
马斯克表态xAI追赶计划:预计2026年迎头赶上,2029年超越对手
最近,马斯克在 X 平台上对一份分析报告作出了回应,该报告将他的人工智能项目 xAI 评价为落后于行业内的领先企业。马斯克一贯以大胆的风格回应外界批评。这份于3月14日发布的帖子是对预测师彼得·威尔德福德的评估直接回应。威尔德福德的评估依据各类基准测试和公开报道,对人工智能开发商进行了排名。在这份排名中,Anthropic、谷歌和 OpenAI 被列为第一梯队,xAI 则与 Meta 并列,落后约
科技5 阅读
共找到 29 篇相关文章
最近,马斯克在 X 平台上对一份分析报告作出了回应,该报告将他的人工智能项目 xAI 评价为落后于行业内的领先企业。马斯克一贯以大胆的风格回应外界批评。这份于3月14日发布的帖子是对预测师彼得·威尔德福德的评估直接回应。威尔德福德的评估依据各类基准测试和公开报道,对人工智能开发商进行了排名。在这份排名中,Anthropic、谷歌和 OpenAI 被列为第一梯队,xAI 则与 Meta 并列,落后约
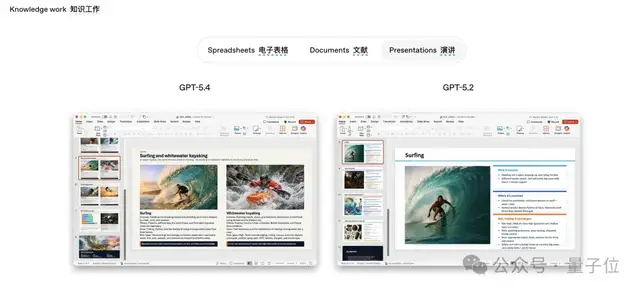
GPT-5.4 来了!这款新版本融合了推理、编程、电脑使用等多个领域的技术。 它将这些能力整合到了一个模型中,且每一项性能并未因此受损。 OpenAI在多个关键基准测试中证明了GPT-5.4的领先地位。 开发者们特别关注其原生支持“计算机使用”这一功能。 GPT-5.4推出后,人们对它的期待越来越高。 在官方博客文章中,提到该版本效率有了显著提升。 相较于GPT-5.2,新版在推理过程中使用
在涉及1,300至1,500原子规模的高精度DFT基准测试中,实现了卓越水平的精确度,并能够支持单卡处理高达15万个原子的数据量。精确模拟分子在药物开发、蛋白质结构研究和核酸功能分析等领域至关重要。然而,长期以来,这些领域一直受到“尺度与精度”之间矛盾的影响:高精度量子化学方法通常只能涵盖数百个原子,而更可扩展的经典力场则难以描述复杂分子间的相互作用及非局部效应。尽管机器学习力场显著提升了精度,在
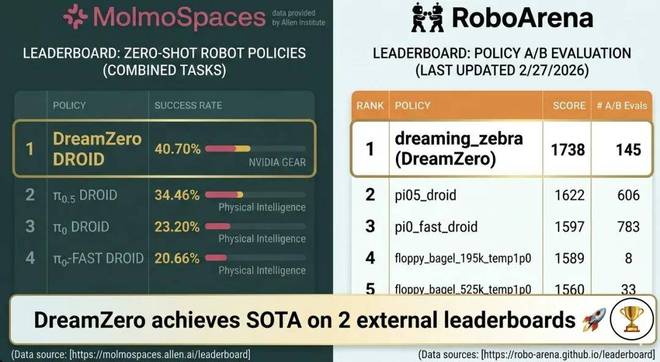
机器之心编辑部近期,NVIDIA 推出的世界动作模型 DreamZero,在两项重要的机器人基准测试 RoboArena 和 MolmoSpaces 上取得了优异的成绩。DreamZero 的核心在于:在一个单一的架构中预测未来的视频和机器人的动作。这意味着在采取行动前,机器人可以在内部模拟未来的情境。但问题也随之而来。为什么这样的设计能显著提升性能?它与传统的策略模型或世界模型相比有何不同?这是

Pantera Capital和富兰克林邓普顿数字资产部门已加入Sentient新推出的开源AI实验室Arena的首批参与名单。该测试环境旨在评估企业级工作流程中AI智能体的表现。据公告,Sentient在周五通过Cointelegraph宣布,Arena被定位为一个生产环境级别的基准测试平台,而非静态模型测试工具。除了固定数据集上的评分外,它还让智能体执行标准化的企业场景任务,如处理长篇文档、不

近日,谷歌正式发布了其最新的图片生成和编辑模型Nano Banana 2(Gemini 3.1 Flash Image),该模型已在谷歌的多种产品中上线。Nano Banana 2在功能与速度上进行了全面提升,在世界知识、图像质量、推理能力和主体一致性等方面均有所突破。同时,它在基准测试中的表现优于GPT-Image 1.5、Seedream 5.0 Lite和Grok Imagine Image

过去两年间,大型语言模型在推理领域的进步显著。从数学与编程生成到解决复杂的逻辑和科学问题,这些模型不断刷新基准测试的记录。随着“推理模型”概念的兴起,越来越多的研究开始将推理能力视为通向通用人工智能的关键标志。在能力迅速提升的同时,一个更为基础的问题逐渐显现:当模型在执行推理任务时出现错误,这些失误是随机波动还是表明了深层次的设计缺陷?近期发表于 TMLR 的论文《大型语言模型推理失败》对该问题进

在评估大语言模型(LLM)生成代码的能力时,一个日益凸显的问题浮现出来:当这些模型在 HumanEval 和 MBPP 等经典基准测试中取得近乎饱和的成绩时,我们究竟是在衡量其真实的泛化推理能力,还是仅仅检验它们对训练数据的记忆力?目前的代码基准正面临两大核心挑战:一是数据污染的风险,二是测试严谨性的不足。前者可能使评测退化为「开卷考试」,而后者常常导致一

新智元报道马斯克亲自为grok-image-video-720p这款视频模型站台,该模型在46万次盲测投票中获得第一名。xAI的这一「压箱底」之作,在基准测试上超越了谷歌Veo 3.1 Fast,并且使用成本更低。近日,AI视频领域再次迎来重大变化!xAI的Grok图像转视频模型(grok-image-video-720p)在「Image-to-Video