
新智元报道
一位中国开发者在横跨大西洋的长途飞行中,利用MacBook本地运行Llama 70B模型,在没有网络连接的情况下完成了一整套项目交付工作,并因此在网上引起了广泛关注。
这位开发者的经历令人难以置信:他在长达11小时的航程里使用自己的笔记本电脑完成了客户的任务,而无需支付机上Wi-Fi费用。
在整个过程中,他没有借助任何云端服务或API支持,只依靠一台MacBook Pro M4、一段个人编写的脚本以及Llama 70B本地模型。
据说,他在飞机上的操作让很多网友感到困惑和不解,认为这个故事背后可能存在一些问题。
飞机上没有WiFi信号;而他的笔记本电脑则在执行一系列复杂的计算任务。
这个帖子一经发布便迅速在网络技术社区中流传开来,并引起了广泛的讨论与质疑。
人们开始思考,本地推理的时代是否已经到来?
在万米高空,
使用MacBook运行Llama 70B的故事广为传颂。
据悉,故事的主人公是一位在飞行过程中完成了大量项目交付任务的中国开发者。
在飞往目的地的靠窗座位上,他打开了一台内存容量为64GB的MacBook Pro,并面对着堆积如山的任务清单。
整个航程中都没有网络连接。
通常情况下,旅客会选择支付高昂且延迟的机上Wi-Fi费用来完成工作。
然而他选择了本地推理的方式继续工作。
开启了通过llama.cpp运行的Llama 70B模型。
生成速度达到了惊人的71 tokens/秒,上下文约为60,000 tokens,内存占用量为48.6 GiB / 64 GiB,起飞时电池剩余3小时21分钟。

针对如何在有限的资源下运行大型模型,他还特别编写了一个离线编排器脚本。
更令人惊讶的是他对AI下达的具体指示。
这个系统知道自己处于没有网络连接的状态,并且只能依靠本地文件和Llama 70B推理服务来完成任务。
它需要处理位于工作目录下的队列中的所有客户任务,每完成12项任务就保存一次上下文检查点以便在电池耗尽后继续运行。
系统清楚地意识到自己在未来的时间里将面临资源有限的挑战。
在接下来的飞行时间里,它必须独自处理所有的逻辑操作。
它以循环的方式执行任务:从队列中取出一个任务进行推理、保存结果并写入检查点文件。

当电池电量降至5%以下时,调度器会暂停运行等待更换电源后继续工作。
在飞行过程中系统日志记录了这些操作的详细信息。
它们包括上下文检查点的状态、任务处理进度以及完成的任务数量等。
当飞机着陆那一刻,所有的客户提案已经整齐地存放在done文件夹里。
有人评价说这是他们见过最高效且精简的离线AI工作流程之一。
在整个11小时的飞行中,未使用任何WiFi服务,所有任务都在笔记本电脑上完成。
这个系统不仅能够执行命令,还具有自我管理的能力。
这正是「自感知计算」的魅力所在。
人们在赞叹之余也开始质疑这个故事的真实性。
许多技术专家对此提出了疑问,并开始进行详细的分析与验证。
网友打假:
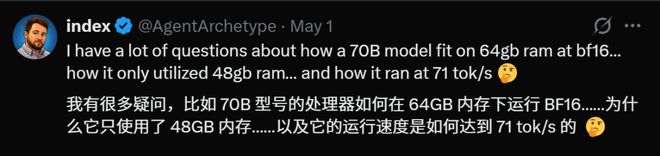
第一个问题是关于内存和模型大小的矛盾。
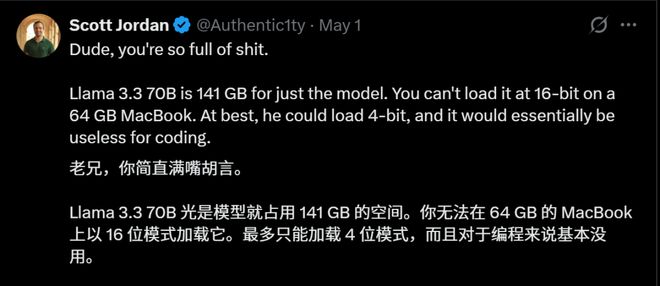
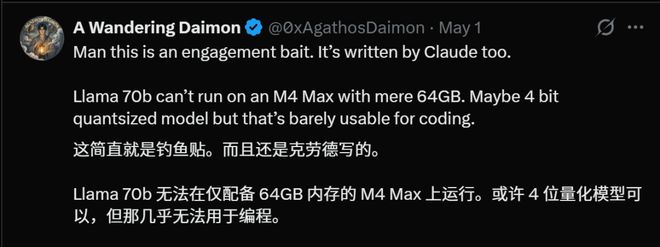
如果Llama 70B以半精度运行,其权重就需要大约140GB的内存空间,在64GB的MacBook上几乎是不可能实现的。
只有通过量化才能勉强在有限资源下运行,但这会牺牲模型的一些性能和准确性。
第二个质疑点是生成速度的问题。
帖子中提到的速度似乎不切实际,在M4芯片上通常只能达到5-12 tokens/秒。
这种高速度更像是高端硬件上的表现,而非普通笔记本电脑所能实现的水平。
一些用户通过实测数据表明在更好的设备上运行相同模型时速度反而更低。

因此,原帖中的速度声称可能并不真实可信。
此外,“更换电池”的说法也受到了质疑。现在的MacBook Pro设计为一体化,难以进行实际的电池替换操作。

它们更可能是通过连接外部电源来延长续航时间,但这在飞机上很难实现。
实际情况是,在高负载运行下M4 Max的实际续航能力会大大降低,因此原帖中的续航时长可能也是夸大的。
虽然这个故事的真实性受到质疑,但它揭示了一个重要的趋势:本地推理技术的发展正在悄然改变我们的工作方式。
以往开发者们习惯了依赖云服务和API来完成任务,而现在越来越多的人开始探索离线环境下的可能性。
这种变化为那些追求隐私保护或需要在没有网络的情况下工作的用户提供了一个新的选择。
尽管目前的技术可能还无法达到帖子中的速度,但通过优化与创新,未来或许可以实现更高效、实用的本地计算方案。
未来的顶尖开发者可能会是能够在极端条件下开发出高度自治AI系统的那个人。
第三刀:11小时续航
下一次飞行时你是否已经准备好携带一个“数字大脑”呢?
MacBook Pro M4 Max官方标称续航约18小时,那是轻度使用。持续满载跑70B推理,GPU和内存全程拉满,实际续航会大幅缩水。
虽然帖子里提到「切换到备用充电宝后恢复」——但跨大西洋航班经济舱的USB口功率通常只有7.5W到18W,而M4 Max满载功耗超过40W。
因此,续航11小时这个说法几乎站不住脚。

故事是假的,但范式转向是真的
面对质疑,我们需要剥开数据的水份,看清这件事背后真正令科技圈高潮的原因。
长期以来,我们已经习惯了「云端成瘾」。
没有 GPT-4 的 API,很多开发者甚至不知道该如何写代码;没有网络,AI 就变成了一个哑巴。
现在,本地推理,确实在发生一场静悄悄的革命。
2024年,在笔记本上跑7B模型还需要各种技巧。
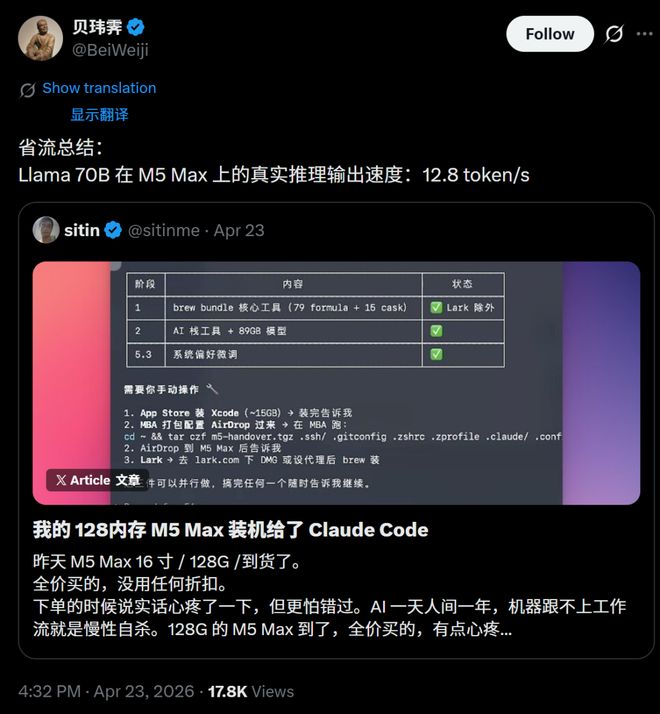
2026年,M4 Mac上跑70B量化版已经是日常操作。虽然速度不快,大概10来个tokens/s,但已经能用。
真实的使用场景不是「飞机上交付完整项目」这种听起来很爽的叙事,而是一些更朴素的东西,比如离线环境下的文档问答,隐私敏感场景下不想把数据传上云等等。
这些场景不性感,但实用。
现在,llama.cpp的mlx后端已经针对Apple Silicon做了深度优化,Ollama也把部署门槛压到了一条命令。
即便 71 tokens/s 的速度存疑,BF16 的精度可能有夸张,但这种「在孤岛上建立文明」的技术浪漫主义,才是最牛的。
未来,最顶尖的开发者或许不再是那个最会调优云端 Prompt 的人,而是那个能在资源枯竭、完全离线的极端环境下,手搓出一个「自感知、自循环」AI 系统的人。
下一次坐飞机,你准备好带上你的「数字大脑」了吗?
参考资料:
https://x.com/servasyy_ai/status/2050098091789828376