 近日,DeepSeek-V4模型成功开源并在Hugging Face平台的开源项目排名中迅速攀升至榜首。此项目的相关技术报告详细披露了其针对华为昇腾与英伟达芯片优化、架构升级及预训练和后训练阶段改进等方面的技术细节。
近日,DeepSeek-V4模型成功开源并在Hugging Face平台的开源项目排名中迅速攀升至榜首。此项目的相关技术报告详细披露了其针对华为昇腾与英伟达芯片优化、架构升级及预训练和后训练阶段改进等方面的技术细节。
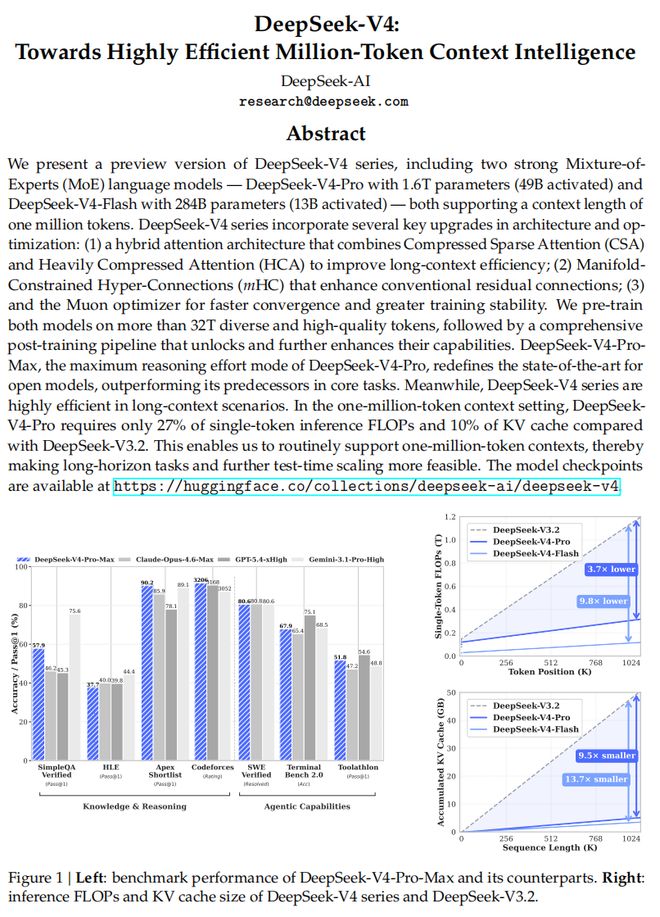
DeepSeek-V4在推理、知识获取和代码能力等关键领域均有显著提升,整体性能可比肩GPT-5.4和Claude Opus 4.6这些顶级闭源模型。此外,该版本首次以“百万上下文”作为默认配置,并在此设定下实现了单token推理FLOPs与DeepSeek-V3.2相比降低了73%,KV cache占用也仅为后者10%。
在基础设施方面,从训练到推理的全链路都已适配华为昇腾NPU。自主研发的细粒度专家并行方案“MegaMoE”在NVIDIA GPU和华为昇腾NPU上均实现了高效的加速效果。
DeepSeek-V4相比于之前的版本,在预训练阶段引入了“样本级注意力掩码”,语料库总规模超过32万亿tokens,涵盖数学内容、代码文本、网页数据以及长文档等高质量类别。在后续的微调过程中,则用基于策略的蒸馏取代了混合强化学习方法。
DeepSeek-V4系列在基础设施创新方面表现突出,采用专家混合(MoE)技术并提出了细粒度EP方案“MegaMoE”,该方案通过优化通信与计算过程来实现更高的加速效果和更低的成本需求。DeepSeek还利用TileLang语言进行内核融合,并引入了FP4量化以减少资源消耗。
开源地址:
深耕于长文本处理效率的突破,DeepSeek-V4采用了一系列架构创新措施,使其在面对超长上下文时能够显著提高计算效率。此外,该版本延续了Transformer架构和多Token预测模块的设计思路,并在此基础上引入多项关键改进:混合注意力机制、mHC流形约束超连接以及Muon优化器。
报告地址:
深度学习模型预训练过程的持续优化,DeepSeek-V4不仅在数据多样性方面进行了提升,还在预训练过程中加入了“样本级注意力掩码”,从而进一步提高了模型的能力。通过引入智能体数据和多语言语料库,使得DeepSeek-V4系列具有更强的知识处理能力和代码生成能力。
在长上下文的计算效率上实现了显著突破后,DeepSeek-V4在预训练阶段引入了“样本级注意力掩码”机制,并将训练数据规模扩展至超过32万亿tokens。此外,该模型还在预训练过程中运用了多种高质量类别数据源以增强其知识处理能力和代码生成能力。
后续微调阶段,DeepSeek-V4采用基于策略的蒸馏技术替代之前的混合强化学习方法,并保留了完整的推理历史记录,即使在多轮对话中也能保持上下文连贯性。此外,它还引入了一种新的机制来优化智能体环境中的交错思考效果。
DeepSeek-V4模型不仅在知识处理和代码生成能力方面表现出色,在推理任务上的性能也十分优越,部分功能甚至接近于闭源模型的水平。尽管与最前沿的闭源模型相比仍存在差距,但在开源模型中却占据领先地位。
在测试时扩展、长周期智能体任务以及在线学习等领域,DeepSeek-V4预览版展示出高效的百万级token上下文支持能力,并通过系统级别的基础设施优化和混合注意力架构的应用进一步提升了性能表现。然而,其复杂的架构使得一些稳定性方法如预见性路由等机制有待深入理解。
总体而言,DeepSeek-V4在开源模型中展现出强大的知识、推理以及智能体任务处理能力,并且以较低成本实现了较高性价比的推理效果。未来的工作方向将侧重于简化架构设计、提高训练稳定性和探索更多的稀疏化方法等方面,从而进一步提升长上下文推理效率并增强多轮对话和多模态交互的能力。同时,还将持续改进数据构建及合成策略来不断优化模型性能。
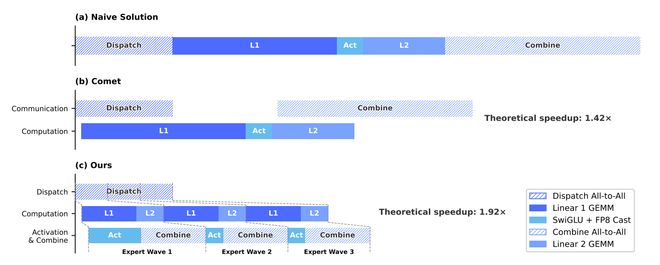
在实际应用中,复杂的模型架构原本会生成数百个细粒度的Torch ATen运算符。为此,DeepSeek采用TileLang开发了一组融合内核,用以替代其中绝大多数运算符,把碎片化的小kernel融成大块,调用开销从百微秒压到1微秒以内,还引入Z3形式化求解器做优化验证。做到比特级可复现,同一token不管在batch哪里都得到同样结果,同一模型每次运行完全一致,这对大模型调试是保命设计。
DeepSeek将FP4(MXFP4)量化应用于两个关键部分:第一是MoE专家权重,这部分是GPU显存占用的主要来源之一;第二是CSA中索引器的Query-Key(QK)路径,在该路径中,QK激活值的缓存、加载以及乘法计算全部在FP4精度下完成,从而在长上下文场景中加速注意力分数的计算。
训练框架建立在为DeepSeek-V3开发的可扩展且高效的基础设施之上。在训练DeepSeek-V4时,DeepSeek继承了这一基础,同时引入了多项关键创新,适配其新的架构组件——包括Muon优化器、mHC,以及混合注意力机制,并在此过程中保持高效的训练效率与稳定性。
二、架构升级,突破长文本计算效率瓶颈
推理模型兴起后,业内建立了一种新的“测试时扩展”范式,显著推动了大型语言模型的性能提升。然而,这种扩展范式从根本上受限于传统注意力机制,难以处理超长上下文和复杂推理过程。
同时,从复杂智能体工作流到大规模跨文档分析,长时序任务的出现,也使得高效支持超长上下文成为未来发展的关键需求。尽管近年来一些开源工作(如DeepSeek、MiniMax、Qwen等)已经推动了模型能力的整体提升,但在处理超长序列方面的核心架构低效问题仍然存在。
DeepSeek-V4为解决这个瓶颈,它通过一系列架构创新,让模型在处理超长上下文时的计算效率大幅提升,从而真正把上下文长度推进到“百万token”这个量级。
总体而言,DeepSeek-V4系列沿用了Transformer架构和多Token预测模块,并在DeepSeek-V3基础上引入了项关键改进:
(1)采用混合注意力架构,将压缩稀疏注意力(CSA)与高压缩注意力(HCA)结合,以提升长上下文处理效率;
(2)引入流形约束超连接(mHC),增强传统残差连接;
(3)使用Muon优化器,实现更快的收敛速度和更高的训练稳定性。
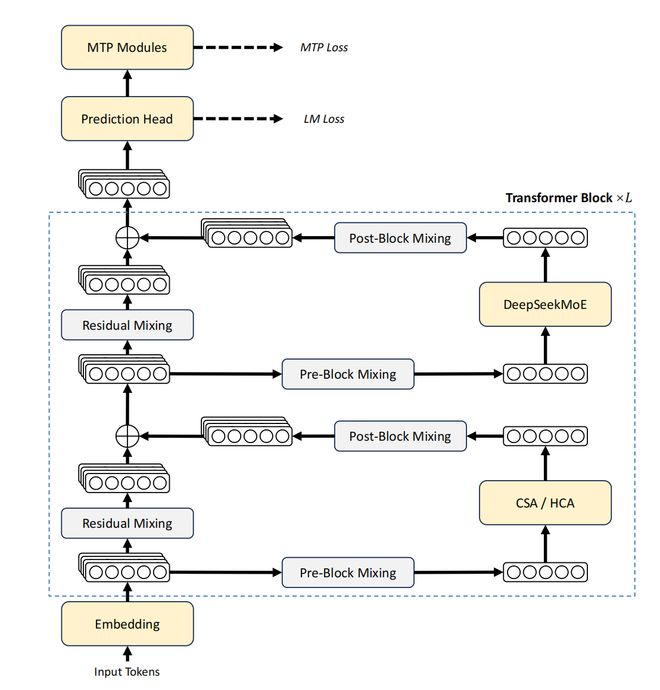
具体做法上,DeepSeek-V4保留了MoE结构和多token预测策略,重点改造了注意力机制:提出一种“混合注意力”,即把两种不同的压缩方式结合起来,一种是先压缩再做稀疏注意力,另一种是更激进地压缩但仍保持稠密计算,这样在保证信息利用的同时大幅减少计算和存储开销。此外,它还改进了残差连接,增强模型表达能力,并引入新的优化器Muon,让训练更快更稳定。
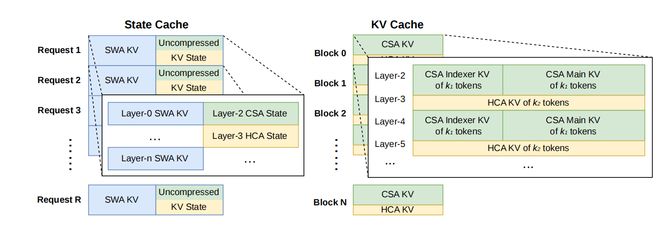
除了模型结构本身,DeepSeek对整个训练和推理系统做了大量工程优化,比如把MoE的计算、通信和内存访问融合在一起执行,用专门的语言优化内核,实现可复现的计算过程,以及通过低精度(FP4)来减少资源消耗。在推理阶段,还设计了更复杂的KV cache存储方式,甚至可以部分放到磁盘上,从而支持极长上下文而不爆内存。
三、预训练:基础模型提升明显,Flash模型就已超V3.2
预训练过程主要基于DeepSeek-V3的数据,同时为构建一个更多样化、高质量且有效上下文更长的训练语料库,DeepSeek持续优化数据构建流程。与DeepSeek-V3不同的是,V4在预训练过程中引入了“样本级注意力掩码”(sample-level attention masking)机制。
对于来自网页的数据,DeepSeek-V4采用过滤策略,去除批量自动生成和模板化内容,从而降低模型崩溃的风险。数学和编程语料仍然是训练数据的核心组成部分,同时DeepSeek在中期训练阶段引入了智能体数据,进一步提升DeepSeek-V4系列的代码能力。
在多语言数据方面,DeepSeek-V4构建了更大规模的语料库,从而增强模型对不同文化中“长尾知识”的理解能力。此外,DeepSeek-V4特别强调长文档数据的构建,优先收集科学论文、技术报告等材料。
综合上述各类数据,预训练语料总规模超过32万亿tokens,涵盖数学内容、代码、网页文本、长文档等多种高质量类别。
对于基础模型的评估,DeepSeek-V4覆盖四个关键维度的基准测试,包括世界知识、语言理解与推理、代码与数学,以及长上下文处理。
DeepSeek-V3.2、DeepSeek-V4-Flash和DeepSeek-V4-Pro的基础模型在统一的内部框架下进行了评测,获得以下结果。
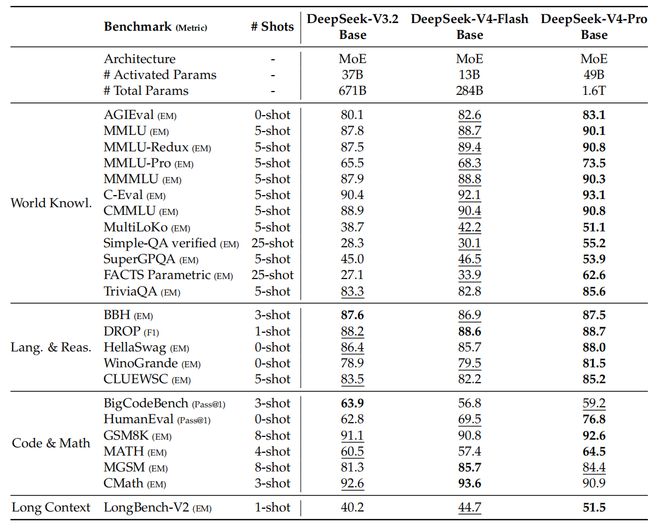
尽管DeepSeek-V4-Flash-Base的激活参数量和总参数量都明显更小,但它在大量基准测试中超过了DeepSeek-V3.2-Base,该优势在世界知识任务和长上下文场景中尤其明显。结果表明,DeepSeek-V4-Flash-Base在更紧凑的参数预算下,也能取得更强性能,在大多数评测中有效超过规模更大的DeepSeek-V3.2-Base。
此外,DeepSeek-V4-Pro-Base能力跃升更为明显,几乎全面领先DeepSeek-V3.2-Base和DeepSeek-V4-Flash-Base,在基准测试上刷新了DeepSeek基础模型的性能上限。它在知识密集型评测和长上下文理解能力取得了显著提升。在大多数推理和代码基准上,DeepSeek-V4-Pro-Base也超过了前两个模型。可以说,DeepSeek-V4-Pro-Base在知识、推理、代码和长上下文能力等多个方面全面超越了前代模型。
四、后训练:基于策略蒸馏,跨轮次保留推理历史
在完成预训练之后,DeepSeek还进行了后训练,最终得到DeepSeek-V4系列模型。虽然整体训练流程在很大程度上沿用了DeepSeek-V3.2的方案,但在方法上做出了一项关键替换:原先的混合强化学习(RL)阶段被完全替换为“基于策略的蒸馏”(On-Policy Distillation,OPD)。
具体做法是,先对每个目标领域各自训练一个独立的专家模型。每位专家都经历相同的流程:先用高质量领域数据做监督微调打底,再用GRPO算法做领域强化学习,这一步会得到十多位各有所长的“偏科高手”。
真正的合并动作发生在第二阶段。DeepSeek-V3.2的做法是把各类数据混在一起做RL,容易互相影响,而V4则换成让统一的学生模型自己采样答题,过程中由这十多位专家老师在完整词表的logit层面打分对齐,用reverse KL损失把学生拉向老师。这种方式保证模型在每个领域的专长都能被完整保留。另外一个关键改动是DeepSeek-V4坚持做全词表蒸馏,进而梯度更稳,训练曲线更可控,但工程难度更高。
依托DeepSeek-V4系列的一百万 token上下文窗口,DeepSeek进一步优化机制,以最大化智能体环境中交错思考的效果。
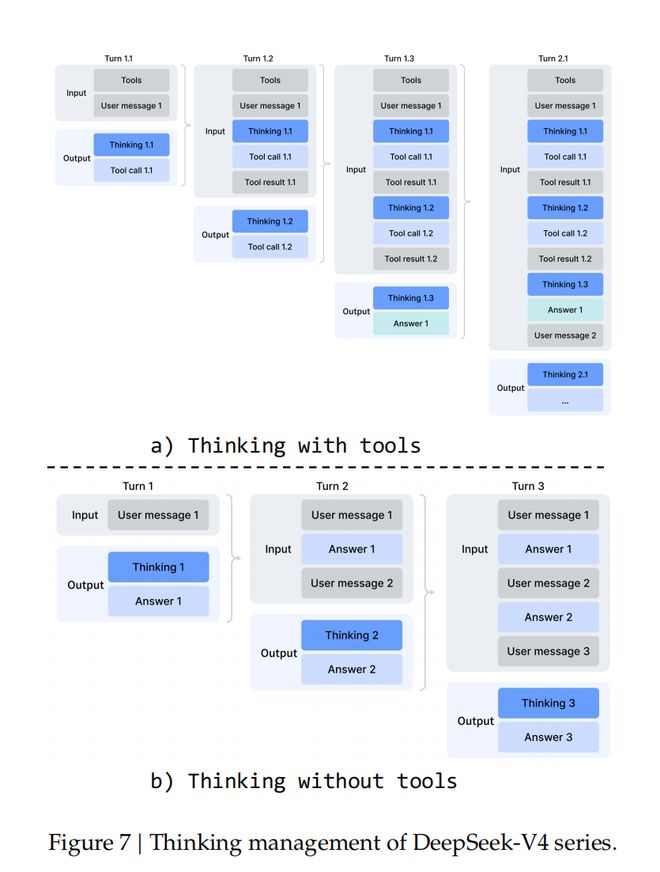
在工具调用场景中,所有推理内容都会在整个对话过程中被完整保留。不同于DeepSeek-V3.2会在每一轮新用户输入到来时丢弃思考轨迹,DeepSeek-V4系列会跨越所有轮次保留完整的推理历史,让模型能够在长周期智能体任务中维持连贯、持续累积的思考链条。
在一般对话场景中,DeepSeek-V4仍然保留原有策略:当新的用户消息到来时,会丢弃上一轮的推理内容,从而保持上下文简洁。
与DeepSeek-V3.2一样,那些通过用户消息来模拟工具交互的智能体框架(例如 Terminus)可能不会触发工具调用上下文路径,因此也可能无法受益于增强后的推理持久化机制。对于这类架构,DeepSeek仍然建议使用非思考模型。
五、知识、推理、代码三线抬升,开源模型逼近闭源上限
评测结果上看,DeepSeek-V4-Pro-Max相比其他开源模型也略有领先,部分能力逼近闭源模型。
在知识能力和推理能力上,DeepSeek-V4-Pro-Max相比其他开源模型略有领先,但仍逊于闭源模型Gemini 3.1-Pro。推理能力上,DeepSeek-V4-Pro-Max优于GPT-5.2和Gemini-3.0-Pro,落后于GPT-5.4和Gemini-3.1-Pro;DeepSeek-V4-Flash-Max与GPT-5.2和Gemini-3.0-Pro能力近似,在复杂推理任务中展现出很高的性价比。
Agent能力方面,DeepSeek-V4-Pro-Max与Kimi-K2.6和GLM-5.1等领先开源模型表现相当,但略逊于最前沿的闭源模型。长上下文能力方面,DeepSeek-V4-Pro-Max在合成任务和真实应用场景中均表现强劲,在学术基准测试中甚至超过了Gemini-3.1-Pro。
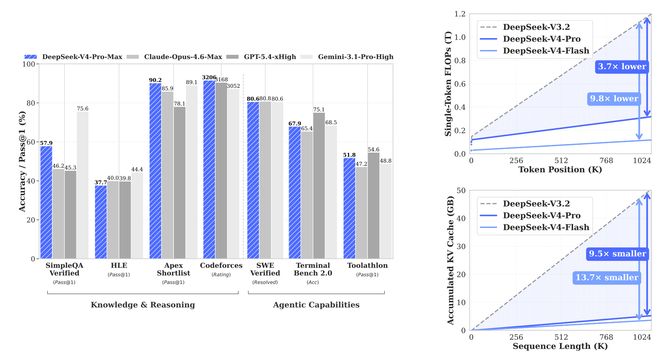
在DeepSeek-V4-Pro与DeepSeek-V4-Flash的对比中,由于参数规模较小,DeepSeek-V4-Flash-Max在知识类评测中的表现略低。但在给予更多推理token时,在推理任务中的表现可以接近DeepSeek-V4-Pro-Max。在智能体评测中DeepSeek-V4-Flash-Max在部分基准上可以达到与DeepSeek-V4-Pro-Max相当的水平,但在更复杂、高难度任务中仍略逊一筹。
结语:高效支持百万级token上下文,后续需简化架构
DeepSeek-V4系列预览版突破了超长上下文处理中的效率瓶颈,其通过融合CSA与HCA的混合注意力架构,并结合系统级基础设施优化,使模型能够更高效地支持百万token级上下文,为测试时扩展、长时序任务和在线学习等方向提供了基础。
从评测结果看,DeepSeek-V4-Pro-Max在开源模型中表现突出,在知识、推理和智能体任务上均取得较强结果,部分能力接近前沿闭源模型。DeepSeek-V4-Flash-Max则在较低成本下实现了较强推理能力,体现出较高性价比。
不过,DeepSeek-V4的架构也较为复杂,部分稳定性方法如Anticipatory Routing和SwiGLU Clamping的机理仍有待进一步理解。后续工作预计将集中在简化架构、提升训练稳定性、探索更多稀疏化方向、降低长上下文推理延迟、增强多轮智能体与多模态能力,以及持续改进数据构建与合成策略等方面。