
最近,一家名为 Generalist AI 的公司发布了他们的 GEN-1 模型,这在具身智能领域引起了轰动。该公司首席执行官佩特·弗洛伦斯甚至认为机器人技术即将迎来类似“ChatGPT时刻”的突破。
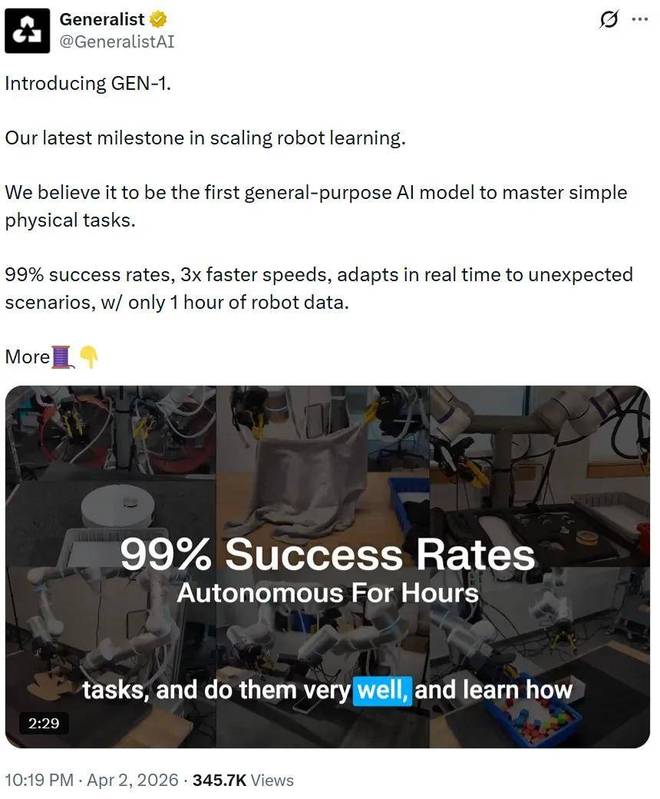
根据 Generalist 官方资料,GEN-1 在多个任务上达到了99%的成功率,并且比以往快了三倍的执行速度。此外,它还具备处理意外情况的强大恢复能力。这些显著的特点表明具身基础模型首次接近了一个重要的门槛,正在从简单的演示阶段稳步迈向可商业化的部署阶段。
人们不禁要问:这种新一代的物理AI是如何被训练出来的呢?
行业内消息显示,这一轮技术飞跃的背后支撑是全新构建的数据和仿真基础设施体系。这其中光轮智能也是关键参与者之一。
GEN-1 的出现预示着具身智能的竞争焦点将从模型层面转向背后支持的基础设施层。
近年来,国内外企业纷纷加速布局机器人领域,如字节跳动、阿里等国内巨头和OpenAI、DeepMind及英伟达等海外公司。这表明建立底层体系已经迫在眉睫,而竞争的核心也逐渐转移到了能够支撑模型快速迭代的基础架构层面。
不只是模型能力提升
竞争格局已然改变
评估 GEN-1 的影响时,我们需要超越常规版本更新的思维框架,去思考更深层次的意义:GEN-1 将具身基础模型从验证机器学习能力阶段推进到了接近商业化部署的实质性门槛。
超高的成功率、快速执行能力和应对突发状况的能力是其中最重要的三个突破点。
这表明行业关注的重点已经转向了模型的稳定性和效率,以及在面对现实偏差时的鲁棒性。
一旦模型跨越初始可用性的门槛,行业的主要矛盾也将随之改变。
接下来的挑战是如何让模型持续且稳健地进步。关键问题将包括获取更大规模、高质量和多样化的数据;确认模型是否真正改进;在更广泛的场景下暴露错误模式并形成反馈闭环等。
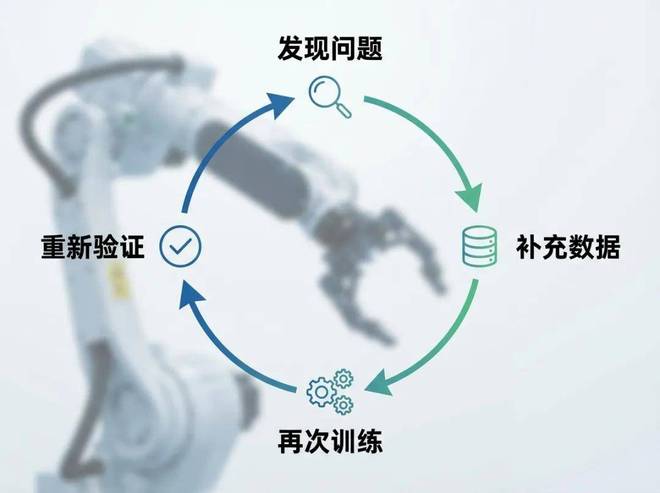
因此,我们可以得出结论:现在这个行业稀缺的资源已经超越了单纯更强的模型本身,而是支撑模型不断进化的基础设施能力。这使得具身智能的竞争开始向产业链上游转移,基础设施层面成为了新的核心战场。
张小珺最近与光轮智能CEO谢晨的访谈中对此进行了深入探讨,并提供了关于具身智能数据基础设施的重要洞见。
模型能力跃迁之后
行业关注如何获取能力
在张小珺对光轮智能CEO谢晨进行的一次深度对话中,为我们解读了这种变化背后的关键视角。
谢晨提出了一个引人深思的类比:将数据与教育行业相提并论。他认为,“如果从第一性原理来思考,我认为数据就像人的教育行业一样,是模型学习的基础。”

这种新的理解方式揭示了具身智能成功不再简单依赖于大量数据;相反,关键在于第一次构建了一个真正的学习系统。
在这个复杂的学习过程中,采集什么样的数据、保留哪些行为、强化哪些失败案例以及优化何种能力都变得有条不紊地进行。
数据正在从静态的数据集向动态的教育体系转变。
谢晨详细解释了这一过程:从早期机械视觉时代类似填鸭式的静态数据集,到后来的大规模工业化生产阶段,再到当前需要反馈驱动的大模型时代。他总结道:“数据应该是帮助模型学习和传递经验的方式。”
数据的功能正在朝向更有针对性的指导发展。传统机器人训练追求完美的轨迹,在现代具身模型中完美变得不再绝对。
谢晨分享了为客户提供服务的经验,指出有效的数据往往源自先失败再成功的案例。“那些包含纠错过程的数据实际上最有价值。”他说道,“这些错误能帮助机器在非结构化环境中随机应变。”

在这个新阶段,行业内出现了一批新的能力体系。这些超越单纯提供数据的系统致力于构造整个学习流程。
隐性的瓶颈
评测与仿真基础设施
谢晨认为,当今具身智能不再仅仅依赖单一模型算法,而是包括了数据、评估机制和反馈等多方面的综合支撑。
这些核心元素共同构成了学习基础设施(learning infra),在模型能力较弱时是隐形的;但当模型变强后,这套系统就成为了行业发展的一大瓶颈。
最为关键的是评测环节
谢晨指出:“如果是具身智能的话,现在最关键的问题就是评估。”

缺乏大规模的评估机制意味着无法准确判断模型的进步和存在的问题。
正如谢晨所强调,“如果这个问题解决不了,大家就很难衡量具身智能的进步。”这构成了一个核心瓶颈。
在仿真环境中建立类似自动驾驶“影子模式”的评价体系是跨过预训练阶段的唯一途径。
同时数据本身也在经历深刻的变化。具身智能的发展不再依赖于硬件数量,而是转向一种全新的演进路径。
谢晨观察到:“最大的具身数据并不一定来自本体商。”这意味着,支撑通用模型的最大规模数据已经脱离了对特定硬件的依赖,可以构建起真正可规模化评测与学习闭环环境。
没有高精度仿真环境的支持,行业将无法建立大规模评估和学习反馈循环。这促使整个产业意识到优秀的模型本身已难以成为单一竞争壁垒,决定智能的关键要素已经转向了数据引擎、仿真及评测系统等基础设施。
在这种理论框架下,未来真正稀缺的能力在于持续构造有效的学习信号,并能够揭示失败模式并转化成可评估的问题以形成迭代反馈闭环。
谢晨在访谈中对“data factory”和“data engine”的区分也愈发重要。前者偏向于流水线生产;后者则是一个通过反馈驱动的学习引擎。
他认为:“我希望将其定位为一个 data engine。”他进一步解释说,“它不是一个简单的工厂,而是一个基于反馈驱动迭代的系统。”
终极需求将集中在能够自我进化的数据引擎、仿真环境和评估体系上。传统的data factory模式可能会被淘汰。
真正稀缺的不是数据
而是「数据引擎」
光轮智能这样的公司也转变了角色,从传统意义上的供应商变成了提供核心基础设施支持的角色。
谢晨定义自身企业时强调:“我们是一个以系统为核心、通过帮助客户发现问题并基于反馈提升能力的企业。”
GEN-1 明显标志着一个新的起点,但它并没有解决所有问题,也未让具身智能一步跨入大规模商业化阶段。
然而,它确实表明了具身智能正在经历从“模型驱动”向“基础设施驱动”的重大转变。在这个新的阶段里,决定未来的不再是单一更强的模型,而是能够持续支撑学习发生的系统本身。
谢晨曾将仿真比作“时间机器”,但现在他认为,对于机器人而言,仿真是一个先决条件。“智能越强,对数据的需求反而成倍增加。”这也体现了整个行业从狂热追求模型到深耕基础设施的转变。他总结说:“我觉得仿真是能够解决具身数据问题的基础。”

面向未来,谢晨描绘了一个既科幻又理性的终局形态:智能越强,对数据的需求会成倍增加;最终AI可能会存在于庞大的仿真环境中,基于明确的成功指标不断自我博弈、修炼内功。这也再次证明了Generalist的跃升背后是厚实基础设施的支持。
谢晨在定义自身企业时提到:「我们是一套以系统驱动的、以系统和评测为中心的…… 通过帮助客户的模型发现问题,并且基于这些有效的反馈和经验帮助他们提升的能力。」
从模型时代
进入基础设施时代
GEN-1 显然意味着一个新的起点,它尚未解决所有难题,也未能让具身智能一夜之间跨入大规模商业化阶段。
但它已经足够说明一件事:具身智能正在经历从「模型驱动」向「基础设施驱动」的深刻转型。在这个阶段里,决定智能上限的关键要素已经转变为那套让学习持续发生的系统,单独的一个更强模型无法支撑起行业的未来发展。
谢晨曾把仿真比作「时间机器」,认为它只是个加速器。但现在他认为,对于机器人而言,仿真是一个「先决条件」。这种认知的转变,本质上也是整个行业从模型狂热转向基础设施深耕的缩影。谢晨在总结这套基础设施的核心地位时强调:「我觉得仿真是真正能够解决具身数据问题的基石,或者说仿真是整个具身智能学习所需要的前提条件。」
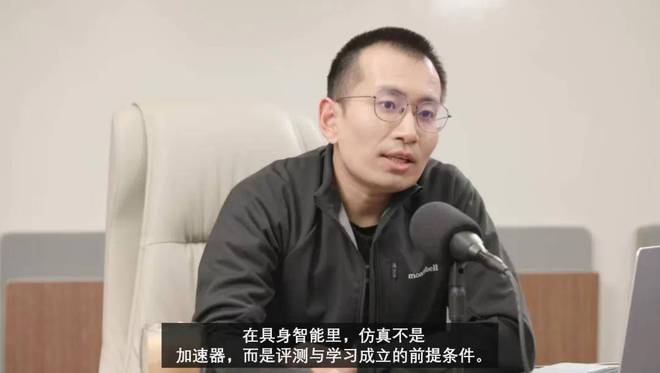
面向未来,他描绘了一个更具科幻感却也极为理性的终局形态:「智能越强,对于数据的饥渴程度反而会成倍增加。到了最后,AI 可能会像马斯克设想的那样,处在一个庞大的仿真环境中,基于既定的成功指标,不断地自我博弈、修炼内功。」这也再次印证了一个结论:Generalist 的跃升只是结果,基础设施的厚度构成了其背后的真正原因。