
DeepSeek发布创新成果!多模态模型研究报告出炉:性能超GPT-5.4
DeepSeek近日在GitHub上公开了一款多模态推理模型及其技术报告《以视觉原语思考》。这个模型基于DeepSeek V4-Flash架构(总计参数量为284B,实际运行时激活的参数数量为13B)开发而成,并提出了一种新的多模态推理方式。研究指出当前市面上的许多大型多模态模型存在一个未被充分重视的问题:“指代鸿沟”(Reference Gap),即尽管这些模型能够识别图像中的内容,但在用自然语
科技7 阅读
共找到 3 篇相关文章
DeepSeek近日在GitHub上公开了一款多模态推理模型及其技术报告《以视觉原语思考》。这个模型基于DeepSeek V4-Flash架构(总计参数量为284B,实际运行时激活的参数数量为13B)开发而成,并提出了一种新的多模态推理方式。研究指出当前市面上的许多大型多模态模型存在一个未被充分重视的问题:“指代鸿沟”(Reference Gap),即尽管这些模型能够识别图像中的内容,但在用自然语

近日,DeepSeek发布了多模态技术报告《视觉原语思考》(Thinking with Visaul Primitives),详细披露了其新推出的识图模式背后的创新机制。该识图模式采用了名为DeepSeek-V4-Flash的基座模型,参数量达到284B,并拥有13B激活多模态推理模型。这一模型尚未正式命名,但DeepSeek已经确认未来会将其整合进基础模型中进行发布。据介绍,传统的思维链主要在语
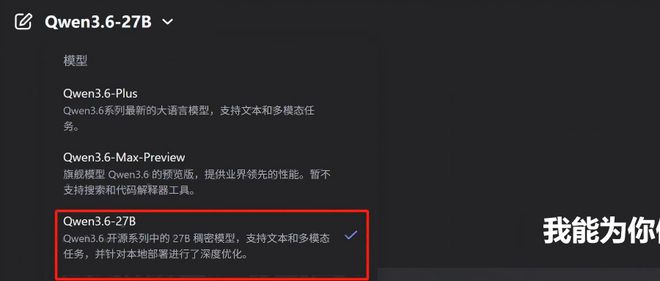
智东西编译 杨京丽编辑 陈骏达近日,阿里通义千问团队发布了Qwen3.6-27B的开源版本——这是一个具有270亿参数的大规模稠密多模态模型,并支持思考与非思考模式。相较于先前推出的Qwen3.5-397B-A17B,新的Qwen3.6-27B虽然在参数量上仅为前者的十分之一,却在编程性能等多个关键指标上实现了超越。其不仅显著提升了编程能力,在文本和多模态推理方面也表现出色。与同级别的Ge