AI画图,又变天了。
OpenAI于4月22日凌晨推出了ChatGPT Images 2.0版本。
这次更新最令人瞩目之处在于,模型不再仅仅是根据提示生成图像,而是先进行推理、搜索和文件读取后再作画,这使得它在绘制菜单、小字海报和其他信息图时的表现更加出色。
自即日起,所有ChatGPT及Codex用户均可使用基础版本。而付费订阅的用户则能解锁包括思考模式在内的高级功能。与此同时,底层模型gpt-image-2也已通过API向公众开放。
两年前生成菜单时常出现拼写错误的情况如今已成为历史。
回想一下,在2024年使用DALL-E 3制作墨西哥餐厅的菜单时,那些错误拼写的菜名让人印象深刻。当时模型在处理图像中的文字时,只能从噪声中重建像素,无法正确拼写出特定模式的文字。

现如今,向ChatGPT Images 2.0索要同样的墨西哥菜单,生成的成品可以直接用于印刷。菜品名称不仅完全准确,排版也十分清晰,并且价格标注到位。虽然13.5美元的价格可能让人质疑食材的真实性,但至少从视觉上看不出任何破绽。
这种进步得益于底层架构的重大变革。OpenAI GPT图像生成技术研究负责人陈博远在媒体简报会上表示,新模型能够处理三维视角转换和复杂空间推理,并被称为通才型或基于文本的预训练变换器。
尽管没有具体说明所使用的技术是扩散模型还是自回归方法,但效果明显。细微的文字、图标以及用户界面元素等过去让图像生成工具难以应付的内容现在都能稳定渲染,最高支持2K分辨率。
开发者西蒙·威利森进行的一项测试揭示了新旧版本之间的显著差异。他要求两个模型分别绘制一张寻找浣熊的图片,结果发现新版模型在高画质模式下,清晰地呈现了一只坐在业余无线电摊位里的浣熊,而老版则未能找到目标。
Hyperbolic Labs联合创始人金宇宸试用后表示,新版本的效果非常出色。他认为OpenAI再次引领了图像生成领域的创新方向。
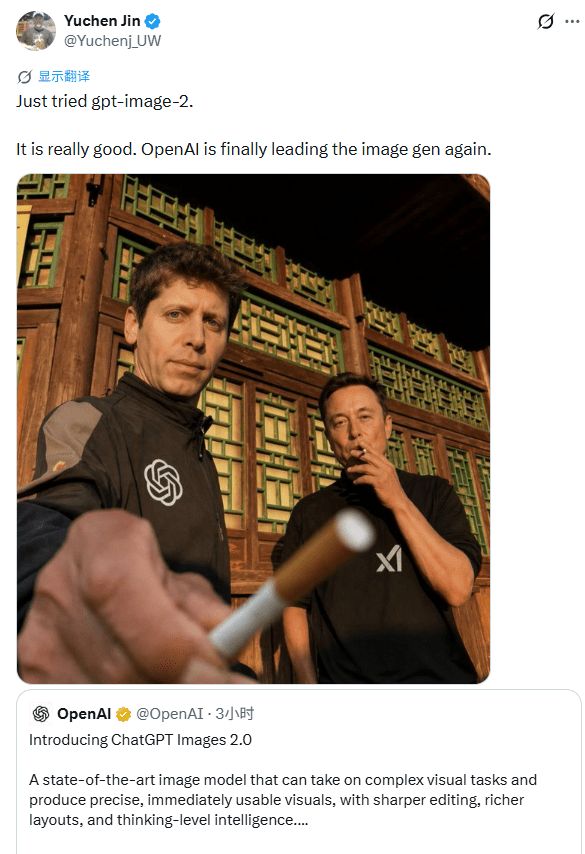
新模型的关键改进在于其思考流程的引入,这使得它能够先进行搜索和推理后再作画。
过去的图像模型更像是一个黑匣子,用户输入提示词后直接获得结果。而ChatGPT Images 2.0则在生成之前会进行详细的准备工作:搜索网络信息、分析上传文件内容,并通过推理规划图像布局,甚至还会自我检查以确保准确性。
在一次演示中,产品负责人李·艾德丽向模型展示了一份内部产品的复杂报告。模型不仅综合了文档中的核心数据,还识别出正确的标志,并生成了一张专业且风格一致的信息图。
多语言能力和更广泛的比例选项也是此次更新的重点之一。基础版ChatGPT Images 2.0面向所有用户开放,而付费订阅的高级功能则包括多图像生成和网络搜索能力等。
API用户可以通过gpt-image-2模型获取最高4K分辨率的图像输出,并且价格为每百万token30美元。
结合安全性和定价策略来看,OpenAI引入了三层权限体系并调整了费用结构。基础版对所有ChatGPT和Codex用户开放,而高级功能则针对付费订阅者提供。
新模型的成功标志着图像生成技术从简单的绘画工具转变为具有复杂推理能力的视觉系统。商业应用中的营销团队、教育工作者以及产品经理将从中受益匪浅。
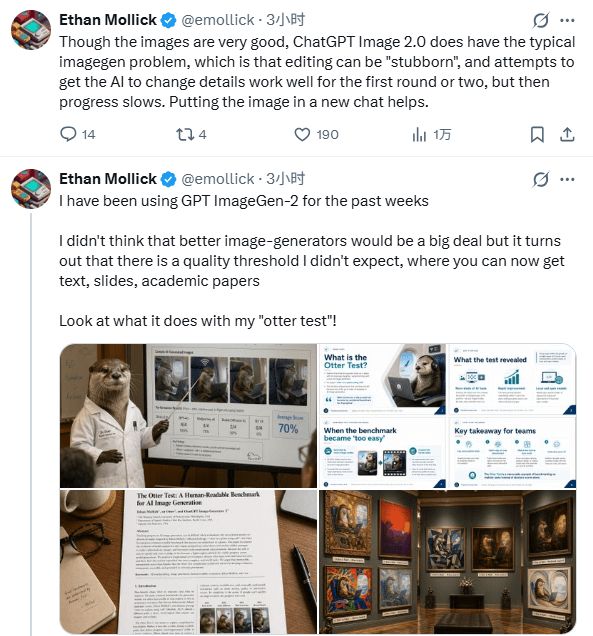
尽管ChatGPT Images 2.0在许多方面取得了显著进步,但在反复编辑时模型的顽固倾向、非英语语言文本准确性问题以及专业领域知识边界等问题仍需关注。
开发者威利森还发现了一个有趣的例子:当他要求模型在一个找不到浣熊的图片中圈出这只动物时,模型竟凭空添加了一只不存在的浣熊并加以标记。这显示了在自检任务中的可靠性和准确性仍然需要进一步验证。
总体而言,ChatGPT Images 2.0不仅提高了图像的质量和细节,还将其从简单的绘画工具提升到了一个能够理解和执行复杂任务的新阶段。
这次更新的发布标志着图像生成技术进入了一个新的竞争阶段。随着其他竞争对手如谷歌Nano Banana 2及微软MAI-Image-2等产品的相继推出,OpenAI通过ChatGPT Images 2.0强势回应了市场对更智能而非仅仅更精细的工具的需求。
在新版本中,用户不再需要学习如何与机器对话;相反,机器已经开始学会理解并执行用户的意图。这标志着从手工设计到自动化生成的巨大转变。
OpenAI联合创始人兼CEO山姆·奥特曼(Sam Altman)在社交媒体上发了一部由ChatGPT Images 2.0生成的漫画,内容是他和另一位用户寻找更多GPU的故事。

OpenAI总裁格雷格·布罗克曼(Greg Brockman)也评论说真的难以置信,你现在用一点计算资源就能造出这样的东西。他说自己对教育、专业环境比如幻灯片和营销材料,以及生产力领域比如给代码文档配图表的新应用感到极度兴奋。

04从日语菜单到印地语海报让非拉丁文字终于不用再鬼画符
OpenAI在发布说明中把ChatGPT Images 2.0的多语言文本渲染能力称为显著进步,具体点名了日语、韩语、中文、印地语和孟加拉语。在官方展示的样本中水循环教育图表的韩文标注清晰工整,字符结构完整且跟画面融合得很自然。
但样本归样本。《连线》杂志记者里斯·罗杰斯(Reece Rogers)让模型生成了一张提莫西·查拉梅(Timothée Chalamet好莱坞明星)主题的中国粉丝拼贴海报。输出画面包含超过二十处中文文本片段以及饺子、珍珠奶茶和熊猫的图像,视觉效果繁复热闹。

罗杰斯随后让聊天机器人翻译这些文字,机器人的回复倒是很诚实,它指出其中有些文本并非准确的中文句子,部分混入了日语字符,还有一些更像是模仿东亚粉丝文化风格的装饰性文字。但在网易智能看来,模型生成的中文图像在视觉完成度上已经相当能打,日常使用中完全可以接受。
这和两年前的情况形成了鲜明对比。彼时AI图像里的中文连基本的笔画结构都撑不住,一眼就能看出是机器瞎编的。现在模型不仅能正确渲染大部分常用汉字,在排版、字号搭配和画面融合上也明显更自然了。当然,如果拿着放大镜逐字检查,偶尔还是会发现个别字符不够规范,但对于海报、社交素材、信息图这类实际使用场景来说,已经跨过了"可用"的门槛。OpenAI所说的多语言"质的飞跃",在中文上或许还不算满分,但已经是一个扎实的高分。
05手外科医生的非正式评估:X光片好得吓人但解剖图还是别用
前面聊的都是创意、设计、营销场景也就是海报、菜单、漫画、社交媒体素材。这些场景对图像的容错率相对宽松,排版好看且氛围到位就算合格。但如果把模型扔进一个容错率几乎为零的领域它还扛不扛得住?
美国知名显微外科与手外科专科医疗机构The Buncke Clinic的手部医生布莱恩·普里根(Brian Pridgen)对新模型做了自己的非正式评估。他生成了一张手部X光片和一份腕管综合征信息传单。结论是喜忧参半。
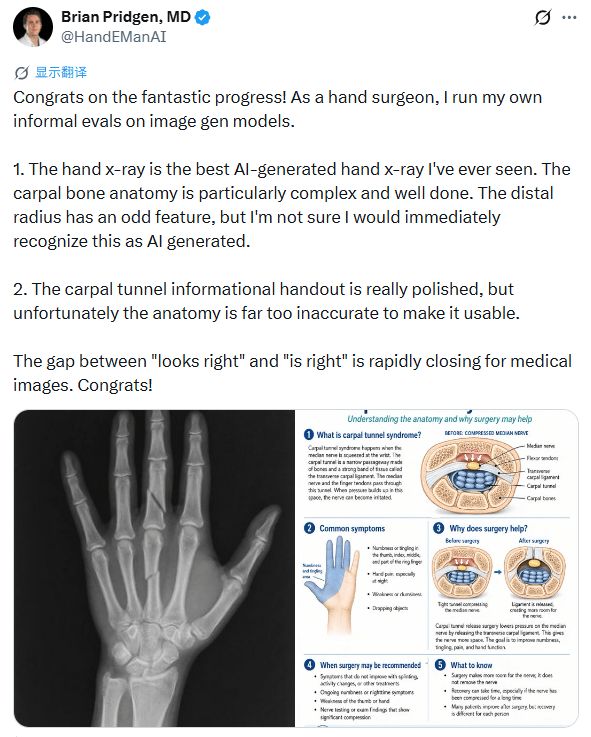
好消息是那张AI生成的X光片是他见过的最好的AI手部X光片。腕骨区域的解剖结构尤其复杂而模型处理得相当不错。他说桡骨远端有一个奇怪的特征但不确定自己能不能一眼认出这是AI画的。医疗图像里看起来正确和实际上正确之间的差距正在迅速缩小。
坏消息是那份腕管信息传单虽然设计精致但解剖结构过于不准确完全没法用。这提醒人们在高专业门槛的场景里,模型的视觉表现力和事实准确性之间仍然存在巨大鸿沟。它可以把一件事画得很像那么回事,但当细节关系到诊断、教学或实际操作时,像绝对不等于对。
在LMArena人工智能匿名测试平台上,ChatGPT Images 2.0以化名duct tape进行了数周的秘密测试。研究者阿纳斯塔西奥斯·安杰洛普洛斯(Anastasios Nikolas Angelopoulos)的评价是,这个模型把竞技场排行榜搞得天翻地覆并创造了竞技场历史上最大的评分差距。
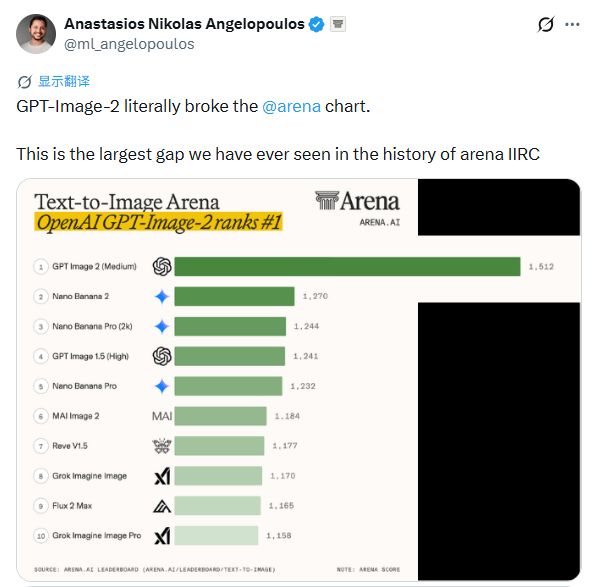
早期测试用户已经用它生成了包含长篇文本块或不同文本面板的复杂图像、逼真的网站界面截图、真实人物肖像以及融入网络搜索结果的综合图像。
06安全与定价:三层权限体系下生成一张高清图约0.4美元
在能力大幅跃升的同时OpenAI同步调整了使用权限和定价。
基础版ChatGPT Images 2.0向所有ChatGPT和Codex用户开放。这包括更好的指令遵循、更强的文本渲染、多语言能力、从三比一宽幅到一比三高幅更广泛的宽高比以及更精致的输出质量。
思考功能面向ChatGPT Plus、Pro和Business用户开放(企业版即将推出)。这包括工具使用、网络搜索和多图像生成能力。在此之上Pro用户还能用到更高级的图像生成功能。OpenAI没有公布三个层级之间精确的功能边界,但从现有信息看思考模式是绝对的核心分水岭。它让模型从画得快变成想得深,代价是生成速度变慢因为背后多了推理和搜索的步骤。
API用户可以接入gpt-image-2模型,支持最高4K分辨率(测试阶段)和灵活的宽高比选项。定价方面图像输出每百万token收费30美元。拿威利森的浣熊沃利测试来说,那张高清图消耗了13342个输出token且总成本约0.4美元。
OpenAI同时确认GPT-Image-1.5将不再作为默认模型,但仍可通过API获取以提供旧版支持。这一过渡充分说明公司对2.0模型的信心。
结语:AI画图正式进入推理时代
ChatGPT Images 2.0的发布不只是参数或画质的提升。它标志着图像生成从根据提示画画向理解任务并系统执行的转变。
过去用户和AI图像工具之间始终存在一个意图差距。脑子里想要的是一张结构清晰、信息准确且可直接拿来用的图,但模型只能吐出一个差不多的画面,剩下的细节得自己开设计软件修补。ChatGPT Images 2.0试图用推理能力彻底填上这个差距。
当用户上传一份文档要求做成信息图,模型不再只是画一张看起来相关的图片,而是分析文档里的数据结构,规划信息层级并安排图文布局,最后生成一张逻辑自洽的成品。OpenAI管这个叫从工具到视觉系统的跨越式转变。
这对商业用户来说意义很直接。营销团队可以用它快速产出不同尺寸的广告素材,教育工作者可以用它做包含测验题的多页学习手册,产品经理可以用它把内部文档直接转成演示用的视觉方案。等模型思考多花的那一分钟,跟手动设计要花的几个小时比起来怎么算都划算。
当然问题依然存在。模型在反复编辑时的顽固倾向、非英语语言的准确度波动以及专业领域知识的可靠性边界,这些都需要在实际使用中认真对待。
威利森的测试还揭示了一个有趣的陷阱。当他要求模型在自己生成的那张找不到浣熊的图里用红圈标出浣熊时,模型居然在画面中凭空画出了一只原本不存在的浣熊然后圈了出来。这说明在涉及自身输出的自检任务中模型的可靠性仍然需要打个问号。
但无论如何ChatGPT Images 2.0把图像生成带进了一个全新的竞争阶段。在谷歌Nano Banana 2于今年2月发布以及微软MAI-Image-2等竞品相继出现的背景下,OpenAI用这款产品强势回应了市场对更聪明而不只是更精细的图像工具的期待。
从工具到视觉系统,这一步跨过去之后用户不再需要学习怎么跟机器说话,因为机器已经开始学习怎么听懂你的话了。