
该项目得到了来自华中科技大学VLRLab的郑元雷和小米大模型Plus团队的付培两位专家的贡献,而通讯作者分别是罗振波(小米大模型 Plus)及陈伟(华中科技大学 VLRLab)。
在处理多页文档的理解任务时,有一种普遍接受但较少被挑战的观点认为:为了理解长篇文档,模型应该尽可能多地「阅读」它。
但是换个角度看,人类在面对几十页的报告时,真的会一页接一页地从头读到尾吗?显然不会。人们通常先浏览目录、快速扫视标题,然后直接跳转至可能相关的部分进行仔细阅读。那么问题来了:为什么现有的文档理解模型不能效仿这种行为呢?
这正是 Doc-V* 试图回答的问题。
Doc-V* 是由小米大模型 Plus 和华中科技大学 VLRLab 的团队共同研发,它提供了一种新的多页文档理解范式,从「被动阅读」转向了「主动探索」。这种新方法通过互动式的视觉推理机制,使模型能像人类一样有策略地浏览长篇内容。
实验结果表明,这样的创新确实带来了实际的效益:在统一使用 Qwen2.5-VL 7B 模型作为基础架构的情况下,Doc-V* 在多个多页文档问答基准测试中超越了 RAG 变体模型,性能提升了49.7%,且无需依赖更大的模型或更长的历史信息。
这一发现揭示了一个道理:与其让模型处理大量页面的信息,不如教会它在适当的时候获取最需要的页面更为有效。

- 论文链接:https://arxiv.org/abs/2604.13731v1
重新审视「阅读所有内容」的做法:静态输入策略的根本矛盾
目前用于长文档处理的方法存在着一个根深蒂固的问题。
一方面,某些方法试图一次性将所有的页面信息传递给模型以确保信息完整性,但随着文档长度的增长,计算成本也随之增加,并且模型可能会遭受中间记忆丧失等负面影响。
另一方面,则是依赖于检索策略的方法,它们只选择部分页面作为输入,在效率上有所改进,但是其表现高度依赖于检索结果的准确性 —— 如果关键信息未被召回,后续推理将难以纠正偏差。
从本质上讲,这两种方法都采用了「静态输入」范式:在进行推理之前就固定了输入内容,并且缺乏在推理过程中动态调整获取信息策略的能力。
这种方式与人类处理长文档的习惯存在显著差异,也限制了模型在复杂多步推理场景中的表现。
Doc-V* 的方法设计:从「静态阅读」到「主动探索」
Doc-V* 的核心理念可以概括为一句话:不要一次性把所有内容塞给模型,而是让模型自主决定看什么以及什么时候看。
首先,Doc-V* 构建了一个全局缩略图概览。在输入阶段,并不会直接处理高分辨率页面,而会将每一页压缩成低分辨率的缩略图并按照网格形式排列。这使模型能够在较低的成本下观察文档的整体结构和布局。
这一设计的关键在于提供了一种结构性导航信号,帮助模型更有针对性地选择随后需要仔细查看的具体页面内容。
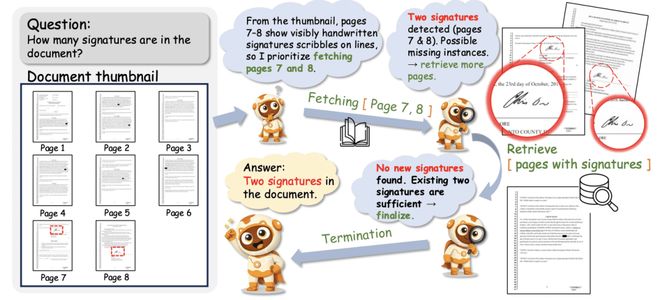
图 1:Pipeline 示意,初始输入为 Question+Document Thumbnail。模型先获得文档的全局缩略图视角,再有针对性调用工具对文档作深入的探索。
接下来是两种交互式操作:全局语义检索(粗粒度探索)及精确页面获取(细粒度证据定位)。通过这些操作,模型能够根据结构线索直接跳转至包含表格、图表或标题的特定页面进行精细分析;还可以自动补全跨页表格信息、图文分离等问题。
- 这两种机制互补地实现了从广义到具体的搜索过程:前者用于召回可能有用的区域,后者则更专注于定位具体证据。

- :精确页面获取(细粒度证据定位 ⭐)

在训练阶段,Doc-V* 采用了 SFT+GRPO 的两阶段策略来教导模型何时调用哪种操作,并如何根据现有信息进行判断。
实验结果显示 Doc-V* 在标准多页文档问答任务上表现出色。
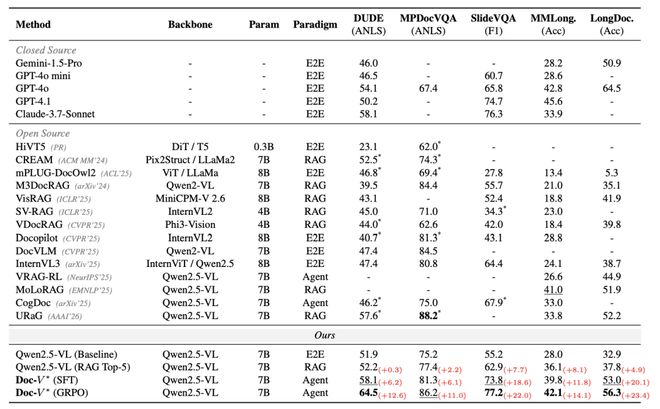
统一使用 Qwen2.5-VL 7B 模型作为基础架构时,Doc-V* 相比于基础模型及其 RAG 变体取得了稳定的性能提升。这表明基于检索的页面筛选能够在一定程度上缓解长文档中的噪声问题。
然而,这种性能改善仍受限于「静态检索」范式 —— 模型只能根据一次性召回的信息进行推理,一旦关键证据未能被包含在 Top-K 内,则后续过程缺乏自我纠正的能力。
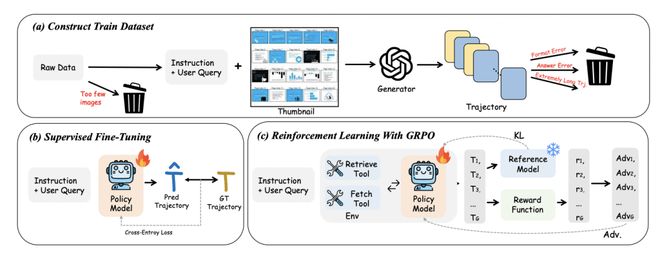
图 2:Doc-V * 的数据构造以及训练方式
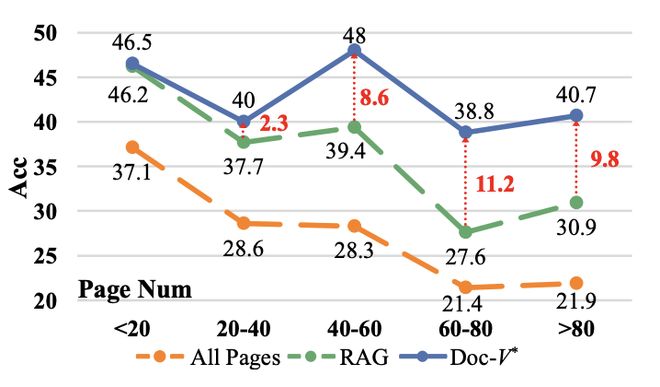
通过进一步分析不同方法的输入页面数量与性能之间的关系,可以观察到:对于基于 RAG 的方法而言,随着输入页面数量增加,其表现通常呈现出先上升后下降的趋势。这反映了在长文档场景下,“信息覆盖”和“信息干扰”的平衡点问题。
实验结果
这一现象在多个数据集上均有体现,说明它并非个别案例而是检索式方法的普遍特征。
相对而言,Doc-V* 未表现出类似的性能退化趋势。这是因为它的输入不是一次性确定下来的,而是在推理过程中逐步扩展:模型只在需要时引入新的页面,并结合已有证据进行判断,从而避免了无关信息的过度积累。
然而,这种提升仍然受限于「静态检索」范式 —— 模型只能基于一次性召回的页面完成推理,一旦关键证据未被包含在 Top-K 中,后续过程缺乏纠错能力。
此外,本文还分析了不同方法面对文档长度增加时的表现差异。无论是 RAG 还是 All Pages 方法,在处理越来越长的文档时,性能均有所下降。
这进一步说明,“提供更多信息”并不能解决问题;真正需要的是更智能的信息获取策略。
进一步分析不同方法在「输入页面数量 — 性能」之间的关系,可以观察到一个值得关注的现象:对于基于 RAG 的方法,随着输入页面数量的增加,性能通常呈现出「先提升、后下降」的趋势。
“信息获取不等于信息堆叠”,当上下文中充斥着无关信息时,模型反而更容易被“视觉显眼但无关”的页面误导,忽略真正的关键证据页。
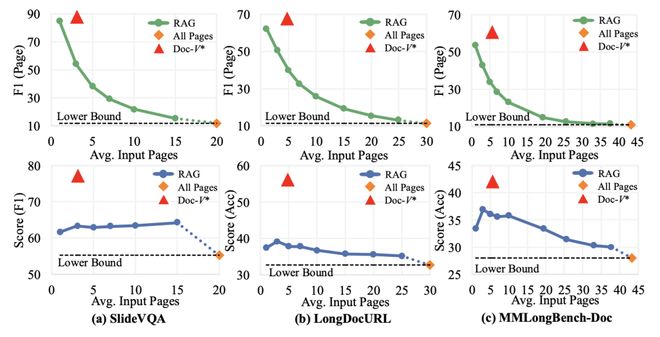
图 4:不同方法在「输入页面数量 — 性能」关系上的对比。RAG 方法存在明显的性能拐点,随着 K 的增加,性能先升后降,并趋于输入所有页面的性能,而 Doc-V * 则不受 K 的影响。
真正需要的是「策略驱动的信息获取」。Doc-V* 在此方面做了一项重要的工作:不是盲目阅读内容,而是首先判断应该去哪些地方寻找信息。
这具体表现为一个接近人类的行为过程:先浏览缩略图(评估哪些页面“看起来有用”)→ 直接跳转到最可能包含答案的页面 → 仅基于最少但最有用的信息完成回答。
其背后的转变是:“从被动接收信息”转向“主动决策信息获取路径”,从全局搜索逐步聚焦到局部确认,最终逼近问题的答案。这是人类阅读长文档时的真实行为模式。
从更广阔的视角来看:未来文档理解的发展方向
整体而言,Doc-V* 提供了一种不同于传统方法的新视角:将多页文档的理解过程转化为一个“动态证据获取与整合”的过程。
通过引入缩略图导航、交互式操作以及工作记忆机制,模型能够在其推理过程中不断修正自身判断,从而更有效地处理长篇文档中的复杂信息关系。
这种方法并不依赖于更大的模型或更长的历史上下文,而是通过更加合理的信息使用方式来提高推理效率和结果可靠性。

对于文档理解来说,真正重要的是“不在于是否一次性看完所有内容”,而在于能否像人类一样,在阅读过程中不断调整策略、主动寻找证据并逐步逼近答案。
真正需要的是「策略驱动的信息获取」,Doc-V* 在其中做了一件关键的事情 —— 不是盲目读取内容,而是「先判断去哪里看」。
具体表现为一个非常接近人类的过程:先看缩略图(判断哪些页面「看起来可能有用」)→ 直接跳转到最可能包含答案的页面 → 基于最小但最相关的信息完成答案。
这背后其实是一个核心的转变:从「被动接收信息」→「主动决策信息获取路径」,从全局搜索 → 局部确认 → 逐步逼近答案,这正是人类阅读长文档时的真实行为。
从更大的视角看:文档理解的下一步
整体来看,Doc-V* 提供了一种不同于传统方法的视角:将多页文档理解问题从「静态建模」转化为「动态证据获取与整合」的过程。
通过引入缩略图导航、交互式操作以及工作记忆机制,模型能够在推理过程中不断修正自身判断,从而更有效地处理长文档中的复杂信息关系。
这种方法并不依赖于更大的模型或更长的上下文,而是通过更合理的信息使用方式,提高推理效率与结果可靠性。
对文档理解来说,真正重要的,也许从来不是「一次性看完所有内容」,而是能不能像人一样,在阅读过程中不断调整策略、主动寻找证据、逐步逼近答案。