DeepSeek V4刚上线时,在海外媒体界引起了不同反响,有人关注其性能表现,也有人聚焦于价格因素,更有评论提到华为的参与。
彭博社认为DeepSeek V4是向OpenAI和Anthropic发起的强大挑战,《财富》则特别指出V4将价格压到了非常低的位置;路透社注意到的是V4不仅具备成本效益且擅长处理长文本,并首次明确透露了它已与华为的升腾芯片兼容。不过,路透社也提到部分顶级闭源模型仍领先于V4,而且目前还不支持多模态功能。
然而,“华为”二字使得整个讨论变得更加复杂。V4不仅引发了关于其性能优劣的讨论,还牵涉到它可能会给哪些竞争者带来压力的问题。英伟达CEO黄仁勋曾在一次播客中警告说,如果DeepSeek首先在华为平台上发布产品,这对美国来说将是灾难性的。现在看来,这句话似乎预示了V4所带来的舆论反应。
因此,这次最引人注目的不是DeepSeek V4的技术评分有所提升,而是它上线后立刻引起了美国媒体的两种截然不同的情绪反应。一方面承认中国公司正以更低的价格和更高的效率接近对手,另一方面却又不愿意完全接受硅谷靠芯片、资金和封闭生态构建起来的竞争壁垒已经开始动摇的事实。
一、极致性价比:打破硅谷的技术保护屏障
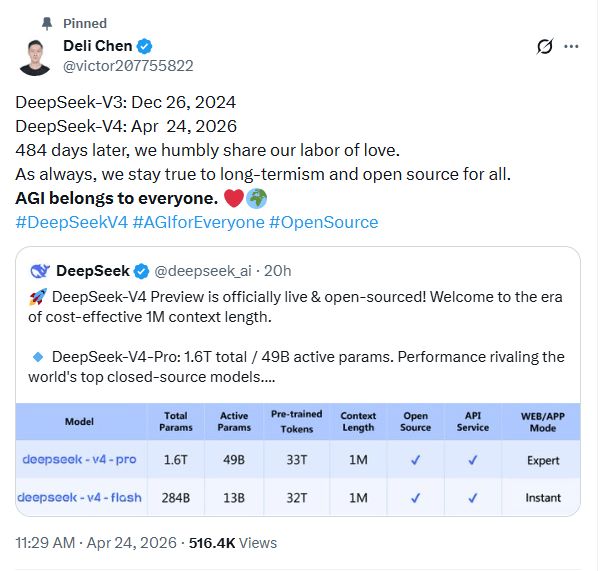
4月24日,DeepSeek V4预览版正式发布并开源,推出了V4-Pro和V4-Flash两条产品线。这两款模型都支持100万token的上下文处理能力。其中,V4-Pro在多个测评中显示了卓越的能力,尤其是在代理编程、数学及STEM等领域的表现接近顶级闭源模型;而V4-Flash则更注重经济性和高性能。价格方面,V4-Pro输入缓存命中为每百万token 1元,输出24元;V4-Flash输入缓存命中仅为0.2元每百万token,输出价为2元。
相比于前一代产品,V4的最大突破在于采用了混合注意力机制(如CSA和HCA)来降低长上下文的计算与内存成本,并非简单地增加参数数量。这些改进使得“100万上下文”成为真正的标配而非展示功能。整体来看,V4延续了其“高性价比”的风格,实现了一次面向大规模长上下文应用的基础架构级升级。
《彭博社》认为DeepSeek V4是目前最强大的开源平台之一,并对OpenAI和Anthropic构成了挑战。新模型的发布促使全球科技公司和投资者重新评估他们在人工智能领域的投资策略是否明智。

CNBC形容V4的推出为“全方位的实力展示”。尽管它可能不像R1那样具备颠覆性,但其低价竞争已让美国竞争对手感受到了巨大的压力。
《财富》则重点报道了V4的价格优势。文章指出,与OpenAI或Anthropic相比,V4-Pro的价格仅为前者的六分之一到十分之一,这种极端的性价比可能彻底打破美国领先实验室的竞争壁垒。
V4之所以能够达到如此低的价格,并非仅靠激进的商业策略,更在于DeepSeek对其底层架构进行了颠覆性的重构。
二、“技术优雅”:用算法效率对抗暴力算力
VentureBeat称赞V4为“重返战场的巨鲸”,认为其混合注意力机制和流形约束超连接(mHC)等创新极大地降低了显存需求,同时保持了高性能水平。

然而VentureBeat也指出了V4的一些限制,例如它不支持图像和视频等多种模态能力。
半岛电视台提到,尽管在数学和代码领域表现优异,但V4-Pro仍有一些不足之处,在“世界知识”等少数领域的表现还落后于谷歌的闭源模型Gemini 3.1 Pro。开源平台Hugging Face官方也对这条回归的“巨鲸”表示欢迎。
路透社援引Hugging Face机器学习工程师路易斯·坦斯托尔的话说,V4在处理长且复杂的文本任务时表现出色且价格低廉,并迅速登上了榜首的位置。
极致的效率也意味着明显的“偏科”问题。
专家们认为,目前V4仍是一个纯文本模型,在图像理解和视频生成等领域完全缺失,这在多模态已成为标配的情况下限制了其在创意产业的应用潜力。此外,DeepSeek官方承认,V4在某些领域的知识储备上还不及Gemini 3.1 Pro。
三、“主权AI”:大国博弈下的硬件突破
那么问题来了,究竟是什么芯片让DeepSeek得以打造如此高效的V4?
路透社和《纽约时报》都指出,在早期研发阶段使用过英伟达的GPU如H800或合规版H20后,到了V4的研发周期中情况发生了变化。DeepSeek明确表示,其在研发过程中进行了英伟达GPU与华为升腾(Ascend)NPU的并行验证。结合社交媒体和行业分析,V4得益于与华为最新算力集群如SuperPoD的深度协作,在FP4低精度推理等前沿技术上实现了原生支持。
这表明AI模型已经开始针对中国本土硬件进行优化。路透社敏锐地意识到DeepSeek转向华为芯片的战略意义,认为这是中国推动自主创新的重要例证。这恰巧印证了黄仁勋的担忧——“如果我们国家先于美国发布在华为平台上运行的产品,可能对美国不利。”

四、全球开发者的声音
在社交媒体上,用户们对于DeepSeek V4的表现给出了不同的评价。
技术专家MZ指出,OpenAI和Anthropic更多依赖“暴力堆砌算力”来提升模型性能,而DeepSeek则通过架构效率实现突破。他认为美国实验室在私下吸收中国公司的工程方案的同时,在公开场合却传播“中国偷窃”的言论以保护自己的封闭模型。
MZ进一步分析称,当前全球AI生态正处于一种虚伪的“纳什均衡”,即美国控制着叙事和高利润率,并利用开源成果;而中国公司则通过持续开源来确保全球开发者采用标准,从而绕过硬件封锁。
博主Lisan al Gaib认为V4处于GPT-5.2或Opus 4.5+的级别,在参数规模为1.6万亿时已经与GPT-5.4相当。他还提到,相关技术论文详细介绍了模型的训练和技术架构。
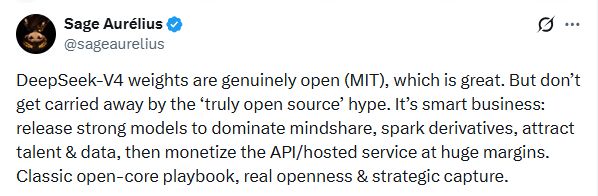
当然也有冷静的声音提醒大家不要被“纯粹开源”的热情冲昏头脑,DeepSeek采用MIT协议可能是一种商业策略。
DeepSeek研究员陈德利在X上称V4为“心血之作”,并重申了公司的愿景:“AGI属于每一个人。”
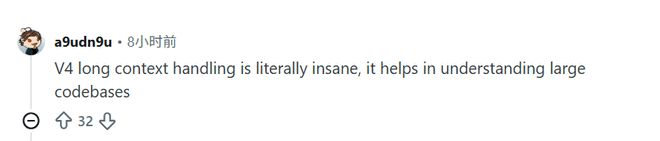
五、结语:真正的创新无惧围墙

DeepSeek V4的推出,挑战了硅谷多年来的“算力霸权”。

它向世界展示了,在通向未来的道路上,并非只有暴力堆砌计算资源这一条路径。当全球开发者都在为V4的稳定与经济性欢呼时,我们看到的是一个中国AI品牌的崛起和一场科技权力格局悄然改变的过程。

“深海巨鲸”已经浮出水面。如果AGI的未来属于每个人,那么这场打破封锁、击穿价格壁垒以及重塑效率的游戏才刚刚开始下半场。
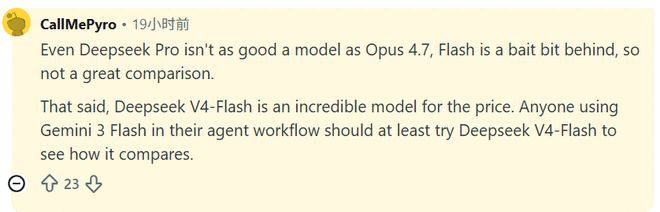
在X平台上,讨论上升到架构创新、科技权力乃至愿景的高度。
技术专家MZ(@myknz)发长文指出,美国实验室如OpenAI和Anthropic目前更偏向通过“暴力堆砌算力”(Brute-forcing)来提升模型性能,而DeepSeek则代表了通过“架构效率”(Architectural efficiency)实现突破的路线。他犀利地指出,美国实验室正“悄悄地吸收”中国公司如DeepSeek、阿里巴巴和月之暗面贡献的工程方案,但在公开场合却散布“中国偷窃”的叙事来保护自己的封闭模型。

MZ进一步分析称,全球AI生态正处于一种虚伪的“纳什均衡”,即美国控制着叙事和高利润率,并利用开源研发成果;而中国公司则通过持续开源来确保全球开发者采用中国标准,从而绕过美国的硬件封锁。
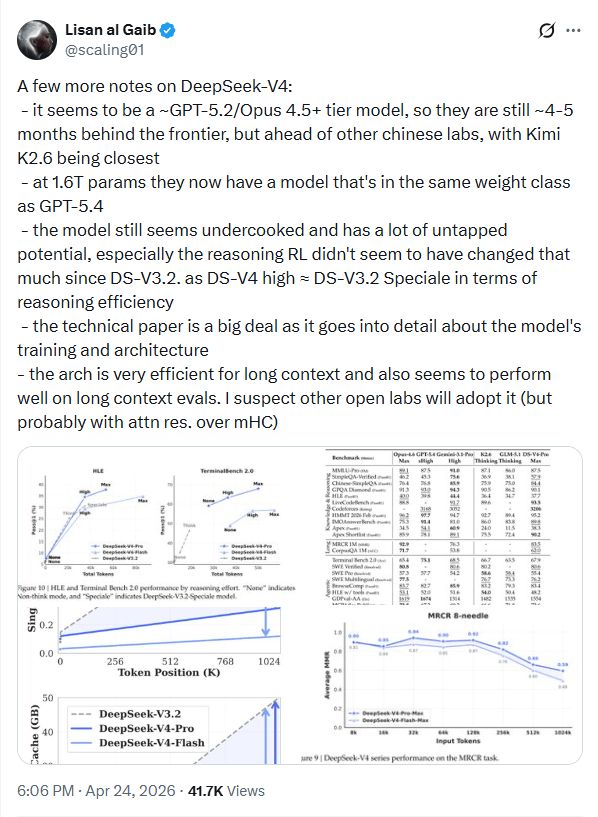
知名博主Lisan al Gaib认为V4目前处于GPT-5.2或Opus 4.5+的级别,虽然落后于顶尖闭源模型约4到5个月,但领先于其他中国AI模型,位列其次的是Kimi K2.6。在1.6万亿参数规模下,V4的重量级已经与GPT-5.4相当。他还提到,相关技术论文详细介绍了模型的训练和技术架构,推测其他开源实验室会采用这种在长上下文中表现优异的架构。
当然,冷静的审视同样不少。
AI工程师Daniel Dewhurst提醒大家要谨慎对待官方给出的Benchmark,认为在缺乏独立评估前,这些华丽的数据可能存在针对测试集的优化。Lisan al Gaib更是直言V4看起来依然“欠火候”(undercooked),在推理逻辑上相比V3.2并没有本质的飞跃。
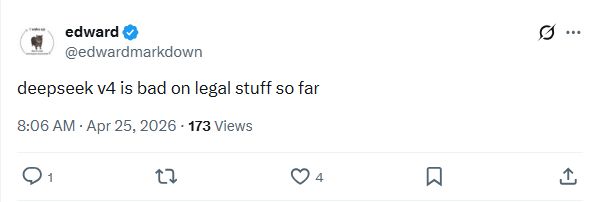
也有用户提到DeepSeek V4在法律任务上目前表现很差。
Sage Aurélius则提醒人们不要被“纯粹开源”的热情冲昏头脑。他认为DeepSeek采用MIT协议是聪明的商业策略,即通过释放强力模型抢占开发者心智和数据,再通过托管服务赚取高额利润,这是经典的“核心开源”(Open-core)模式。
而DeepSeek研究员陈德利在X上将V4称为“心血之作”,并重申了公司的愿景:“AGI属于每一个人。”
五、结语:真正创新不惧围墙
DeepSeek V4的登场,直指硅谷构建了十几年的“算力霸权”逻辑。
它告诉世界,在通往未来的道路上,暴力堆算力并非唯一的答案,架构效率同样能跑出惊人的成绩。当全球开发者都在为V4的稳定与廉价欢呼时,我们看到的不只是一个中国AI品牌的崛起,更是一场全球科技权力格局的悄然洗牌。
“深海巨鲸”已经浮出水面。如果AGI的未来注定属于每一个人,那么这场打破封锁、击穿价格、重塑效率的博弈,才刚刚进入下半场。