机器之心编辑部
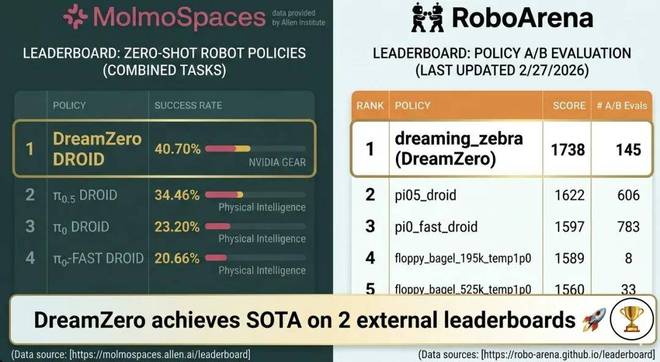
近期,NVIDIA 推出的世界动作模型 DreamZero,在两项重要的机器人基准测试 RoboArena 和 MolmoSpaces 上取得了优异的成绩。
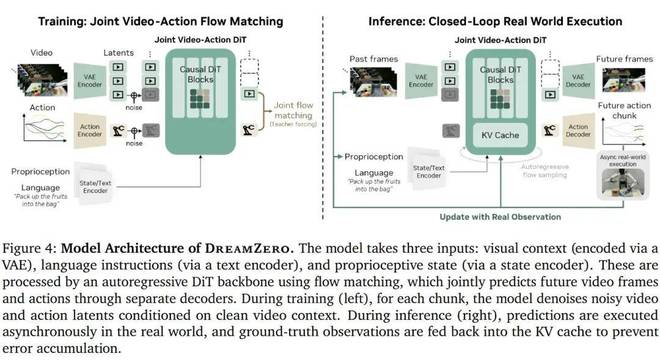
DreamZero 的核心在于:在一个单一的架构中预测未来的视频和机器人的动作。这意味着在采取行动前,机器人可以在内部模拟未来的情境。
但问题也随之而来。
为什么这样的设计能显著提升性能?它与传统的策略模型或世界模型相比有何不同?这是否代表了一种真正的创新,还是仅仅因为数据量和技术规模的优势?
针对这些问题,一篇近期颇具影响力的分析文章《为何 DreamZero 在机器人领域表现出色》对此进行了深入探讨:训练通用机器人的有效方法是什么?这篇文章的解读正在挑战现有的认知。
文章作者是一位名叫 Chris Paxton 的研究人员,他曾负责 Hello Robot 公司的具身智能项目。在此之前,Paxton 曾在 NVIDIA Research 和 Meta 旗下的 FAIR 工作。

这篇文章从模型介绍、训练数据特性、规模大小、时间上下文长度以及视频生成作为辅助监督信号等多个角度剖析了 DreamZero 的成功原因。

接下来是文章的核心内容。
DreamZero 是什么?
它是一个由 NVIDIA 提出的世界—动作模型。它借鉴了许多世界模型的基本原理,特别是视频生成在机器人任务中的价值,并在此基础上进行了关键的改进。最为重要的一点就是将动作预测和视频生成结合在一起进行建模。
通常来说,世界模型可以分为两大类:
动作条件的世界模型:这类方法学习的是状态与动作到下一状态之间的映射关系 x′=f(x,a)。其中 x 表示当前观测的状态,a 则代表了动作。例如 V-JEPA 2 或者最近的 RISE 论文中的世界模型就属于这一类型。
逆动力学的世界模型:比如 NVIDIA 的 DreamGen 和 1X 的世界模型。这类方法首先学习 x′=f(x),然后再通过一个逆动力学模型 a=g(x,x′) 来预测动作。
相比之下,DreamZero 更像是传统的机器人策略模型,但它还会额外预测未来的视频内容。
因此,它实际上是在同一个模型中同时进行未来状态和对应动作的预测。
这种设计使得 DreamZero 不仅可以预测动作,还能模拟未来的画面场景。这为模型提供了一个更为丰富的监督信号来源,帮助其更好地理解环境变化规律。
RoboArena 是一个基于 Droid 平台的真实世界评估框架。它汇集了来自世界各地的不同机器人和实验设置,并根据自然语言指令运行一系列开放式的机器人任务测试。
基准
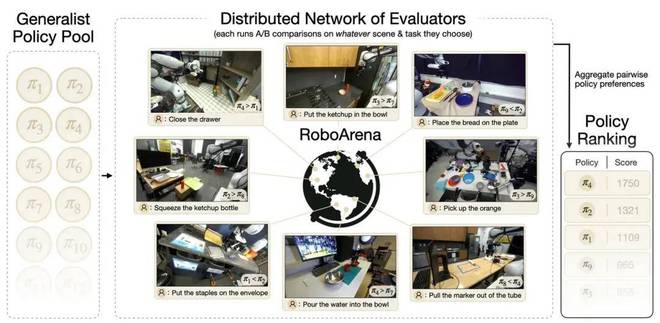
这意味着,在数据分布的角度来看,RoboArena 为 DreamZero 提供了一个相对接近的场景环境。因为 DreamZero 的训练正是基于 Droid 数据集进行的,而该数据集中包含了大量类似的任务和实验条件。
同时,这也是一个真实世界的评估平台,具有高度的变化性和复杂性;并且具体的任务是由各个评测者自行挑选确定的。
RoboArena 还是一个直接对比不同模型性能的基准测试环境,类似于在大模型发展过程中影响深远的 Chatbot Arena。

MolmoSpaces 是一个新的测试平台,具备高保真物理模拟能力和多样化、程序化生成的环境。
其中,MolmoSpaces-Bench 重点考察了不同受控变化条件下的任务表现,包括抓取、放置和开合等基础操作以及它们的组合任务。
这是一个尚未达到性能上限的新基准,意味着模型之间仍存在明显的差异,并且还有很大的提升空间。DreamZero 在这一系列测试中都表现出色。
我们能从中学到什么?
我们可以详细比较一下 DreamZero 和 pi-0.5 的表现,因为后者是目前排名第二的模型。
训练数据方面
pi-0.5 使用了超过 1 万小时的真实机器人数据、视觉语言模型(VLM)数据以及 Droid 数据集进行训练。而 DreamZero 则根据不同版本,使用 DROID 或 AgiBot 数据进行训练。
训练数据的分布可能起到了至关重要的作用。在 DreamZero 的论文中可以看到,在 AgiBot 数据集上它的表现明显优于 pi-0.5(而 AgiBot 并未包含在 pi-0.5 的训练数据内);然而,当两者都使用了 DROID-Franka 设置时,它们的性能差距则要小得多。
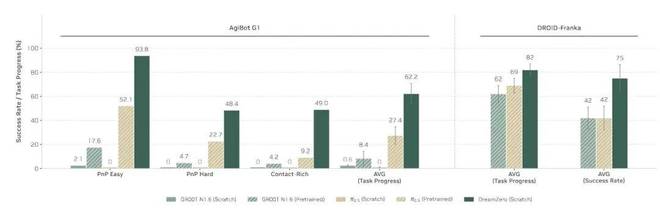
这似乎表明额外增加 1 万小时的真实机器人数据可能并不像人们想象中那样有效。
更重要的是,也许并不是数据量本身,而是是否在正确的分布上进行预训练。最近一篇博客文章展示了当模型在与目标任务高度一致的数据集上进行预训练时,其性能会有显著提升的事实。
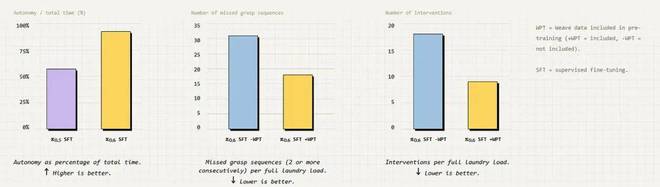
因此,从其他机器人身上额外增加 1 万小时的数据,并不一定比使用第一视角视频数据更有效果。对于那些希望训练通用机器人的研究者来说,这可能不是一个好消息。简而言之,在不同形态的机器人之间获得的数据收益,可能并不会超过单纯加入大量低成本的第一视角视频数据。
模型主干
首先从主干模型规模上来看,
DreamZero 使用的是一个 140 亿参数的大模型 Wan2.1-I2V-14B-480P。相比之下,pi-0.5 则基于 30 亿参数的开源视觉语言模型 PaliGemma 进行训练。
其次是信息输入方式的不同,
DreamZero 能接收多达 8 帧的历史画面作为上下文输入。而 pi-0.5 只能处理单帧图像,每次决策仅依据当前的一张照片。
在现实世界中,机器人任务通常具有以下特征:环境往往是部分可观测的、存在复杂的物理动态过程,并且高度依赖对时间连续性的理解。
如果模型只能看到单一时刻的画面,它很难判断物体是否在移动或静止,也无法推断当前状态与之前的动作关系。此外,模型难以捕捉到惯性等物理效应的影响。
相反地,如果模型能够观察多个连续的帧画面(比如 8 帧的历史信息),它可以更好地理解运动趋势和状态变化,从而更容易学习潜在的物理规律,并在控制决策上表现出更高的稳定性和准确性。
模型规模
DreamZero 是一个庞大的模型,论文中很大一部分工作集中在如何让这个巨大的模型实现实时运行。消融实验表明,增加模型规模对性能表现有显著影响。
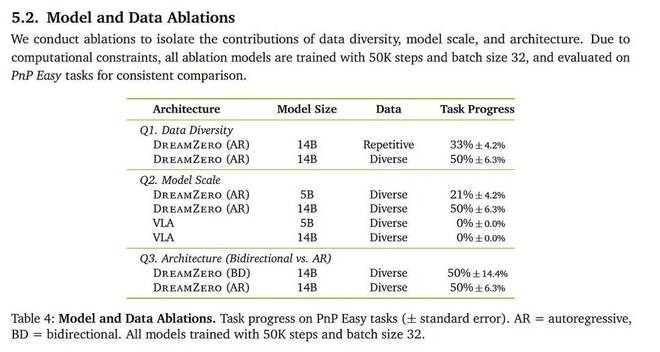
同时引入更长的历史信息、扩大模型规模通常会带来一个问题:训练难度加大,在低数据环境中更容易过拟合。大语言模型由于拥有海量数据,几乎不用担心过拟合问题。但机器人领域始终处于一个低数据的环境之中。
因此可以推测视频生成目标在这里充当了一种辅助损失(auxiliary loss)。它为 DreamZero 模型施加了结构约束,迫使模型学习某种内部的世界模型。与稀疏的动作信号相比,视频预测提供了一个更为密集和有效的监督信号来源。这可能使得模型更容易适应多样化的 MolmoSpaces 环境。
最后的思考
目前仅凭这些论文我们还无法得出全面结论。由于缺乏 Physical Intelligence 使用的全部数据以及 NVIDIA 用于推理的 GB200 设备,许多人或许会意识到,在真实世界机器人任务中取得强劲表现可能并不需要那么多的数据量。
最后作者表示将在接下来几周内推出一期专门讨论 DreamZero 的 RoboPapers 播客节目,并且下周还将发布一篇更深入的分析报告。感兴趣的读者可以留意一下。