
昨日,美国存储股集体遭遇重挫。统计数据显示,闪迪股价一度下跌6.5%,希捷科技跌幅超过5%,西部数据和美光科技分别下跌4%以上。
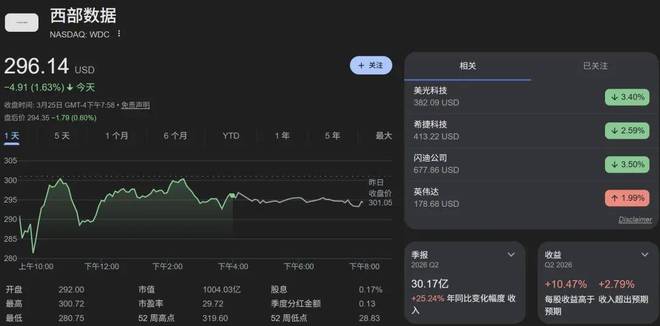
这次内存股暴跌的原因竟然只是谷歌发布的一篇新博客。这篇博客介绍了一年前谷歌在arXiv上发布的一项技术:TurboQuant。

- 该技术的论文标题为《TurboQuant: 在线向量量化,接近最优失真率》。
- 该论文地址为 https://arxiv.org/abs/2504.19874。
TurboQuant是一种压缩算法,能够将大语言模型(LLM)的KV缓存内存占用降低至少六倍,同时提高速度八倍,且精度无损。
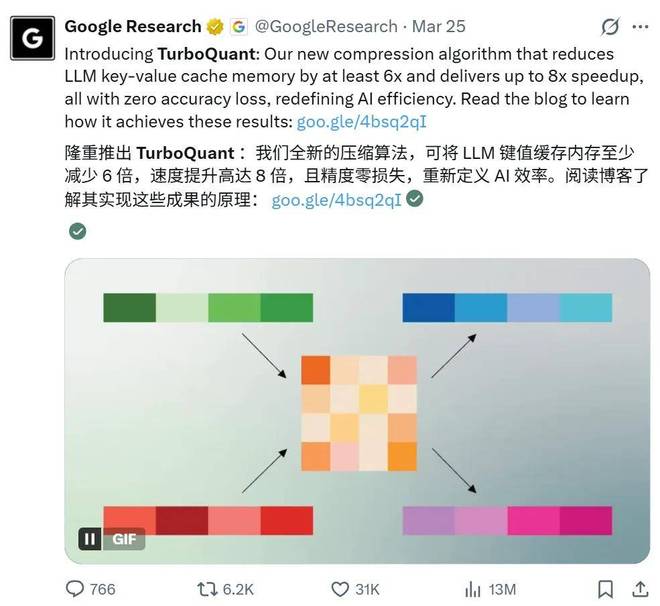
技术博客地址为 https://research.googleblog.com/turboquant-redefining-ai-efficiency-with-extreme-compression/。
该事件引发了一些投资者和网友对金融市场非理性表现的吐槽。



那么,TurboQuant究竟是什么?为何这项技术发布一年后依然能引起如此大的轰动和市场波动?
了解TurboQuant,还得从KV缓存说起。
KV 缓存简介
KV缓存是一种数据结构,当大语言模型生成文本时,它需要记住之前生成的每一个词语的上下文信息。为了实现这一点,模型会将这些历史信息的键(Key)和值(Value)保存在内存中,这就是所谓的KV缓存。
这就像模型在记忆中存放了一张“小抄”。随着用户输入的提示词越来越长,或者模型的层数和注意力头数增加,这张“小抄”的体积也会相应增大。
为了保证模型运行的流畅性,硬件厂商和AI公司不得不持续投入昂贵的高带宽内存(HBM)。
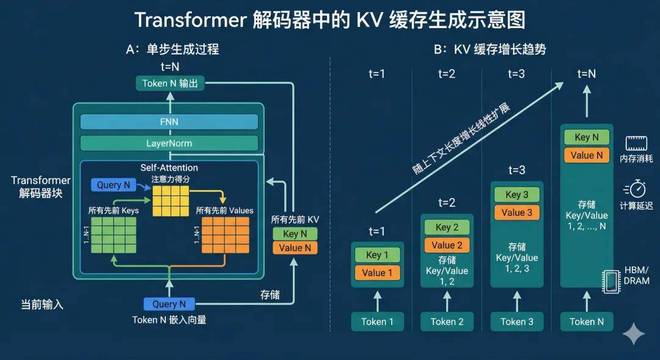
Gemini生成的示意图
因此,在此之前,人们对内存芯片的需求预期非常乐观。
TurboQuant:简化存储难题
大模型要变得更智能,其向量维度就需要增加。然而,传统的向量压缩技术(量化)有一个缺点:它们通常需要为每个小数据块计算并存储全精度的量化常数。
这类似于为了把一件大衣服塞进行李箱,你不得不另外带一本厚重的“折叠指南”,反而会增加额外的内存消耗,削弱了压缩的初衷。
为了解决这个问题,TurboQuant设计了一套精妙的两阶段压缩架构。
第一步:换个角度看数据
第一阶段的核心在于优化均方误差(MSE)。
TurboQuant会对高维输入向量进行“随机旋转”。这一操作简化了数据的几何结构。
在PolarQuant机制下,就像将原本复杂的坐标系简化为“以37度角,总共走5个街区”的极坐标表示。

PolarQuant充当了高效的压缩桥梁,将笛卡尔坐标输入转换为紧凑的极坐标“速记符”,以进行存储和处理。这一机制将高维向量的坐标分组并映射到极坐标系中,随后收集成对的半径进行递归式的极坐标变换,直至整个数据被简化为单一的最终半径和一组描述性角度。
这样一来,信息被清晰地拆解为代表核心数据强度的“半径”和代表数据方向的“角度”。经过旋转,所有坐标呈现出一种集中的Beta分布。
在高维空间中,不同坐标之间的相关性变得几乎独立。由于角度分布明确且集中,模型可以直接将数据映射到一个固定的“圆形”网格上,完全省去了数据归一化的复杂计算。
在这一阶段,TurboQuant投入大量算力,对向量的每个部分单独应用高质量量化器,锁定原始向量的核心特征,同时削减了不必要的内存消耗。
第二步:1 bit算力实现的神级校准
完成了初步的压缩,新的问题随之而来:只追求MSE最优的量化器在估算大模型最依赖的“内积”时,会产生严重偏差。
这时,TurboQuant展示了它的第二项技能:Quantized Johnson-Lindenstrauss变换(QJL)。
TurboQuant利用仅有的1 bit空间,专门处理第一阶段剩下的微小残差。
QJL就像一个精密的数学误差检查器。它能够简化复杂的高维数据,同时保持数据点之间的基本距离和关系。它将最终的向量数字简化为单个符号位(即+1或-1)。
这相当于为模型提供了一套快速且内存消耗极低的“速记法”。通过巧妙地平衡高精度查询请求与简化版数据,模型能够极其精准地计算注意力得分。
正是这关键的1 bit,成功构建了一个无偏的内积量化器,彻底消除了之前的计算偏差。
内存价格能下来吗?
为什么这项技术足以震撼硬件市场?看看它在极限测试中的表现就清楚了。
在处理超长上下文的任务中,TurboQuant在将KV缓存压缩超过5倍的情况下,仍能保持完美的召回率。在普通生成任务中,即使使用极致的3.5 bit压缩比,它也能保持质量无损。
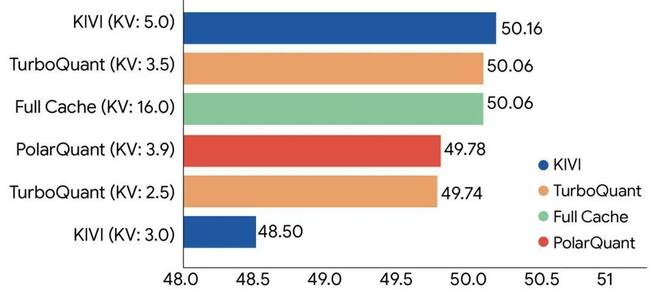
基于Llama-3.1-8B-Instruct模型,在LongBench基准测试中,TurboQuant展示了强大的KV缓存压缩性能(括号内标注了具体位宽)。
工程师们已经成功地在vLLM中实现了TurboQuant,并验证了其效果。他们兴奋地分享说:“我现在可以将4,083,072个KV缓存token装进一个USB充电器大小的HP ZGX上,这可能是2026年迄今为止最大的开放式推理突破。”

在另一个实现案例中,研究者在苹果MLX中实现了TurboQuant,同样取得了卓越的成果。

除了保持性能,它还非常快。
由于底层采用了高度适配现代AI加速器的设计,在H100 GPU上,使用4 bit版本的TurboQuant计算注意力逻辑的速度比传统的32 bit无量化版本快了整整8倍。
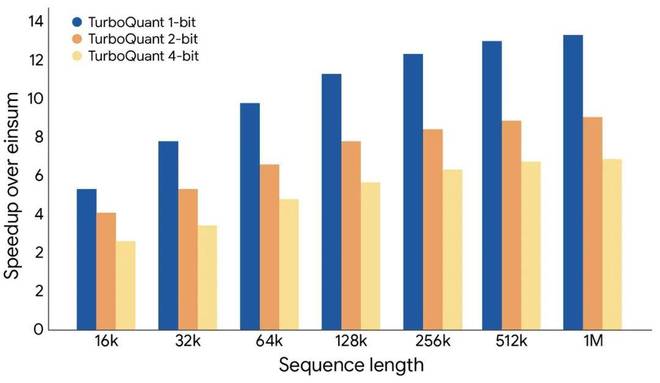
相较于高度优化的JAX基准,TurboQuant展示了在不同位宽级别下,在KV缓存内计算注意力logits时的大幅性能提升。

在使用4位量化时,不同方法在各个维度上的量化时间(以秒为单位)。
在向量数据库和搜索引擎非常看重的最近邻(NN)搜索领域,它不仅在召回率上轻松击败了现有的乘积量化(PQ)技术,还将庞大的索引构建时间压缩到了几乎为零。
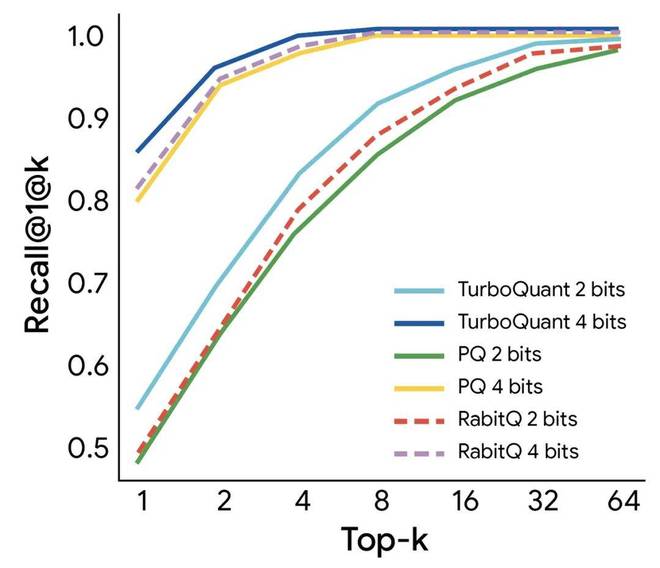
TurboQuant在GloVe数据集(d=200)上相对于多种最先进的量化基线,实现了最优的1@k召回率。
这意味着,原本需要8张高端显卡才能运行的超大模型,现在可能只需要两三张卡就能流畅运行。
如果这项技术能够普及,AI公司在推理端的硬件成本可能会降低。这种技术突破,有望改变市场对内存芯片需求快速增长的预期。
谷歌仅凭一些数学公式,就成功缓解了人们对硬件算力的需求焦虑。
不过,内存、GPU、CPU等的价格似乎仍在继续上涨,可参考《继GPU、存储暴涨之后,AI最终攻陷CPU市场》。
https://x.com/IntuitMachine/status/2036899927465308617
https://x.com/jukan05/status/2036800675158573294
https://x.com/Prince_Canuma/status/2036611007523512397
https://x.com/vllm_project/status/2036989821156270501