

混元新模型能否助腾讯后来居上?
作者|刘杨楠
近期发布的混元系列最新版本——Hy3 Preview,标志着腾讯在AI领域的重大突破。
在这次更新中,混元系列的性能和用户体验有了显著提升。尤其是代码生成与智能体应用方面,性价比极高。
Hy3 Preview不仅具备高效的任务处理能力,还通过快慢思考融合技术实现了自动调节模型深度的功能,无需用户手动切换版本。
这一设计灵感源自姚顺雨在OpenAI的工作经验,他主导开发了Operator和Deep Research项目。这两个项目的共同点在于强调真实世界的任务往往是混合型的,需要快速响应的同时还要进行复杂推理。
从技术架构上看,Hy3 Preview摒弃了Think版与Instruct版独立策略的传统做法,转而采用单一模型内的快慢思考融合机制,大幅提升了用户体验的一致性和效率。
同时,在成本控制上也做出了突破。通过优化推理框架、算子性能以及量化算法等手段,Hy3 Preview的整体推理效率提高了40%,显著降低了使用成本。
除了技术上的革新外,Hy3 Preview在应用场景的定位上也有新的变化。它更专注于代码开发和智能体应用这两个方向。
这一战略选择与姚顺雨过去的研究路径紧密相关。他曾在博士期间提出思维树框架以改进决策模型,并在此基础上构建了CoALA模块化认知架构,后来又主导提出了ReAct方法——这是全球首个将推理-行动结合的智能体范式系统。
这些学术成果的核心问题意识始终围绕着如何通过增强推理能力来提升模型的泛化效果和实用价值。姚顺雨认为:“智能体在企业级应用领域的潜力巨大,随着预训练规模的增长以及真实任务的不断优化,其带来的商业价值也会随之增加。”
他强调,在构建底层Agent能力的基础上,才能进一步释放应用层的价值。
然而,面对市场上众多强劲对手如DeepSeek、Qwen和字节豆包等公司,腾讯能否继续保持“后发制胜”的传统?
深度寻求极致性价比的品牌形象,开源路线的Qwen则拥有广泛的社区支持;背靠抖音流量增长迅速的字节豆包也在快速崛起。
腾讯的最大竞争优势在于其庞大的微信用户基础。姚顺雨提出模型迭代需接受真实世界的检验,并且认为微信可以提供这样一个环境——它具备海量的真实场景和即时反馈机制。

图片
但在一段时间内的被动跟随中,腾讯已经落后于竞争对手一个身位。
开源生态系统建设滞后是其中之一。DeepSeek通过完全开源吸引了大量开发者,而Qwen则凭借Apache 2.0协议赢得了社区的广泛认可。相比之下,腾讯混元在这一方面的表现显得较为保守,未能充分吸引外部贡献者参与其中。
另一个问题是缺乏明确的技术特色和品牌形象,难以建立用户心智认知优势。例如DeepSeek以“性价比之王”著称;Kimi则凭借长文本处理能力脱颖而出。
在技术透明度及学术影响力方面也存在差距。DeepSeek与Qwen团队频繁发布高质量研究报告,并活跃于各大顶级会议中发表演讲,相比之下腾讯混元的技术披露相对封闭化,尚未形成显著的网络效应或社区认同感。
视频
总体而言,要想在AI领域延续“后发制胜”的传统策略,腾讯需要通过不断改进和完善其模型能力来建立真正的竞争壁垒。Hy3 Preview的推出标志着腾讯开始主动探索差异化路径而非盲目追随行业参数竞赛趋势。
视频
然而这一切变革几乎都依赖于姚顺雨个人及其团队的努力推动,能否与公司原有业务体系有效结合并实现商业转化还需经过时间考验。
对于这位肩负着千亿级互联网巨头AI未来重任的年轻领导者来说,如何平衡创新理念与现有资源之间的关系,并迅速将其转化为实际成果,无疑将是对腾讯执行力的一次重大挑战。这段经历是否会为公司带来不同于以往的结果?我们拭目以待。
下面是Hy3 Preview的输出结果(部分):
AI算力方向CPU子品类深度调研报告 ——全球供需格局、国产替代与未来展望 报告日期:2026年4月23日 分析师:资深行业分析师 报告类型:深度行业研究
执行摘要(Executive Summary) 核心结论 1.全球CPU供应出现严重短缺:2026年Q1,Intel和AMD企业级CPU交付周期延长至6个月(Intel)和8-10周(AMD),价格累计上涨10-20%,AI基础设施需求爆发是主要驱动力。
2.x86架构面临多重挑战:NVIDIA Vera Rubin CPU的推出、ARM架构在云数据中心的快速渗透、国产CPU的崛起,共同冲击传统x86服务器市场。
3.国产替代加速:华为鲲鹏在中国服务器市场份额已达20%,中国移动2026年集采ARM服务器占比65%,创历史纪录。
4.CSP自研成主流趋势:AWS Graviton4、Google Axion、阿里倚天710等自研ARM CPU在TCO上较x86节省18-20%,性能媲美甚至超越x86。
5.未来1-2年预测:2026-2027年CPU市场将呈现"x86守成、ARM进攻、国产突围"的三足鼎立格局,AI推理需求将成为最大增长引擎。
噢对了,对于难倒一众模型的“距离洗车店50米,是开车去还是走路去”的问题,Hy3 Preview也在1秒钟之内给到了正确而风趣的答案。
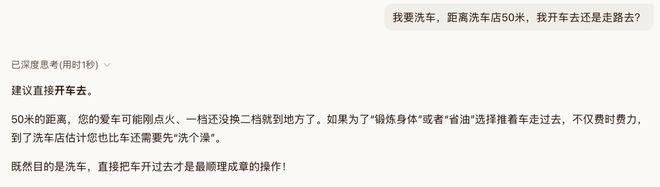
图片
要知道,这个问题DeepSeek深度思考了9秒,告诉我应该走路去。

图片
从实测的结果看,Hy3 preview的表现确实不错,而这一点在权威评测榜单中的分数也有诸多体现。
首先,上下文学习和指令遵循能力明显提升。此前,姚顺雨已经发布论文,提出CL-bench和CL-bench-Life两套评测标准来创新性地评估模型的上下文学习能力。可以看到,Hy3 preview表现明显提升。
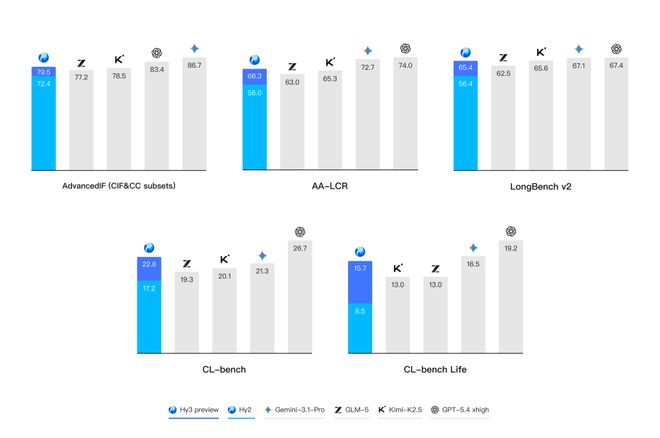
图片
在复杂推理能力方面,Hy3 preview在FrontierScience-Olympiad、IMOAnswerBench 等高难度理工科推理任务,以及最新的清华大学求真书院数学博资考(26春) 和全国中学生生物学联赛(CHSBO 2025) 中均表现良好,这也体现了其可泛化的推理能力。
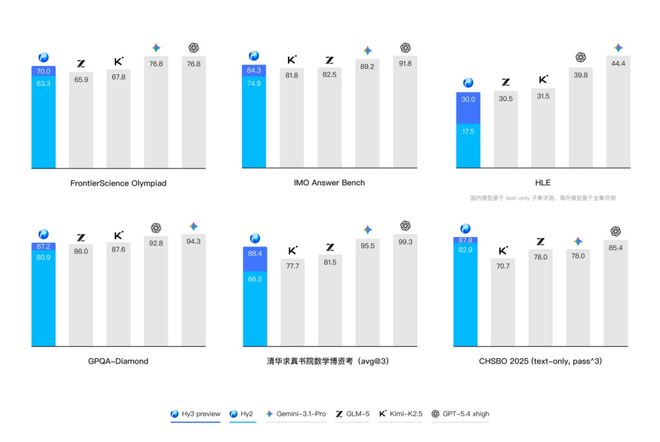
图片
在代码与智能体提升的提升则最为明显,且在此基础上表现出了较高的性价比。
通过预训练及强化学习框架的重建和强化学习任务规模的提升,腾讯混元以较快的速度在SWE-Bench Verified、Terminal-Bench 2.0等主流代码 智能体基准以及BrowseComp、WideSearch等主流搜索智能体基准中均较有竞争力。
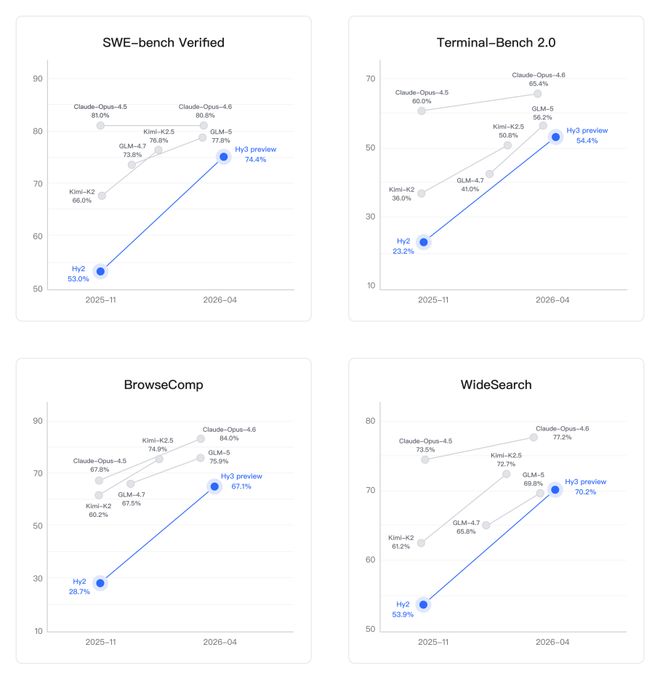
图片
同时,Hy3 preview在ClawEval和WildClawBench等评测中表现突出,表明我们的智能体能力正在稳步走向全面与实用。
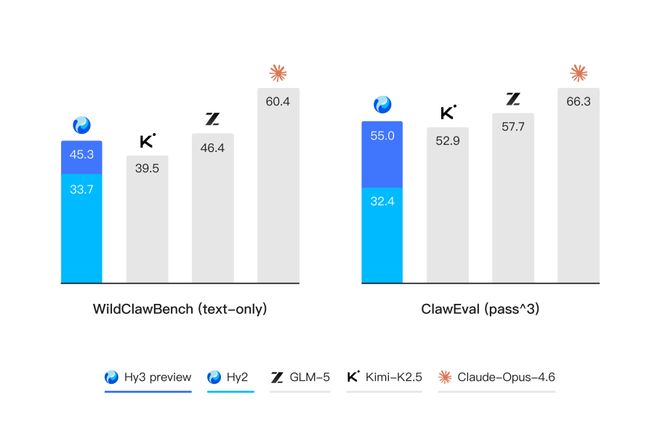
图片
除了公开榜单,腾讯混元还进一步构建了多个内部的评测集,对模型在真实开发场景中的表现进行评估。结果表明,无论是在后端工程任务集 Hy-Backend,贴近真实用户开发交互的 Hy-Vibe Bench,还是高难度软件工程开发任务集 Hy-SWE Max 上,Hy3 preview 均体现出了强竞争力。
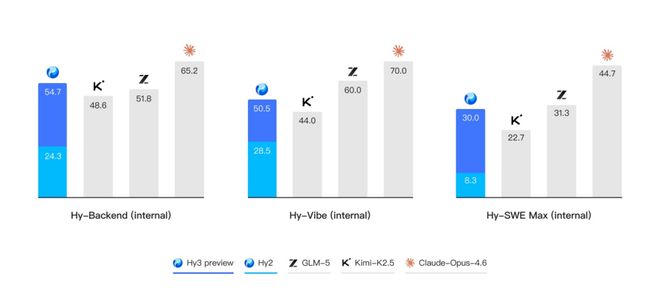
图片
比较各个开源模型的大小与智能体综合表现,Hy3 preview展现出高性价比。
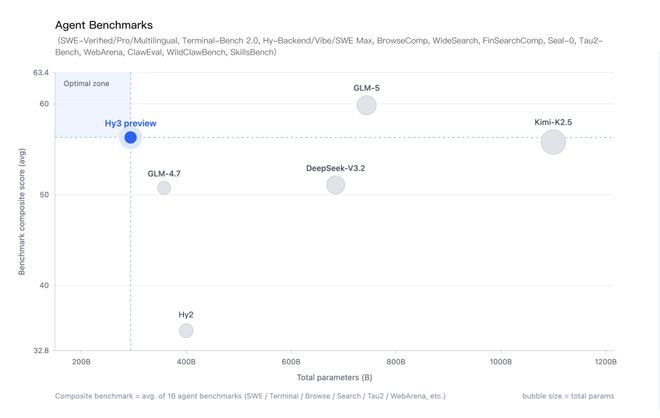
图片
可以看到,多个测评结果显示,Hy3 preview模型能力都有了全面提升。
2.姚顺雨“重造”混元
从实际的体感看,Hy3 Preview和之前的混元系列有很强的断裂感。
混元系列此前的发布思路,几乎就像这个名字一样混沌不清。混元体系看似在图像(混元图像3.0)、视频(HunyuanVideo)、3D生成方面形成了完整矩阵,但基本都在跟随行业风向,做一些不会出错的动作。就以上一代的混元2.0为例,腾讯官方仍在强调其在数学竞赛、科学推理、代码生成等Benchmark上的全面表现。
但这一次,Hy3 Preview的气质明显变化。
首先,在技术架构方面,原来的混元2.0采用Think和Instruct两个独立版本的策略。Think版针对高难度复杂推理和代码生成等进行深度优化;Instruct版则侧重于通用场景下的高效响应与指令遵循。这种设计好处是能针对不同任务“专项特调”,但代价也不容忽视:用户需要自行判断任务复杂度并手动切换模型,体验上是割裂的。
而Hy3 Preview实现了单一模型内的快慢思考融合。模型根据任务复杂度自动调节思考深度,用户无需手动切换。这个设计直接呼应了姚顺雨在OpenAI开发Operator和Deep Research时期的经验。
Operator主打对计算机系统进行通用操作,Deep Research则瞄准科研、法律、金融等知识密集型领域,二者的共同经验是:真实世界的任务往往是混合型的,既需要快速响应的简单子任务,也需要深度推理的复杂环节。将两者割裂,本质上会降低Agent的端到端效率。
在效率优化方面,Hy3 Preview总参数从混元2.0的406B降至295B,激活参数从32B降至21B,缩减幅度约27%,直接将腾讯拉出了“卷参数”的泥潭。
2026年1月10日,姚顺雨官宣加入腾讯后首次公开演讲时明确指出:“单纯的模型参数竞赛已不是C端产品的全部”,AI下半场的关键不在于谁拥有最多参数,而在于谁拥有最多“Context”(上下文)。
此外,Hy3.0 Preview的上下文利用效率也有所提升。姚顺雨加入腾讯后的首篇论文关注的正是“从上下文学习”的困难。
研究团队构建的CL-bench测试显示,即便把解题所需的全部信息都喂给模型,全球最强的模型任务解决率也仅有23.7%。这篇论文得出的结论是:当前前沿模型在上下文利用上依然存在显著的能力短板,而上下文学习能力恰恰是影响模型在真实世界任务完成效果的核心分水岭。
在成本方面,得益于模型和推理框架上的深度协同,以及在推理框架、算子性能、量化算法等全方面优化,整体推理效率提升40%,Hy3 preview的成本相比上一代模型大幅下降。
在腾讯云大模型服务平台 TokenHub 上,Hy3 preview 输入价格最低1.2元/百万tokens,输入命中缓存价格0.4元/百万tokens,输出价格最低4元/百万tokens。同时,腾讯云联合混元推出定制的 Hy3 preview Token Plan 套餐,个人版定价最低28元/月,为Agent开发和打造“龙虾”应用的提供更具性价比选择。
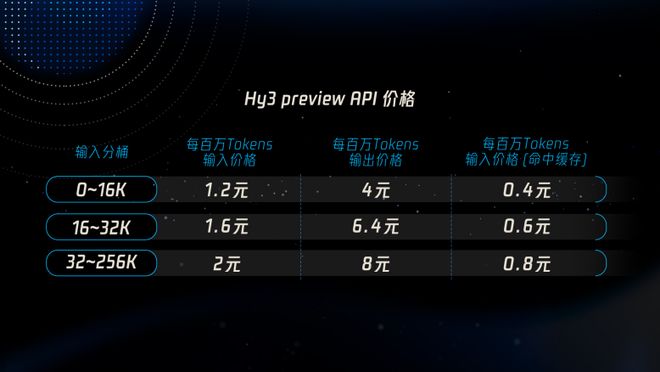
图片
在目标场景上,Hy3 Preview的优势场景被明确收敛到两个方向:Coding和智能体应用。
这个方向和姚顺雨此前的研究路径一脉相承。他在博士期间提出了思维树(Tree of Thoughts)框架改进决策模型,随后构建了CoALA模块化认知架构,在OpenAI期间又主导提出了ReAct方法——首次将“推理-行动”结合的智能体范式系统化,目前已成为全球构建语言智能体的主流方法。
从ReAct到CoALA再到Tree of Thoughts,这条学术脉络的核心问题意识始终如一,就是通过增强推理能力,让模型有更好的泛化效果,同时打造一款能在真实场景发挥实际作用的Agent。
姚顺雨曾对Agent的发展颇有信心,他认为:“智能体在To B方向的发展呈一条不断上升的曲线,且看起来没有变慢的趋势。只要预训练不断地变大,后训练不断地把这些真实世界的任务给做好,它就会带来越来越大的价值。”
姚顺雨的逻辑很清晰:先把底层模型的Agent能力做实,应用层的价值释放才有根基。
3.腾讯还能延续“后发制胜”的传统吗?
在中国互联网江湖,腾讯有一个著名的“后发制胜”策略。他们不喜在风口最热时入场,总是等市场教育完成、模式验证清晰后再大举投入,借助资源和服务能力后来居上。
但在AI时代,腾讯还能延续这一传统吗?
要回答这个问题,首先要看当前同样强调“实用性和高性价比”的主要玩家:DeepSeek凭借极致的性价比建立了强品牌认知;Qwen坚持开源路线,提供丰富的模型尺寸、成为开源社区宠儿;字节豆包则背靠抖音流量快速增长。
在这个竞争格局中,腾讯的差异化路径是什么?
腾讯最大的差异化优势,恐怕就在于拥有微信(14亿用户)这个超级入口。姚顺雨在内部明确提出:“模型迭代需要真实世界的约束和评估。”而微信恰好提供了这个“真实世界”——海量用户、复杂场景、即时反馈。只是,腾讯此前似乎一直没考虑好怎么用将微信和AI融合。
在被动跟随的时间里,腾讯已经在一些维度落后对手一个身位。
首先是开源生态建设滞后。 DeepSeek通过完全开源建立了强大的开发者生态;Qwen通过Apache 2.0协议和丰富的模型尺寸选择成为开源社区宠儿。相比之下,腾讯混元的开源策略较为保守,社区参与度不足,尚未形成明显的网络效应。
其次,并未形成明确的技术特色,很难占领牢固的用户心智。 在AI助手领域,DeepSeek凭借“性价比之王”建立了强品牌认知,Kimi凭借长文本特色出圈,豆包背靠抖音流量快速增长。腾讯元宝虽然接入混元,但用户心智尚未稳固,“混元”品牌在开发者中的认知度弱于DeepSeek和Qwen。
技术透明度和学术影响力不足。 DeepSeek和Qwen团队持续发布高质量技术报告,在顶会上有活跃发声。腾讯混元的技术发布相对封闭,学术影响力有限。姚顺雨虽然个人学术声誉卓著,但多大程度上能转化为腾讯整个技术团队的凝聚力和工作效率,仍然需要时间验证。
总体上看,腾讯能否在AI时代延续“后发制胜”的传统,取决于它能否通过在模型能力的追赶,建立起真正的竞争壁垒。Hy3 Preview的发布,是腾讯AI战略的一次重要转折。它标志着腾讯不再盲目追随行业的参数竞赛,而是开始主动探索差异化路径。
只是,这一切技术或战略转变,几乎都以姚顺雨为支点撬动的。姚顺雨带来了全新的理念,但这些技术理念能否和腾讯原有业务体系结合,完成商业转化,仍需要时间验证,也考验着腾讯的执行效率。
一个千亿互联网巨头的AI重担,再一次压在了一位年轻的、有明确技术理想的、充满锋芒的掌舵者肩上。这个故事似曾相识,但它会在腾讯长出不同的结局吗?
(封面图
