
新智元报道
最近,DeepSeek-V4的技术报告引起了广泛关注,其直率的披露令人惊叹不已。V4发布的延迟背后隐藏着何种秘密?研究人员对此纷纷猜测,并对论文中详细描述Agent操作的方式表示认可。
昨日堪称人工智能界的年度盛会。
技术报告长达近六十页,详尽地展示了从架构设计到训练过程的每一个细节。
与V2至V3仅耗时不足八个月相比,此次V4的研发周期竟达484天。这其中的原因究竟是什么?
对这份报告进行了深入研究后,我们发现了潜在的因素,并深入了解了这家被誉为“国产之光”的企业所具备的卓越工程技术。
DeepSeek-V4令人深思之处,在于其在Agent训练、工程基础以及处理训练震荡时表现出的高度透明性和理性精神,而不仅仅是堆砌算力资源。
今天,我们将深入剖析V4的核心技术细节,探索其中隐藏的秘密。
包含33T Tokens和万亿参数的模型
难度直接拉满
自从V3发布以来已经过去了整整484天,V4才以“预览版”的形式面世。
虽然论文中没有直接解释这一时间跨度的原因,但其中一段内容或许可以提供一些线索。

V3使用了大约14.8T tokens进行预训练,而V4则翻了一番,达到了32T和33T。参数量也随之显著增加,V4-Pro的总参数量为1.6万亿,而V4-Flash也拥有约2840亿。
数据量和参数规模的倍增使得训练过程面临前所未有的挑战。
报告中明确指出,“训练稳定性挑战”是一个不可忽视的问题。
谷歌DeepMind的研究员Susan Zhang对此赞赏不已,认为这种透明的做法值得称赞。这一观点也得到了“龙虾之父”的转发。
当参数量和数据规模达到某个临界点时,在大规模集群上进行训练会放大硬件的微小误差。
在这篇技术报告中,“stability”这个词反复出现十余次,这本身就表明了问题的重要性。
具体而言,DeepSeek发现MoE层中的数值异常值会在路由机制的作用下不断放大,并最终导致损失函数突然飙升。
对于这一挑战,团队提出了两种解决方案。
首先是预见性路由策略(Anticipatory Routing),它通过使用较早版本的参数来解耦骨干网络和路由网络之间的更新过程。
第二种是SwiGLU限制机制(SwiGLU Clamping),直接将数值范围限制在[-10, 10]以内,从源头上压制异常值,效果显著但略显粗暴。
当前大模型的训练已经进入了一个硬件底层、编译器栈和数学架构三位一体的新领域

报告中有一个细节非常引人深思。
DeepSeek确认“预见性路由”和“SwiGLU限制机制”的有效性,但同时指出其背后的工作原理仍需进一步研究。
即便像Q/KV归一化这样的常用操作,在论文中的描述也只是说可能有助于提高训练稳定性。
这个“may”字充分体现了在处理万亿参数的模型时,任何方法都无法保证百分之百的成功率。
数据量翻倍带来的挑战不仅是困难增加的问题,更是系统性风险的成倍上升。

每一层网络、每一次梯度更新以及每次通信同步都可能成为潜在崩溃点,在更大规模下被放大。
DeepSeek选择将其全部写入论文中,这在业内几乎前所未见。
训练稳定性挑战的背后究竟是哪家硬件平台的问题?
尽管论文没有明确指名道姓,但已有敏锐的观察者开始进行猜测。
有人认为,“训练稳定性挑战”很可能源于算力平台本身的问题。这并非仅限于DeepSeek一家公司面临的情况。
xAI的一次发布会上,Macrohard项目的负责人暗示英伟达最新芯片带来的问题迫使他们重新编写硬件适配程序。这可能是xAI进度放缓的一个原因。
然而,实际情况远比表面复杂得多。
大型算力集群涉及诸多变量:从硬件本身到互连架构、散热系统及电力供应等各方面因素都可能影响训练过程的稳定性。
DeepSeek在此次报告中展示了其如何通过一系列硬核工程技术,在数十万个沙箱环境中逐步磨炼出Agent的能力,体现了该公司对大模型向AGI发展的独特路径探索。
从Multi-head Latent Attention到OPD蒸馏及DSec沙箱的创新应用,DeepSeek正以近乎偏执的态度追求卓越工程能力,并以此为基础构建未来AI发展蓝图。
尽管V4并非完美无缺,但其真实性和活力无疑代表了目前中国人工智能领域最激动人心的一面。
一切都还在猜测之中。

Agent训练体系
工程能力让人肃然起敬
如果说V4的预训练是在和硬件博弈,那么它的Post-training则展现了教科书级别的工程审美。
可以说,Agent能力的工程化路径,是V4论文里最值得细读的部分。
以往我们认为Agent能力是「教」出来的,但DeepSeek认为,Agent能力应该是「长」出来的。

拒绝「硬迁移」,预训练阶段的「血脉注入」
行业内大部分的做法是,先训一个对话模型,再硬迁移成Agent。DeepSeek看来,这太低效了。
在V4的mid-training阶段,他们就注入了海量的Agentic Data。
这意味着,模型在基础学习阶段,就已经见过长任务链、环境反馈和文件修改模式。它还没学会写诗,就已经见过了Linux命令行的报错。
这就是一种地基层面的设计。
独创的Specialist Training(专家特训法)
另一大亮点,就是DeepSeek独创的专家特训法。
V4没有直接练一个全能战士,而是先练出了数学专家、代码专家、Agent专家、指令跟随专家。
这种分阶段的Specialist Training保证了每个领域的上限被拉到最高。
最后,再通过OPD(Multi-teacher On-Policy Distillation,多教师在线策略蒸馏),将这些专家的灵魂聚合成一个统一的模型。
这里工程上的难度在于,同时加载十多个万亿参数级的教师模型做在线推理不现实。
V4的方案是不缓存教师的logits(显存装不下),只缓存教师最后一层的隐藏状态,训练时按需通过prediction head重建logits。
然后,按教师索引排序训练样本,确保每个教师的prediction head只加载一次。KL散度计算则用TileLang编写的专用kernel加速。
告别传统Reward Model
另外,对于「难以验证(hard-to-verify)」的任务,传统的标量奖励模型(Scalar Reward Model)已经力不从心。
对此,DeepSeek选择引入了Generative Reward Model (GRM)。
它不再简单地给一个0到1的分数,而是根据预设的Rubric(评估准则)生成详细的评估报告。
更关键的是,DeepSeek对GRM本身也做了RL优化,让actor网络同时充当生成式奖励模型,评判能力和生成能力在同一个模型中联合优化。
把Agent做成一套分布式系统
不仅如此,DeepSeek还为V4专门自研了一套底座。
DSec:生产级沙箱集群
为了训练Agent的实操能力,DeepSeek搭建了一个名为DSec的平台。
3FS分布式文件系统,确保了数据的极速存取;数十万并发Sandbox实例,则意味着V4在训练时,同时有几十万台「虚拟电脑」在跑代码、测Bug。
MegaMoE:通信计算一体化
在MoE层,DeepSeek把通信和计算融合进单个pipeline kernel,专家按wave调度,通信延迟完全隐藏在计算之下。
结果就是,通用场景加速1.5到1.73倍,RL rollout等延迟敏感场景最高1.96倍。
自研DSML:拒绝转义失败
工具调用方面,DeepSeek干脆自己设计了一套类似XML的DSL(领域特定语言)。
这套协议简单高效,直接把工具调用的成功率从「看运气」提升到了「工业级稳健」。

Reasoning Effort分模式训练
还有一个精细的设计,就是V4支持不同的思考模式。
Non-think模式是简单的工具选择,秒回。High/Max则针对长文档、重构、复杂Bug,拉满推理算力。
这种「能省则省,该狠则狠」的策略,也是V4成本能做到Claude 1/4的关键。
社区的很多研究者读完这部分后,膜拜得五体投地:「DeepSeek的工程能力,依旧扎实得让人没话说」。

Interleaved Thinking升级
V3.2在每个新用户消息到来时会丢弃之前的思考痕迹,V4在Tool-Calling场景下保留了完整的跨轮次推理历史,让Agent在长时程任务中维持连贯的推理链。
普通对话场景仍每轮清空,保持上下文精简。
硬币的另一面,是94%的幻觉率
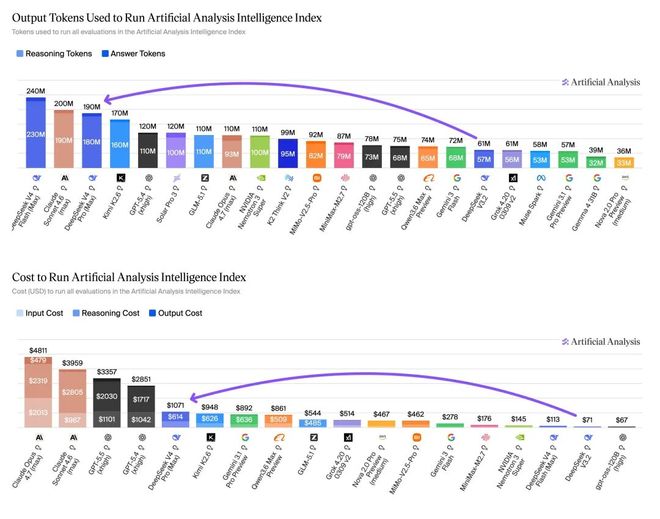
Artificial Analysis的实测给出了一个更立体的画面。
跑完Intelligence Index的全量基准测试,V4 Pro只花了1071美金,比Claude Opus 4.7的4811美金便宜了四倍多。
Agent能力方面,V4 Pro Max在GDPval-AA实测(面向真实工作任务的Agent基准)中拿到了1554分,全面领先一众开源模型。
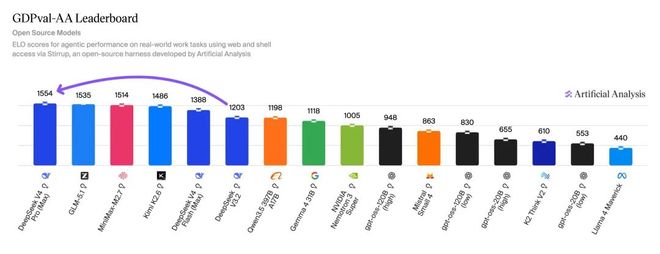
然而,天下没有免费的午餐。
Aritificial Analysis的报告里也非常坦诚地指出了这种做法的代价:V4 pro在AA-Ominiscience上的幻觉率高达94%。

这揭示了一个结构性困境:要在有限算力预算下逼近顶级性能,就不得不在某些维度上做取舍。
DeepSeek选择把筹码全压在推理和Agent能力上,代价,就是知识都准确性。
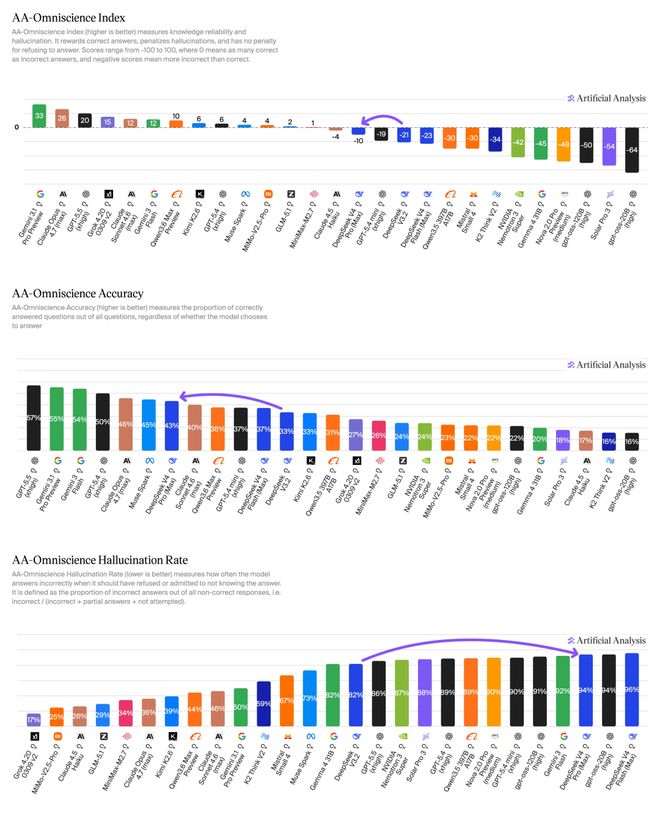
为什么我们依然对DeepSeek充满敬意?
在这次V4的报告中,有人看到了「训练不稳」的尴尬,有人看到了「幻觉严重」的短板。
但在我们看来,这份报告最动人的地方在于透明。
他们敢于承认硬件适配阵痛,敢于披露那些看似「补丁」的解决方案,更敢于展示自己如何用最硬核的工程能力,在几十万个沙箱里一点点磨出Agent的灵魂。
从V3的Multi-head Latent Attention到V4的OPD蒸馏和DSec沙箱,DeepSeek正在用一种近乎偏执的「工程主义」,探索着大模型通往AGI的另一条路径——
如果架构还不够完善,那就通过工程技术来弥补;如果算力不够充裕,则需依靠算法提升效率。
虽然V4可能还不是最完美的解决方案,但它无疑是中国AI领域中最真实、最具活力的存在。 [93]
参考资料:
https://x.com/suchenzang/status/2047559677316325807
https://x.com/ArtificialAnlys/status/2047735160544841953
https://x.com/jakevin7/status/2047578619946664413