
本文探讨的并非使模型变得更聪明的方法,而是如何让试错过程本身更加高效。通过引入一套全新的框架,即使是普通的开源模型也能在科学发现上取得显著成果。
假设你有有限的资金预算,想要尝试一次未知领域的科学研究。你会怎么选择?
会把所有资金投入到一个顶级的模型中,让它长时间运行以寻求突破性的发现吗?
或者反其道而行之,在资源允许的情况下同时进行几十甚至上百个实验假设,通过竞争和快速筛选来找到最有潜力的方向?
前一种选择代表了当前大模型研究的基本思路:相信更强大的推理能力和更深的思考可以带来真理。
最近,由宽德智能学习实验室联合斯坦福大学、清华大学和北京大学等顶尖院校发布的一项新研究表明,科学发现的成功不仅取决于模型的聪明程度,还在于如何有效地组织试错与评估过程。
宽德智能学习实验室(Will)是一个独立于顶级量化私募宽德投资的研究机构,致力于运用人工智能技术解决科学和技术领域的挑战。该实验室秉持“AI for Good”的理念和长期主义,旨在构建通用的人工智能基础平台,以服务科学研究和技术革新,并在国际计算语言学会议(ICML)上展示了其研究成果。
通过将试错过程扩展到更大规模,开源模型在多个科学领域中不仅超越了许多闭源模型的表现,还在某些硬核领域打破了人类最佳纪录。

- 论文地址:
- SimpleTES框架的引入使得这一突破成为可能。该方法涵盖量子电路编译、GPU内核函数优化等六大应用领域,并展示了其强大的优化能力。
在LASSO路径求解方面,SimpleTES不仅在速度上超越了传统的glmnet和sklearn算法,在精度保持一致的前提下平均快2.17倍于glmnet,速度快达14倍以上于sklearn。这得益于它采用了一种动态切换策略的混合解法。
在量子比特路由问题中,SimpleTES在超导架构上比SABRE和LightSABRE分别提高了21.7%和14.9%,而在IBM Q20实例上更是降低了SWAP门开销达24.5%。这一方法的有效性进一步显示了AI在硬件优化上的潜力。
在Erdős最小重叠问题中,人类及现有AI已达到极限,但SimpleTES却能够继续推进,将数值从0.38087改进至0.380868,并在额外搜索中达到了0.380856。这表明其强大的探索能力不仅限于模型大小的影响。
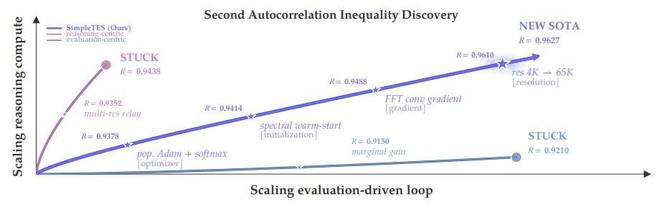
尽管SimpleTES展示了巨大的潜力,但其应用范围也受到评估器效能的限制。此外,如何动态调整资源分配以适应不同任务阶段的需求也是一个挑战。
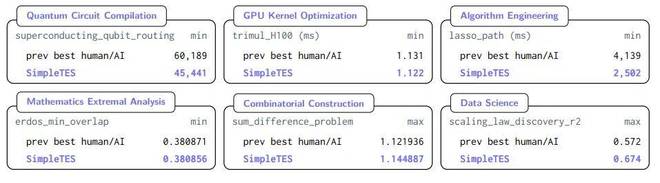
未来的研究方向是让试错过程不再仅仅是蛮力搜索,而是具有一定的结构感和方向性,从而进一步提升AI在科学研究中的潜力。
目前基于SimpleTES的方法已经可以通过Will的官方网站进行申请体验。对于那些想要率先尝试这一全新科研范式的用户来说,这无疑是一个绝佳的机会。
在评估驱动的科学发现引擎之外,Will 同时还在推进另外两条关键路径:自研基座大模型,以及面向科学研究的方法论探索。
三条线并行推进,在当前 AI 研究机构中并不多见。但他们的目标并不局限于单点突破,而是从零构建一整套面向科学发现的 AI 基础设施
在这套体系中,AI 不再只是「回答问题的系统」,而是逐步演化为能够参与完整科研闭环的主体。
换句话说,他们最终想实现的,是让 AI 学会做科研。
被忽略的「第三极」:生成-评估的闭环
其实,在 AI4S 这件事上,大家已经卷过一轮了。
一派思路很直接,继续往「更聪明的模型」上加码——更长的推理链、更复杂的 Agent 流程、更强的闭源模型,认为只要多想一会儿、多对话几轮,总能逼近新发现。
也有人把目光转向「试错循环」:生成 → 评估 → 改进,跑上几轮,拿到一个还不错的结果就收手(典型如 AlphaEvolve 一路)。
但问题在于,大家几乎都在放大「生成侧的算力」,却很少真正放大「评估反馈」本身。于是,一些老问题反复上演。
比如,经典的顺序改进( Sequential Refinement ),本质是单路径搜索,一旦早期方向选错,后面只会越修越偏。
科学问题往往是多目标、强约束的复杂空间,哪怕模型再强,也很难「一路推理」跨过去。
即使引入评估,反馈也不过是搜索流程的一个组件。更别提,这类系统高度依赖人工设计,工程复杂度极高,可归因和可迁移性都很差。
卡尔·波普尔说过,科学知识的增长,来自一轮轮基于「猜想—反驳」的证伪。如果把「试错 + 评估」本身,做成一个可以规模化、可以自动调度资源、可以持续放大有效信号的系统,会发生什么?
SimpleTES :
把试错变成一台可以扩展的流水线
这篇工作的关键突破在于,把试错、探索拆成一套可以被调度、可以被扩展、甚至可以被优化的计算流程。
核心是三个维度,非常极简:
- C( Concurrency ):并行多少条轨迹
- L( Length ):每条轨迹走多深
- K( K-candidates ):每一步生成多少候选
这三件事拼在一起,本质上是在做一件此前很少被正视的事情:把算力,从「堆模型能力」,转移到「精细分配搜索成本」。科学发现,从「灵光一现」,变成了一种可以被系统性放大的过程。
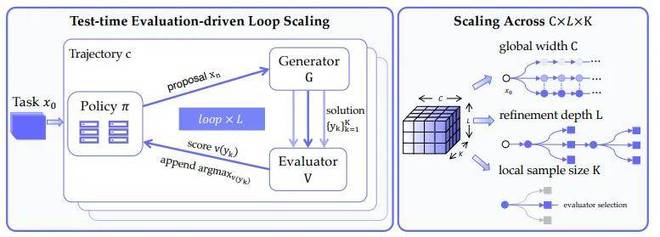
测试时评估驱动的循环缩放架构及其三维缩放维度。 左侧展示了基于策略网络、生成器与评估器的闭环迭代过程,通过 L次循环实现轨迹优化。右侧定义了缩放的三维空间:全局宽度 C、细化深度 L和局部样本量 K。
1、看得更广:C(并行探索)
不再「一条路走到黑」,同时启动 C 条独立轨迹,各自探索不同方向。避免开局选错方向,后面全盘皆输」。在复杂科学问题里,「想得更深」之前,必须先「看得更广」。
2、走得更深:L(迭代改进)
每一条轨迹,都不是一次性生成,而是在 evaluator(验证器、打分函数、模拟器等)的驱动下持续迭代。关键点在于评估,不再只是「打分器」,而是「方向控制器」。每一次反馈,都会微调搜索路径,把模型一点点推向更优解。
3、选得更准:K(局部筛选)
每一步不是生成一个解,而是生成 K 个,再只保留最优的那个。这一步相当于在局部做了一次「小进化」,把噪声遗忘,避免劣质解污染后续轨迹。
三维框架一旦确定,一个现实问题扑面而来:历史轨迹越来越多,但上下文装不下。
SimpleTES 的做法是,不把历史当「记录」,而是当「资源池」。哪些经验能进 prompt,被视为一个调度问题。他们引入 RPUCG(类似 UCB 的策略):一边优先高分或「曾经启发出好结果」的节点,一边给低频节点加探索补偿。
这其实是在 prompt 层做了一次「探索-利用权衡」,既不放过热门路径,也不忽视冷门潜力,避免搜索早早收敛到局部最优。
除了三维框架这一结构性的核心创新,SimpleTES 也从根本上解决了 AI 在科研决策中的短视挑战。
传统方法会优化每一步的 reward,但这样会让模型越来越保守。而科学发现恰恰需要允许早期「走弯路」。因此,在 Trajectory-Level Post-training 中,SimpleTES 直接换了训练目标,不看每一步,只看整条轨迹的最终最好结果。具体做法很利落:
一条完整探索轨迹等于一个 rollout ,忽略中间所有 step reward ;
用「最高分」作为唯一监督信号,反向赋给整条路径;
再配上简单但有效的策略:只保留 top R% 的轨迹(我要精英) ,截断无效后缀 ,用 replay buffer 持续累积经验
结果,模型学到的不是「下一步怎么更对」,而是「怎样的一整条探索路径更可能成功」。
这套 Trajectory-Level Post-training 如同炼金术,把「搜索能力」蒸馏进模型本身,使其逐渐形成一种接近「科研直觉」的能力。
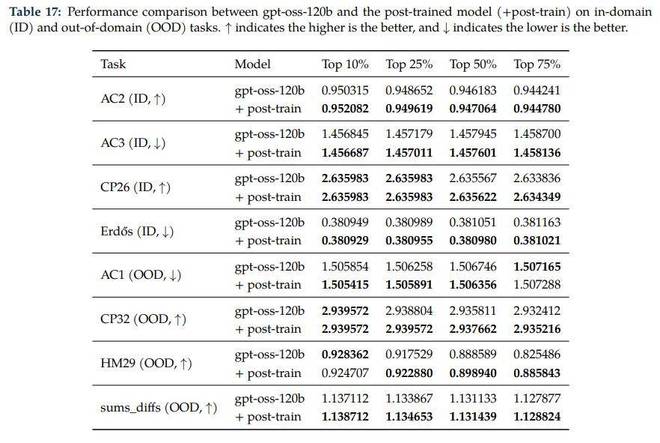
基础模型与后训练模型在多维度科学任务下的表现对比。 重点展示了模型在域内(ID)与域外(OOD)环境下的适应性差异,加粗项反映了后训练技术对模型逻辑推理和泛化能力的提升。
21个结果,21次振奋
结果显示(设定 C=32, L=100, K=16),在六大领域、21 个科学问题上跑通一整套「试错流水线」,只用 gpt-oss 这样的开源模型,就能不断刷出新的最优解,甚至把不少前沿闭源模型和精心调整过的优化流程都压了过去。
在许多硬核的领域也突破了人类最佳纪录。
该方法涵盖的量子电路编译、GPU 核函数优化等六大科学应用领域。

在 SimpleTES 框架的加持下,开源模型不仅超越了众多闭源模型,在许多硬核的领域也突破了人类最佳纪录。
以下是三个特别有冲击力的发现。
1、LASSO 路径求解(算法工程)
LASSO 是统计学、生物信息学和金融建模中极其基础且广泛使用的算法。像 glmnet 这种标准解法,本质是几十年工程经验的结晶。
SimpleTES 做的不是微调,而是直接改写解法。在保证精度(误差 ≤1e-6)完全一致的前提下,平均比 glmnet 快2.17 倍,比 sklearn 快14 倍以上
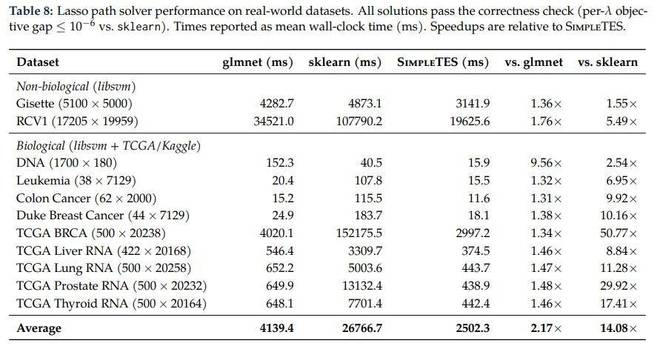
关键是它怎么做到的。传统方法基本是固定策略,而 SimpleTES 最终演化出来一套按问题结构动态切换的混合解法。
当问题处在某个几何区间(比如中等维度、样本不太少)时,它直接放弃 coordinate descent,切换到 LARS homotopy 路径算法,沿着正则路径解析式推进;在高维稀疏或更复杂结构下,保留 coordinate descent,再配合更激进的筛选机制。
这也是最有意思的地方,算法设计本身,开始变成可以被大规模试错搜出来的东西。
再看 AtCoder 这种比赛就更直观了。这类题本质上没有标准解,拼的是「解题套路」和「搜索策略」。SimpleTES 从零开始,独立发现了如「多起点模拟退火」等极具竞争力的程序,得分以绝对优势全面超越所有人类玩家记录与现有的 AI 解决方案。

2、量子比特路由(量子电路编译)
这个任务更有硬件味:量子门只能在相邻比特上执行,不相邻就必须插入 SWAP,把量子态搬过去。问题在于,每多一个 SWAP,电路就更慢、更不稳定。
所以,需要在保证所有操作可执行的前提下,把 SWAP 数量压到最低。但难点在于,这也是个典型的长程组合优化问题——你现在做的一个交换,会影响后面所有步骤。
目前,主要由顶尖的量子物理学家和计算机科学家设计的启发式算法来处理。
结果,SimpleTES 在不同量子计算机平台架构上均展现了强大的编译优化能力,有效降低了满足硬件约束的执行开销。
在超导架构上,SimpleTES 在整体上比经典算法 SABRE 提升 21.7%,比改进版 LightSABRE 提升 14.9%。在 IBM Q20 实例上更是将 SWAP 门开销降低了 24.5%。
在分区中性原子架构上,其发现的编译策略在 36 个多样化电路中将平均执行时间缩短了 33.2%,稳定提升了绝大多数测试用例的表现。
可见,当评估循环缩放到足够大时,AI 能够通过宽度探索出人类直觉无法触及的怪异但高效的路径。在严谨的物理约束下,AI 也可以成为真正的发现者。

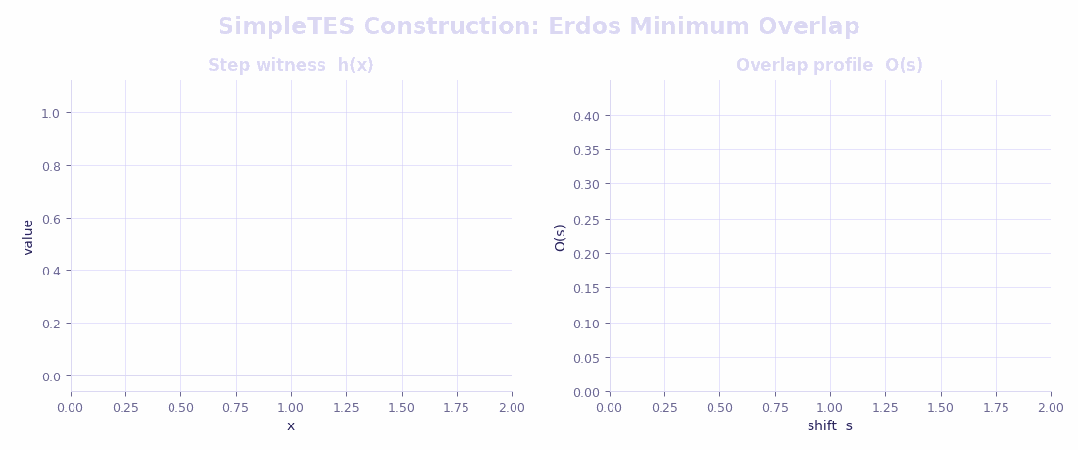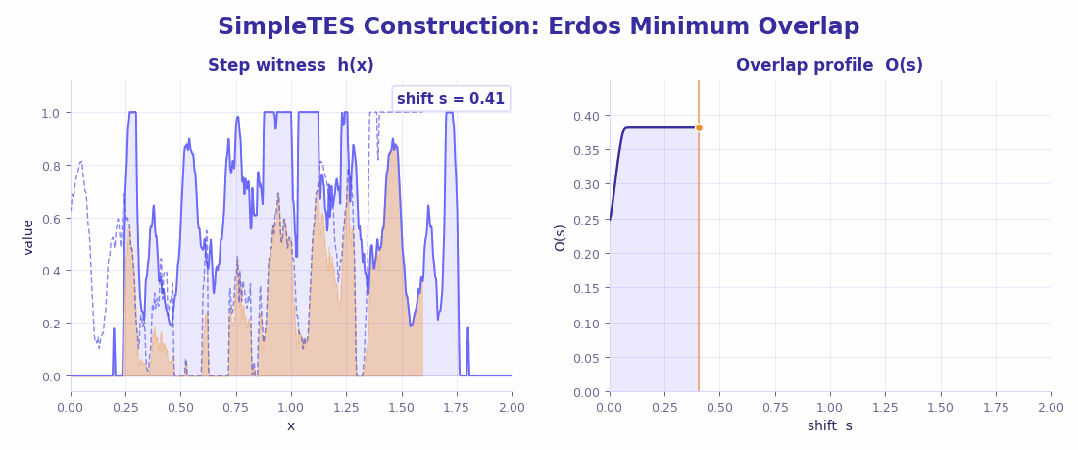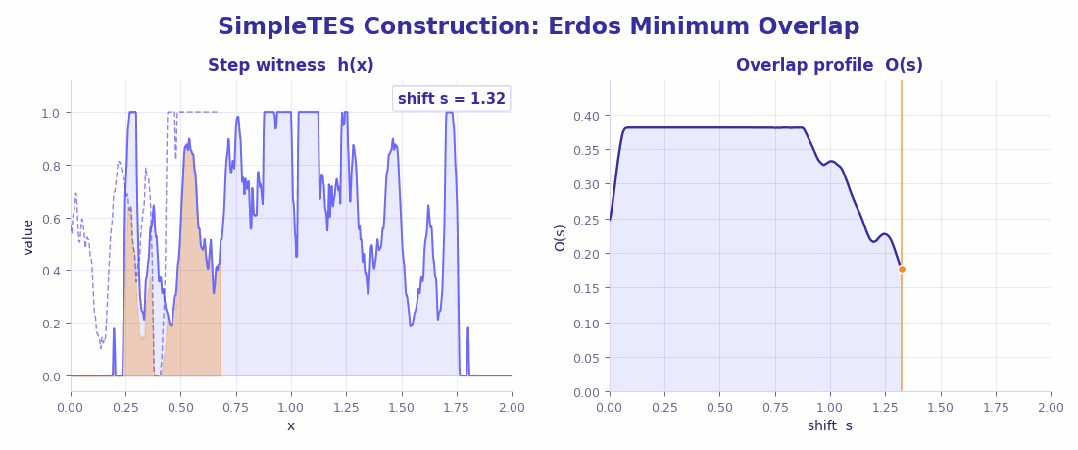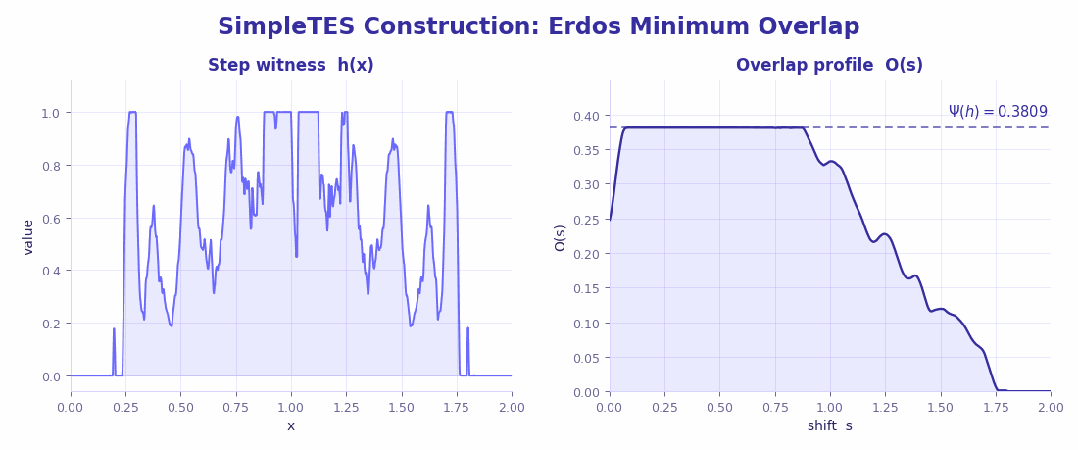
3、Erdős 最小重叠问题 (数学极值分析)
这是一个典型的极值构造难题:搜索空间巨大且极其崎岖,只要某个位置稍微偏一点,整体重叠就会瞬间放大,几乎就是在针尖上跳舞。
结果也很有意思——人类和现有 AI 基本都卡在 0.38087 附近,已经接近公认极限。但 SimpleTES 还是硬生生往下抠了一点:做到 0.380868,甚至在额外搜索中达到 0.380856。表面看只是小数点后几位,在这种问题里却是实打实的「极限推进」。
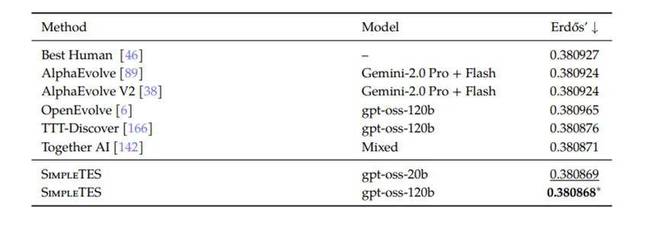
更关键的是,这个提升几乎和模型大小无关,而是来自搜索过程本身:既没错过正确方向,也有足够耐心往下抠细节,同时还把随机性压到最低。
这已经不是「更聪明的模型」,而是更高效的试错机制在发挥作用。
AI4S 新范式:
把「试错闭环」当成一等公民
如果说以 OpenAI o1 为代表的推理模型,开启了「深度思考」的缩放时代,那么 SimpleTES 做的,是把另一件长期被低估的能力,推上主舞台——尝试与验证,本身也可以被缩放。
但这套方法,也不是没有边界。
SimpleTES 的能力,本质上被一个东西「锁死」:评估器(evaluator)。它之所以有效,是因为每一步试错都能被快速、明确地打分。一旦进入那些评估昂贵、主观、或者必须依赖真实世界反馈的领域,这套机制就会变得吃力,因为你已经没法再高频地「试—评—改」。
另一个限制在于算力怎么分。三个维度现在还是手动调的,而不同任务、不同阶段,其实最优分配完全不一样。真正理想的状态,是系统能根据搜索进展动态调整,而不是一开始就把资源「写死」。
还有,这套方法天然适合「有连续分数」的世界。但在一些更离散的场景(比如定理证明),对错之间没有细粒度反馈,很多「差一点」的尝试看起来是一样的失败,这会让搜索信号变得模糊,甚至误导方向。
因此,Will 下一步,不只是把试错做大,还要让它更聪明,从一个高频运转的计算闭环,进化为一个真正具备理解、判断与探索能力的系统。
当「试错」不再只是蛮力搜索,而开始具备结构感和方向感时,AI4S 的上限,才会真正被打开。
目前,基于 SimpleTES 方法构建的试用平台已经在 Will 官网上线,欢迎大家前往申请加入 Waitlist,率先体验这一全新的科研范式。
- https://www.wizardquant.com/will/simpletes