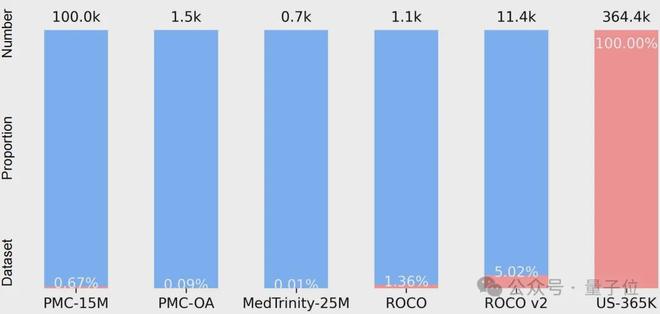
中国团队打造全球首个人工智能超声影像大数据平台,含36.4万例图像与文字资料
超声领域迎来大型预训练模型!实时且无辐射的超声影像,已成为临床诊断的重要手段。然而,异质化的解剖结构和多样的诊断属性使得通用视觉语言预训练模型难以直接应用,加之现有医疗跨模态数据中用于超声样本的比例不足5%,成为该领域研究的关键瓶颈。为了克服这些挑战,浙大城市学院联合浙江大学、香港城市大学及多家附属医院等机构,建立了首个大规模的专用于超声影像的数据集US-365K,并提出了专门为超声设计的语义感知
科技16 阅读
共找到 4 篇相关文章
超声领域迎来大型预训练模型!实时且无辐射的超声影像,已成为临床诊断的重要手段。然而,异质化的解剖结构和多样的诊断属性使得通用视觉语言预训练模型难以直接应用,加之现有医疗跨模态数据中用于超声样本的比例不足5%,成为该领域研究的关键瓶颈。为了克服这些挑战,浙大城市学院联合浙江大学、香港城市大学及多家附属医院等机构,建立了首个大规模的专用于超声影像的数据集US-365K,并提出了专门为超声设计的语义感知

这篇文章是一次采访,主要讨论了人工智能(AI)领域的最新进展及未来趋势。受访者是OpenAI的首席技术官Greg Brockman,在这次访谈中他分享了自己的见解和展望。Greg介绍了自ChatGPT发布以来,人们对AI的态度有所改变,并且强调模型现在能解决的问题范围越来越广。他认为随着能力的进步,AI将带来巨大的经济转型机会。采访中提到OpenAI最近完成了一轮110亿美元的融资,这些资金主要用
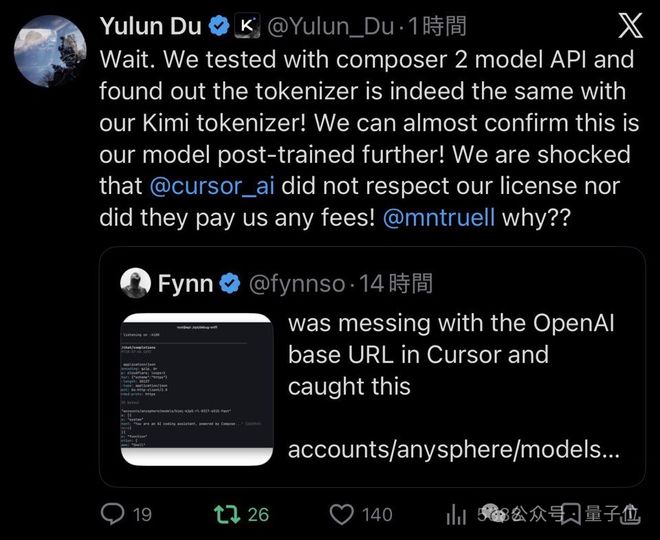
最近,关于开源模型的争议再次引起广泛关注。这次,事件的焦点集中在一家国产开源模型与硅谷初创公司之间。值得注意的是,双方在这次事件中的立场似乎发生了转变。月之暗面的预训练模型负责人杜羽伦,直接点名Cursor的CEO Michael Truell,质问其为何没有遵守许可协议且未支付任何费用。月之暗面的另一位联合创始人周昕宇也对Cursor进行了严厉批评。周昕宇表示,他不记得Cursor曾经向他们申请

大规模预训练模型虽然表现出色,但在处理“长对话、多轮交互和跨任务”等复杂场景时,依然面临两大挑战:其一为上下文窗口的限制,在对话持续增长的情况下容易出现信息过载;其二是中间环节的信息丢失问题,即便能容纳所有数据也不一定能有效利用。因此,引入“外部记忆系统”成为必要:将对话内容储存于长期记忆,并在需要时进行检索。然而这一方案的实际应用却带来高成本的问题:频繁调用大模型执行总结和提取、实时解决冲突以及