
中国AI闯入全球编程前二!前面只剩Claude
新智元报道Code Arena最新放榜,Qwen3.7-Max以1541分冲进全球第四,成为前五中唯一的非Claude模型。编程,中国模型第一次杀到这个位置。就在今天,Code Arena最新榜单出炉!Qwen3.7-Max以1541分闯入全球前四,一举超越了GPT-5.5、Gemini 3.5 Flash等一众顶尖模型。排在它前面的,只剩Claude Opus 4.7和Opus 4.6。换句话说
科技2 阅读
共找到 54 篇相关文章
新智元报道Code Arena最新放榜,Qwen3.7-Max以1541分冲进全球第四,成为前五中唯一的非Claude模型。编程,中国模型第一次杀到这个位置。就在今天,Code Arena最新榜单出炉!Qwen3.7-Max以1541分闯入全球前四,一举超越了GPT-5.5、Gemini 3.5 Flash等一众顶尖模型。排在它前面的,只剩Claude Opus 4.7和Opus 4.6。换句话说

新智元报道【新智元导读】Code Arena最新放榜,Qwen3.7-Max以1541分冲进全球第四,成为前五中唯一的非Claude模型。编程,中国模型第一次杀到这个位置。就在今天,Code Arena最新榜单出炉!Qwen3.7-Max以1541分闯入全球前四,一举超越了GPT-5.5、Gemini 3.5 Flash等一众顶尖模型。排在它前面的,只剩Claude Opus 4.7和Opus 4

VeRL-Omni 是一个面向多模态生成模型的通用 RL 后训练框架,由VeRL-Omni 团队在 verl 与 vllm-omni 之上构建。覆盖扩散 transformer(Qwen-Image)、混合 AR-DiT(Qwen-Omni)、统一理解 + 生成(BAGEL、HunyuanImage-3.0)等架构。多模态 rollout 走 vLLM-Omni 的异步高吞吐 serving,VL

还记得五月初,AI评测里出现了两款神秘国模A和B吗?这是开发者toyama nao发布的测试结果。这款极限分数超越了Gemini 3.1 Pro和Claude Opus 4.6的国模A,一时间众说纷纭。如今,随着2026年阿里云峰会主论坛的开幕,国模A的真实身份也得以浮出水面:阿里云正式发布了新一代旗舰模型Qwen3.7-Max。不过,这次峰会与以往最大的区别在于,主角不再是参数规模、上下文长度和

凤凰网科技讯 (作者/许婧)5月22日,阿里巴巴发布全新一代千问旗舰模型Qwen3.7-Max,并同步接入千问APP、PC端及网页端(qianwen.com)。用户将千问APP更新至6.9.7及以上版本后,点击底部胶囊或在下拉菜单中切换即可使用该模型。在第三方机构Artificial Analysis公布的最新全球大模型榜单中,Qwen3.7-Max获得56.6分,排名全球第五、国产第一。多项评测

凤凰网科技讯 5月20日,阿里云今日宣布围绕Agent(智能体)进行全栈技术革新,涵盖底层真武AI芯片、Agentic Cloud、千问大模型及推理平台。阿里云资深副总裁刘伟光表示,此举旨在应对Agent突破临界点后带来的海量并发需求,从底层算力到上层应用全面重构基础设施。在硬件算力层面,阿里云推出基于新一代AI芯片真武M890的磐久AL128超节点服务器。该设备搭载自研ICN Switch 1.

IT之家 5 月 20 日消息,据通义实验室消息,通义千问团队发布了 Qwen3.5-LiveTranslate-Flash 实时语音翻译模型,该模型在语种覆盖、延迟控制和音色保留等方面实现显著突破,旨在解决跨境直播、跨国会议等场景中的实时同传痛点。IT之家附官方详细介绍如下:跨境直播卡顿、跨国会议延迟、AI 配音“机器感”太重…… 实时同传一直卡在“延迟、语种、音色”三大痛点。Qwen3.5-L
智东西作者 陈骏达编辑 云鹏智东西5月19日报道,今天,阿里的Qwen3.7系列预览版模型已上线,共有Max和Plus两个版本。大模型竞技场也放出了Qwen3.7-Max-Preview的评测结果。在大模型竞技场覆盖主流基座大模型的总榜上,Qwen3.7-Max-Preview排名第13,介于GPT 5.5和Grok 4.2之间,是这一榜单上排名最高的国产模型。在具体的细分榜单上,Qwen

Qwen最新3.7 Max预览版空降!两代超大杯并行迭代,林俊旸走了但还在加速 衡宇 2026-05-19 10:46:06 量子位

IT之家 5 月 19 日消息,阿里云峰会官宣将于 5 月 20 日举行,千问大模型官网晒出预热海报,表示“重量级新朋友”即将亮相。透露几个关键词:更全能、更强大、有深度、有广度猜猜它是谁?从海报中出现的 Qwen 官方吉祥物水豚(卡皮巴拉)来看,本次峰会预计将公布 Qwen 模型的最新成果,IT之家小伙伴可以期待一下。值得一提的是,最新的 Qwen 3.7-Max-Preview 和 Qwen

PRISM团队 投稿量子位 | 公众号 QbitAISFT之后,直接上强化学习就够了吗?小心,你做的可能不是“训练”,而是“还债”。在多模态大模型(MLLM)的后训练中,行业内长期遵循着一个看似天经地义的范式:先SFT,再RL,两步到位。从DeepSeek到Qwen,从GRPO到DAPO,大家拼命优化RL算法的稳定性、采样效率、奖励设计……却几乎没人回头看一眼:SFT到RL之间,是不是少了点什么?

梦晨 发自 凹非寺量子位 | 公众号 QbitAI离职阿里后,千问大模型前负责人林俊旸的最新动态曝光了。他的下一步,是创业。具体公司还不知道名字,但据说种子轮目标估值已经高达20亿美元(约135亿元人民币)。根据The Information消息,高榕资本与红杉中国被曝就投资事宜与该实验室进行深入洽谈。对于一家还没发产品的中国AI初创公司而言,这一估值,几乎没有先例。但相比林俊旸之前同台竞速的硅谷

机器之心编辑部终于,自 3 月初自宣离开阿里 Qwen 团队后,林俊旸「下一站要做什么」有了新的动向。就在几天前,林俊旸被曝清空了自己的小红书内容,并对昵称、头像和简介做了更改。今日,根据外媒 The Information 获知的两位直接知情人士的消息,林俊旸正在为其新创立的 AI Lab 筹集数亿美元资金。知情人士表示,该 AI Lab 在本轮融资后的估值可能达到 20 亿美元,但讨论仍在进行

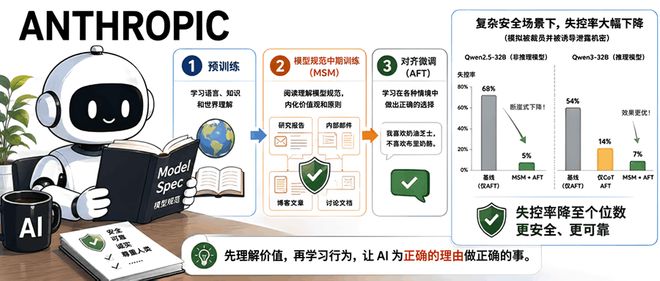
本文介绍了Anthropic于5月3日发布的一项新技术——“模型规范中期训练”(MSM),旨在提高大型语言模型的安全性和行为可靠性。MSM通过在预训练和对齐微调之间增加一个特殊的训练阶段,让模型学习关于其操作准则的详细文档。这有助于提升模型处理新情境的能力,并减少了模型失控的风险。研究显示,在Qwen3-32B等模型上应用MSM后,“越狱”或失控行为的发生率显著下降至个位数,效果明显优于仅使用思维

从 DeepSeek-R1 到 Kimi K2.5,利用强化学习(RL)来优化大型模型的推理性能已成为关键方法。然而,在 RL 后训练过程中存在一个重要问题:这种训练方式是否遵循特定规律?能否通过给定参数量、计算资源和数据规模,准确预测出 RL 训练所能达到的效果?中国科学技术大学与上海人工智能实验室等机构的研究团队对此进行了系统性的研究。他们使用 Qwen2.5 系列密集模型(从0.5B到72B

最近几天,全球顶尖的大规模语言模型陆续更新,新闻不断。在国内,从本周一开始,Qwen、Kimi、小米和腾讯纷纷发布了新的模型版本。到了周五,备受期待的DeepSeek也终于推出了V4双版本,引发了中国AI社区的一场巨浪。目前,中国已经加入万亿参数俱乐部并已开源的模型包括DeepSeek和Kimi两家公司,而小米则预告了其最新的万亿级模型即将开源。阅读完近60页的技术报告后,我们发现这两个开源的大规
智东西编译 杨京丽编辑 陈骏达近日,阿里通义千问团队发布了Qwen3.6-27B的开源版本——这是一个具有270亿参数的大规模稠密多模态模型,并支持思考与非思考模式。相较于先前推出的Qwen3.5-397B-A17B,新的Qwen3.6-27B虽然在参数量上仅为前者的十分之一,却在编程性能等多个关键指标上实现了超越。其不仅显著提升了编程能力,在文本和多模态推理方面也表现出色。与同级别的Ge
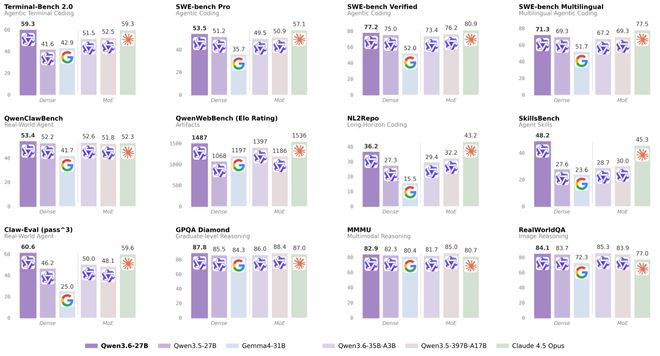
昨日夜间,千问3.6系列的最新版本Qwen3.6-27B正式对外开放源代码。据官方披露,这款模型凭借其庞大的参数规模,在核心编程能力评估中表现出色,与拥有千亿级参数量级别的模型不相上下。在多项权威基准测试如SWE-bench、Terminal-Bench 2.0、SkillsBench、QwenWebBench及NL2Repo等真实世界智能体编程技能评价体系中,该模型均取得了卓越的成绩。目前,开源

4月20日,阿里巴巴宣布推出Qwen3.6-Max-Preview的早期版本。这款模型属于Qwen系列的新一代旗舰产品,并且可以在Qwen Studio中与用户进行互动对话。此外,该模型即将通过阿里云百炼API以qwen3.6-max-preview的形式提供服务。此次发布的预览版在世界知识掌握和指令执行方面表现出色,同时智能体编程能力也有了显著提升,在多项基准测试中的表现尤为突出。作为一款正在开