今日,蚂蚁灵波正式对外公布了其流式三维重建模型 LingBot-Map 的开源项目。该技术仅需使用普通 RGB 摄像头便能在视频采集过程中实时完成相机位姿估计及场景的三维结构重建,无需复杂的硬件设备支持,填补了实时空间感知领域的一项关键技术空白。
流式三维重建领域的关键挑战在于如何平衡几何精度、时序一致性和运行效率。传统的三维重建方法往往采用“先采集再处理”的方式,而流式重建则要求系统在接收新画面的同时进行定位和建图,并且需要控制计算与存储开销。
针对这一技术难题,蚂蚁灵波开发了 LingBot-Map 模型。该模型以自回归式建模为核心,采用基于几何上下文的 Transformer 架构,能够逐帧处理当前及历史画面,在不依赖未来帧信息的情况下持续输出精确的相机位姿和深度数据。
通过引入几何上下文注意力机制(GCA),LingBot-Map 能够高效地组织并利用跨帧的几何信息,同时减少冗余计算,从而在保证重建质量的同时提升运行效率。这一创新设计借鉴了经典 SLAM 系统中对空间数据分层管理的方法。
在多个权威基准测试中,LingBot-Map 表现优异:在 Oxford Spires 数据集上,该模型的绝对轨迹误差(ATE)仅为 6.42 米,远优于现有的流式方法。此外,在 ETH3D、7-Scenes 和 Tanks and Temples 等基准测试中也取得了显著领先的成绩。
值得一提的是,LingBot-Map 不仅在精度上表现突出,还具备出色的实时处理能力和长时间运行稳定性:其推理速度可达到约 20 FPS,并且能够在超过一万帧的视频序列中保持稳定的性能水平。这些特性使得 LingBot-Map 成为机器人导航、避障及操作等应用场景的理想选择。
自今年一月以来,蚂蚁灵波陆续开源了多项核心模型:
这一系列举措旨在完善其在空间感知、具身智能决策及环境建模等方面的技术布局,而本次 LingBot-Map 的开源则进一步增强了其实时空间理解和在线三维重建的能力。
目前,LingBot-Map 的完整模型和相关代码已在 Hugging Face 和 Model Scope 平台公开发布。蚂蚁灵波期待与更多开发者及研究团队合作,共同探索流式三维重建技术的潜在应用,并推动该技术在机器人领域的广泛落地,助力各行各业的技术革新与发展。
在 Oxford Spires 数据集(大尺度、复杂光照、高标准)上:
绝对轨迹误差(ATE)仅为 6.42 米
轨迹精度较此前最优流式方法提升约 2.8 倍
显著优于离线方法 DA3(12.87 米)和 VIPE(10.52 米)
在大场景重建中展现出更强的稳定性。
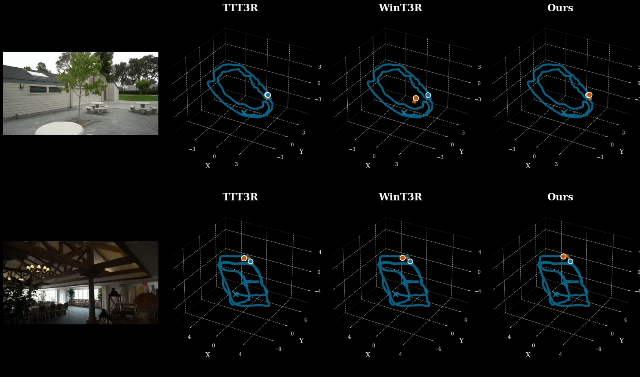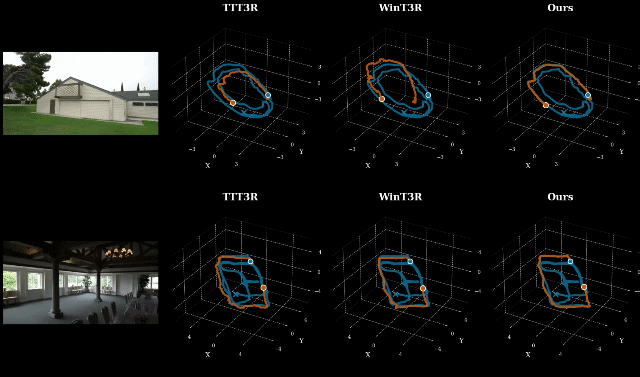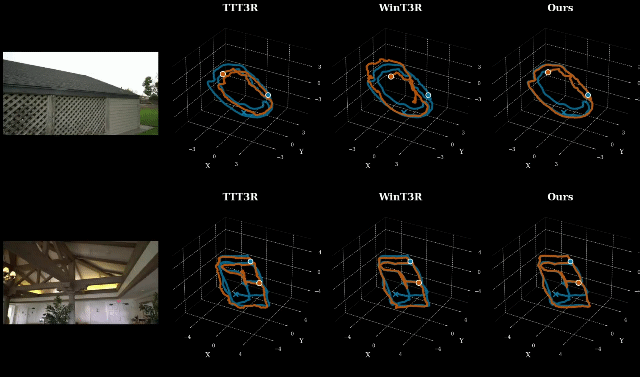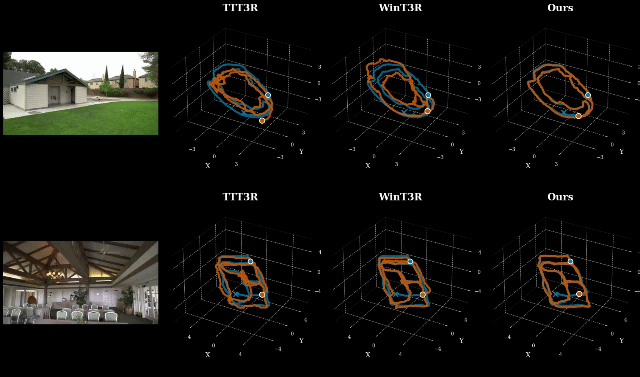
在 ETH3D、7-Scenes、Tanks and Temples 等多个主流基准上,LingBot-Map 在位姿估计和三维重建质量两个维度全面领先现有流式方法。
其中 ETH3D 基准:重建 F1 分数达到 85.70,较第二名提升超过 8%,场景还原精度大幅提升。

除精度外,LingBot-Map 还兼顾实时性与长时稳定运行能力:
推理速度可实现约 20 FPS
支持 10,000+ 帧长视频连续推理
长序列运行精度几乎无衰减
这意味着,在机器人导航、避障、操作、交互等需要连续在线处理的真实场景中,它能稳定输出可靠的空间感知结果,为上层应用提供坚实支撑。
持续开源多款模型:补齐实时三维建图关键拼图
自今年 1 月以来,我们相继开源:
高精度空间感知模型 LingBot-Depth
具身大模型 LingBot-VLA
世界模型 LingBot-World
具身世界模型 LingBot-VA
围绕空间感知、具身决策、世界模拟等关键环节,持续夯实具身智能“智能基座”的技术布局。此次 LingBot-Map 的开源,进一步补齐了实时空间理解与在线三维建图的关键能力拼图。
目前,LingBot-Map 的模型和代码已正式在 Hugging Face 和 Model Scope 开源。我们期待更多开发者、研究团队加入进来,一起探索流式三维重建的更多可能,推动技术落地,让机器人更稳定、更高效地理解和适应真实物理世界,赋能更多行业创新。