic 的态度如何,给出的理由是否有说服力?欢迎大家留言、交流!
https://x.com/bcherny/status/2047375800945783056
https://news.ycombinator.com/item?id=47878905
https://www.anthropic.com/engineering/april-23-postmortem