英伟达重新审视AI总体拥有成本(TCO),强调每Token费用的重要性。
 梦晨
梦晨当前,数据中心的主要任务已从传统的数据存储和处理转变为生成智能信息的Token形式。
在生成式与代理式人工智能的推动下,这些设施已经演变成大规模生产AI Token的工厂。随着AI推理成为核心工作负载,它们的主要产出就是以Token形式存在的智能。
这种变化促使企业重新评估AI基础设施的成本效益分析方法,不再仅仅关注芯片性能或每美元FLOPS等指标。
关键区别在于:
企业在使用云服务提供商或者本地部署时所支付的算力费用,构成了他们的成本之一。
每美元FLOPS衡量的是投入一元资金所能获得的基本计算能力,但这并不直接反映实际产出Token的数量和效率。
相比之下,每Token成本则更全面地反映了生成每个Token所需的综合支出,通常以百万Token为单位进行评估。
传统上对芯片性能的过度关注忽略了真正的商业目标——提高Token产量。这意味着单纯优化硬件投入并不能直接提升业务效益。
每Token的成本是衡量AI系统效率的关键指标,它能全面反映从硬件到软件再到生态系统支持的整体表现,英伟达在这方面达到了行业的最低水平。
那么哪些因素能够降低每Token成本呢?
要理解优化策略,首先要掌握计算“每百万Token成本”公式的细节。

企业往往只关注公式中的分子部分——即每GPU小时的成本。然而,真正影响整体效率的是分母,也就是最大化实际Token产出。
分母代表了两个重要的商业意义:
首先,它意味着提高Token产量可以显著降低每个Token的成本;其次,增加每秒交付的Token数量能够直接提升收入水平。
因此,只关注成本投入而忽视产出是片面的。这就像冰山一样,可见的部分只是表象,水面下的部分才是决定实际效益的关键因素。
评估AI基础设施时,应该深入探究影响产出效率的因素。

表层问题:
GPU每小时的成本是多少?
峰值PetaFLOPS性能和内存带宽容量如何?
每美元能获得多少浮点运算能力(FLOPS)?
深度成本分析:
生成每个百万Token需要多少成本,特别是对于混合专家模型来说?
每兆瓦可以产生多少Token产出?尤其是在本地部署中,最大化每兆瓦的智能产出至关重要。
纵向扩展互连能否支持大规模混合专家(MoE)推理所需的全面通信模式?
平台是否支持FP4精度运算,并能在保持高性能的同时有效利用这一精度?
运行环境是否具备投机解码或多Token预测功能,以提升用户体验?
服务层是否提供了解耦服务、KV感知路由及缓存卸载等优化措施?
平台能否满足代理式AI所需的低延迟、高吞吐和长输入序列长度的需求?
系统是否支持从训练到推理的全生命周期管理,并兼容各种模型架构,以实现基础设施的最大化利用?
所有这些优化措施必须相互配合并有效集成,否则无法达到预期效果。即使是一块看似更经济实惠的GPU,如果其Token产出效率低下,则会导致整体成本上升。
为什么说每Token的成本比FLOPS指标更重要?
DeepSeek-R1 AI模型的数据展示了理论性能和实际商业效益之间的巨大差距。
尽管NVIDIA Blackwell平台的算力成本大约是Hopper的两倍,但其在真实应用场景中的表现远超预期:Blackwell每瓦Token产量比Hopper高出50多倍,并且每百万Token的成本也大幅下降至原来的十分之一左右。
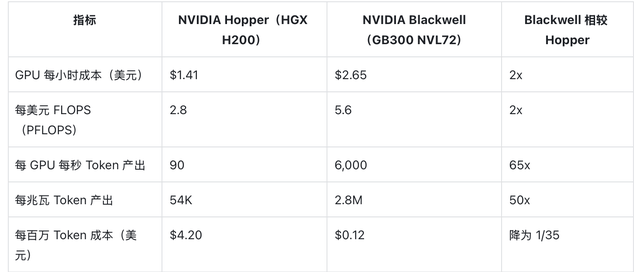
这些数据证明了NVIDIA Blackwell平台相对于上一代产品,在商业价值上的显著提升,远远超过了成本的增加幅度。
企业在选择AI基础设施时应该怎样做?
算力成本或每美元FLOPS等传统指标已经不足以全面评估AI系统的实际性能和盈利能力。正确的做法是关注每Token的成本及其产出效率。
NVIDIA通过在计算、网络、内存、存储、软件及合作伙伴技术上的协同设计,实现了业界最低的Token生成成本与最高的吞吐量。持续优化开源推理软件也意味着现有部署后仍能进一步降低Token成本。
例如CoreWeave、Nebius和Together AI等领先的云服务提供商已经通过部署NVIDIA Blackwell基础设施,成功降低了Token成本并提升了整体效率,充分展示了这一优势。
领先的云服务提供商与 NVIDIA 云合作伙伴,已在规模化部署中充分体现这一优势。包括 CoreWeave、Nebius、Nscale 与 Together AI 在内的合作伙伴,已部署 NVIDIA Blackwell 基础设施,并对其技术栈进行了优化,为企业提供当前最低的 Token 成本,同时充分发挥 NVIDIA 在硬件、软件与生态系统协同设计方面的全部优势,使每一次 AI 交互的处理都建立在这一完整体系之上。