
电影《大腕》中的经典台词「二十一世纪什么最贵?人才!」如今在AI领域得到了具体的体现。

最近,《人物》杂志发表的一篇名为《「卧底」Kimi 的 100 小时》的文章,在科技界引起了广泛关注。文中提到,这家成立仅三年、估值超过1200亿元人民币的创业公司里,有300多名员工平均年龄不到三十岁,每人肩上扛着近四亿估值。这里没有传统的部门墙和职级体系,甚至一名十七岁的高中生实习生也能以第一作者的身份发表论文并获得硅谷大佬的高度评价。
今天,Kimi 发布了一个名为「穿越计划」的招聘活动,进一步提升了这场天才争夺战的竞争门槛。

这个计划主要针对在校学生。其核心在于候选人可以在2026年入职实习时就提前被授予并锁定股权份额,这意味着年轻的技术人才在实验室阶段就能获得分享公司估值增长的资格,从而以高弹性的收益对抗传统职场中的确定性收入流。
作为一家仅有三年历史的新晋AI企业,Kimi 在当前快速扩张时期推出了这样的人才计划,无疑向外界释放了一个明确信号:AI时代的红利正直接面向顶尖技术人才倾斜,顶级人才可以跳过传统的晋升路径,与顶级风险资本一同享有跨越周期的价值回报。
为什么 Kimi 值得投资?
对于00后乃至05后的AI技术人员而言,可能会有这样的疑问:期权的最终价值取决于公司能达到的高度。Kimi 是否值得下注呢?我们先来看几组数据。
在过去的三年中,Kimi 的估值增长了四倍多,并跨越了180亿美元的大关,成为国内成长速度最快的AI企业之一。字节跳动用了四年以上时间才达到百亿美元的估值,拼多多则是在三年半左右的时间内达成此目标,而 Kimi 仅用时不到三年。
这不仅仅是关于快速成长的故事,在这个互联网红利仍然存在、市场空间较为清晰的时代背景下,Kimi 面临的是一个更加不确定、竞争激烈且技术迭代迅速的AI领域。在这个环境中能够跑出这样的速度,并非全靠运气,而是对技术路径、产品节奏和资源调度等多方面的综合把控。
2023年10月,在公司成立不久后,Kimi 就发布了支持二十万上下文长度的模型,刷新了当时全球大语言模型的记录。到了2024年3月,Kimi 宣布其模型能够处理高达两百万字的无损上下文内容,这意味着该模型可以一次性处理大量法律文件、医疗档案或大型代码库。
2025年,Kimi 推出了新的混合线性注意力架构——Kimi Linear,在业界引发了广泛关注和讨论,并被认为是长上下文与高效推理方向上的关键技术突破。
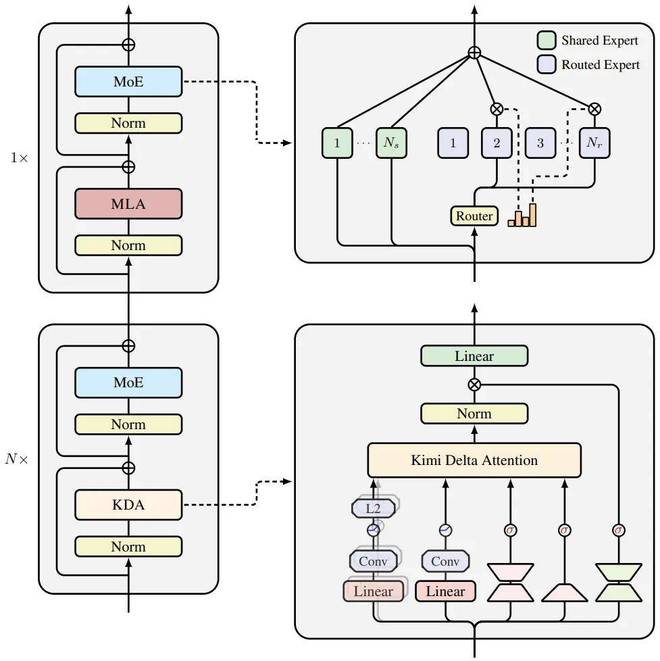
关于 Kimi Linear 架构的示意图
随后开源模型 Kimi K2 Thinking 的发布,再次点燃了社区的热情。该模型在多个核心性能上超越了GPT-5、Claude Sonnet 4.5等主流闭源系统,并因此获得了技术圈与开发者的密切关注。
自今年开始,Kimi 明显加快了步伐。年初发布的 Kimi K2.5 在多模态能力方面有所增强,首次具备视频理解功能并提升了编码能力,同时延续了开源策略。
从长上下文处理到架构创新再到持续的模型迭代更新,一条清晰的发展路径正在逐步展现出来:Kimi 不仅仅追求更强的大规模语言模型,而是致力于推动一套能够实现复杂任务理解和执行的通用智能技术体系发展。
这也是 Kimi 的愿景所在——专注于通用人工智能(AGI)的研究与发展
当这条路线逐渐清晰时,其价值不再仅体现在技术指标上。对于加入其中的技术人员而言,这代表着两个宝贵的条件:一是持续增加的资源和投入支持高强度的研发试验;二是不断被重新定义的技术前沿,让核心问题保持开放状态。
对于那些选择投身其中的人来说,真正的问题早已超越了获取多少回报这一层面,而是是否有机会站在新一轮智能革命的起点上,并参与到塑造未来发展方向的过程之中。
加入 Kimi 的不仅是为了金钱,更是为了探索前沿的机会和资源
成功参与「穿越计划」的年轻人将获得怎样的技术领域挑战?
在最近举行的 GTC 2026 和中关村论坛上,Kimi 创始人杨植麟对此给出了明确的回答。他认为大模型研发的核心在于如何通过能源转换来提升智能水平,新一代的研发者正在努力突破这一领域的极限。
KIMI 正在三个关键方向进行深入探索:Token 效率最大化、上下文长度的革命以及多智能体集群系统的开发。
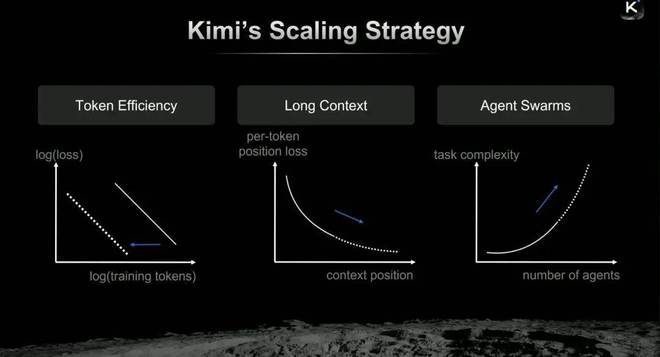
杨植麟 GTC 2026 演讲截图
第一,Token 效率的最大化。面对有限的高质量训练数据量,Kimi 团队引入了分布式 Muon 优化器和 QK 剪枝技术,使得模型在相同参数和训练集规模下实现了近乎两倍的效率提升。
其次是上下文长度处理的重大改进。传统全注意力机制由于计算复杂度随文本长度平方增长而受限。通过采用先进的线性注意力机制 Kimi Linear 架构,Kimi 使模型能够高效地处理长达百万Token的任务解码问题。
最后是探索智能体集群(Agent Swarms)。为防止多智能体系统在执行复杂任务时退化成单个智能体的串行工作模式或虚假并行,Kimi 放弃了传统的人工设计工作流方法,转而利用大规模强化学习技术来让模型自主学习到有效的任务分配策略。
参与者还将直接参与到下一代深度信息传递机制的研究中。例如近期引发学界广泛关注的「注意力残差」架构,它创造性地将原本应用于序列维度上的注意力机制旋转了90度,并应用到了深度维度上。
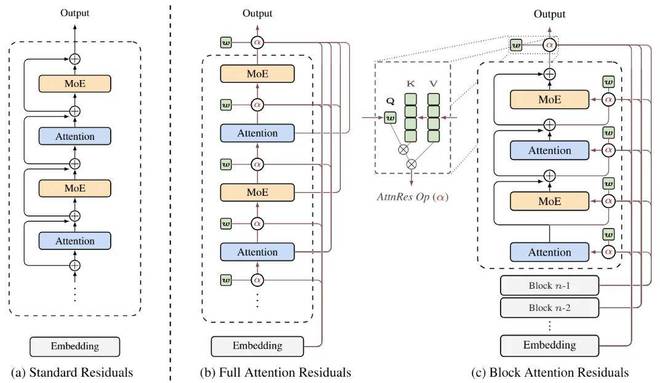
Attention Residuals 概览:(a) 标准残差: 采用均匀加法累加的传统残差连接方式。(b) 全量级的注意力残差:将标准残差应用于整个模型结构中,实现了更高效的信息传递和处理能力。(c) 深度维度上的注意力机制创新。
这个故事也揭示了 Kimi 和传统大厂之间的区别:在后者科层制体系下,年轻的科技天才往往只能成为高薪流水线上的边缘齿轮。而在 Kimi ,每个人都可以通过直接沟通来推动工作进程,形成了一个极致扁平化、低熵运行的“天才集群”。
在这里,年轻的研究人员拥有极高的研究自由度,并能够直接参与最前沿的核心决策和顶级学术交流。
2026 年将成为顶尖研究员的买家市场

当 AI 竞争进入智能上限突破的新阶段时,从开源框架 OpenClaw 的繁荣到各种智能体集群的应用落地,顶尖的技术建设者在行业内已经获得了前所未有的话语权。
在这样一个绝对买方市场的环境下,像 Kimi 这样的高增长速度的AI独角兽公司以提前锁定估值的方式向新一代天才发出了最真诚的邀请。这不仅是一场人才争夺战,更是宣布了 AGI 时代的入场券不再为顶级资本所独享。
最顶尖的技术人才完全可以凭借自身的才华,在这个伟大的技术周期中,获得穿越时代周期的巨大回报。
更多申请详情和相关信息可访问 Kimi 官方公告:《与 Kimi 共同投身于 AGI 的旅程》。
2026 年,顶尖研究员的绝对买方市场
随着 2026 年 AI 竞争向更深层次的智能上限突破推进,从 OpenClaw 等开源框架的繁荣到各类智能体集群的落地,顶尖技术建设者在行业内已经拥有了空前的话语权。

面对这种绝对的买方市场,像 Kimi 这样处于高倍速增长通道的 AI 独角兽,用提前锁定估值的方式向新一代天才发出了最硬核的邀请。这是一场人才争夺战,更是宣告了 AGI 时代的入场券已经不再为顶级资本所独享。
最顶尖的技术大脑,完全可以凭借自身的才华,在这个伟大的技术周期里,赢取穿越时代周期的丰厚回报。
申请方式及更多详情请访问 Kimi 官方公告:《和 Kimi 一起投身 AGI,穿越成长周期》。
文章链接:https://mp.weixin.qq.com/s?__biz=Mzk0NDU1MDkyNg==&mid=2247488323&idx=1&sn=0d38d4131b91b242301ef277a096d65c&scene=21&poc_token=HN6Pz2mjeLlEOT_k0cEFWtIQCFHs0lFmSO1VDH1u