SpaceX董事会已批准一项针对创始人马斯克的高额薪酬计划,旨在支持其火星殖民和太空数据中心的目标。与此同时,在一场关于OpenAI未来的关键庭审中,马斯克出庭作证,并强调了人工智能技术的慈善初衷。
SpaceX披露
马斯克与SpaceX之间的绩效薪酬方案
SpaceX董事会最近批准了一项旨在激励公司创始人马斯克实现远大目标的薪酬计划。据向美国证券交易委员会提交的文件显示,该计划的目标包括在外太空建立数据中心和在火星上建设永久性人类居住区。
根据年初设立的规定,如果SpaceX市值达到7.5万亿美元,并且能在火星上创建一个至少容纳100万人的殖民地,马斯克将获得2亿股具有额外投票权的B类股票。此外,在外太空运营的数据中心若能提供相当于十万个一吉瓦核电站总功率的计算能力时,他还将额外得到6040万股限制性股票。

关于马斯克出行的画面资料
上述奖励形式均为具有10票投票权的B类股票。如果公司未能达到董事会设定的价值目标,则马斯克将无法获得任何股份。自2019年以来,他每年从SpaceX领取名义薪酬为5.408万美元。目前,SpaceX计划在6月28日左右进行首次公开募股(IPO),估值可能约为1.75万亿美元。
企业治理专家认为,马斯克的精力主要被特斯拉和SpaceX两家公司争夺。这两家公司都为他制定了特殊的绩效薪酬方案。如果两大目标均达成,他的财富或将翻倍。
OpenAI庭审:
马斯克在OpenAI庭审中捍卫慈善初衷
在继续推进火星计划的同时,马斯克于28日在一场涉及OpenAI未来的重要庭审中出庭作证,并表示自己的诉讼旨在保护人工智能技术的公益性质。他批评OpenAI及其联合创始人背弃了最初的非营利使命。
马斯克在开庭第一天作证时提到,OpenAI是由他发起、命名并提供初始资金支持的一个项目,其初衷是为了不以个人利益为目标而造福人类社会。
在庭审开始前的准备阶段,美国地方法官罗杰斯提醒马斯克注意社交媒体上的言论。此前有报道指出,他曾将奥尔特曼称作“诈骗者”,并指控他掠夺慈善资源。

奥尔特曼的资料照片
在庭审开始前,OpenAI及其律师强调,自2019年3月以来,该公司已转变为盈利机构,并在吸引包括微软在内的投资者后逐渐扩大规模。他们认为马斯克是出于未能实现掌控整个公司而提起诉讼。
马斯克指控被告方违反了最初设立的非营利使命,并要求赔偿巨额损失用于慈善事业;同时希望OpenAI恢复为一个非盈利组织,撤换现有高层管理人员和董事会成员。
此次庭审不仅揭示了OpenAI从一个小规模实验室发展成为一家价值超过8500亿美元大公司的过程,还可能影响其未来的公开上市计划,并增加了公众对于人工智能技术发展的担忧。
马斯克在社交媒体上为中国模型点赞
近期,有关中国大型语言模型的崛起引发了美国硅谷内部的不同反应。
在几天前,一位知名科技公司CEO批评了多家中国开源模型企业模仿其产品并指责它们剽窃技术成果。然而,在3月2日晚些时候,马斯克在社交媒体上为中国的大模型点赞,并称它具有“令人惊叹的智能密度”。
表面上看,这只是马斯克的一次随意点评,但实际上却触动了美国AI公司的痛点。
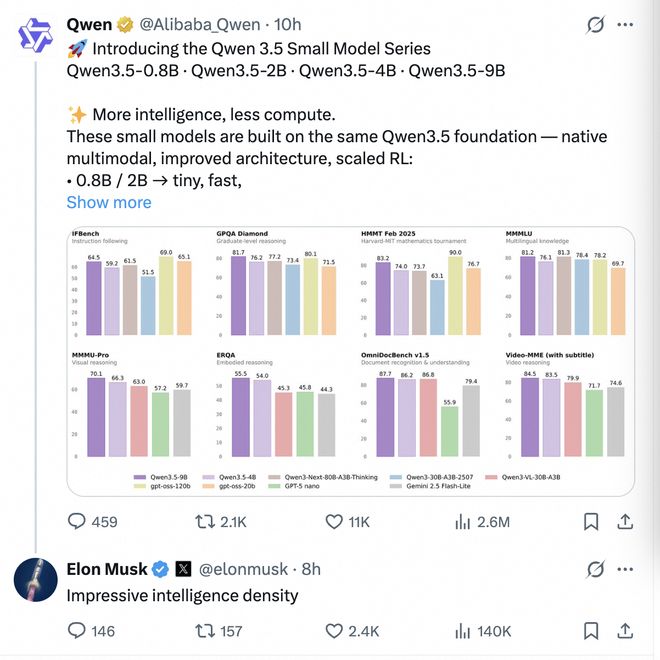
业内专家指出,“智能密度”是衡量大型语言模型效率的关键指标。而马斯克多次强调这一概念的重要性,并认为其潜力被低估了一个数量级。
马斯克称赞中国大模型的“智能密度”,意味着他对其技术能力的认可,而非简单的商业互捧行为。
从堆参数到堆密度
与此同时,在大洋彼岸,另一家AI创业公司的创始人也在财报电话会议上提到了这一概念。他认为公司未来的核心战略就是提升智能密度和处理能力。
这一系列事件表明,“智能密度”正成为行业内的共识性话题。
在过去三年里,人工智能领域主要以军备竞赛为主导,各家公司竞相扩大模型的参数规模和计算资源投入。然而,这种发展模式已经逐渐失去了效率,因为增加十倍的参数量只能带来两成左右性能提升而成本却大幅上升。
但与此同时,“智能密度”这一概念正在被越来越多的人所关注。
清华大学刘知远教授团队的研究表明,GPT-3.5级模型的API调用价格在过去两年内下降了约267倍。这不仅反映了技术进步带来的成本降低,还预示着一种全新的发展趋势——即通过提高智能密度来实现更高效的AI应用。
一些美国科技公司高管认为中国大模型只在基准测试中表现出色而缺乏实际用途。然而马斯克却对中国的大规模语言模型表示赞赏。
这种对立反映了中美公司在人工智能领域的竞争态势:一方面是中国的创新和效率,另一方面则是美国公司的技术领先地位与市场控制力之间的矛盾。
马斯克点赞中国大模型的同时也在间接向同行发出警告——他们所面临的挑战正来自于那些以前被认为不值得重视的小型竞争对手。
千问3.5的发布是“智能密度”理论实践中的一个重要案例。其九亿参数量级的大语言模型在多项基准测试中表现优异,甚至超越了更大规模的产品,并且能够在普通手机上运行。
这一现象预示着未来人工智能技术将更加普及化和大众化,从而彻底改变科技行业的格局。
千问团队在过去两周内连续发布了九款不同规格的开源模型,在各自参数级别中表现出色。这一成就体现了智能密度提升所带来的巨大潜力和市场机遇。
刘知远教授曾预言:“只要能实现某种智能,未来一定可以在更小的终端上运行。”
千问3.5的成功实践再次印证了这一点:仅需九亿参数量便能达到十倍规模模型的效果,并且能够在普通手机等个人设备上高效运行。
小模型也能够实用
但并非所有人买账。
这种技术进步意味着AI应用门槛从大规模计算资源转向更低成本和灵活度更高的平台,从而极大地推动了创业公司进入市场的可能性。
MiniMax的成功案例展示了小型团队如何通过提升智能密度实现与大型竞争对手匹敌的技术水平,并取得显著业绩增长。
当今全球有超过七十亿部手机,而每一部都可能成为运行AI应用的新平台。这意味着未来的智能技术将呈现出高度分布化的特征。
“智能密度”不仅仅是一个技术概念,它还预示着人工智能在未来如何以更低的成本触及每一个人的生活和工作环境。因此,“谁的模型今天更强”的问题已经不再重要;关键在于“AI将以何种形式、多低的成本来到每个普通人身边”。
马斯克点赞中国大模型的实际意义是在确认一个正在发生的转折:在人工智能领域,未来的竞争将不再是看谁能拥有最大的模型,而是谁能在更小的硬件上实现更高的智能密度。这一趋势不仅会改变技术发展的路径,还将深刻影响整个科技产业和社会生活的方方面面。
当然,争论归争论,密度法则给出的数字是冷冰冰的:据论文统计,GPT-3.5级模型的API调用价格在短短20个月内下降了266.7倍。这不是某个人的观点,这是技术通缩规律。
争论可以继续。曲线不等人。
千问3.5的小模型,就是这条密度曲线上最新的那一个数据点——也是最让人不敢忽视的那一个。
先说一个最直观的事实:一年前需要整个服务器集群才能跑的能力,现在装进了手机。
9B参数量的千问3.5,在多项基准上性能媲美甚至超越十倍参数量的模型:GPQA Diamond得分81.7,指令跟随91.5,视觉理解在MMMU-Pro上以70.1 vs 57.2大幅领先同级别的GPT-5-Nano。最夸张的是,不到10亿参数的0.8B模型,能一口气处理26万token的超长上下文——相当于两三本长篇小说的体量,跑在一部普通手机上,而不是发热的服务器机房里。
千问团队在16天内连发9款模型,全部Apache 2.0完全开源,每一款都在各自参数级别称王。这不是一款产品的胜利,而是一整条密度曲线的“活体证据”。
刘知远教授早就预见了这个趋势。他曾断言:“只要能实现某种智能,未来一定可以在更小的终端上运行。”
千问3.5正在验证这句话。
当9B模型能跑出十倍参数量的性能,AI的部署门槛就从“有服务器集群的大公司”降到了“有一张消费级显卡的个人开发者”。当几百人的公司能做出与数千人巨头掰手腕的模型,创业公司入场的门槛就从“先融十亿美元”变成了“先找三百个聪明人”。
MiniMax就是后一种故事的注脚。全公司385人,平均年龄29岁,据闫俊杰在电话会上披露,公司成立至今累计花费仅5亿美元——对比OpenAI的数千员工和数百亿融资,交出的却是营收增长159%、毛利增长437%的答卷。智能密度不只是模型参数的物理概念,也是一种极其强悍的组织杠杆。
不要低估个人设备的汪洋大海。 信息革命初期曾有人预言“全球只需要几台大型计算机”。但到了今天,全球有超过70亿部手机。刘知远曾算过一笔账:早在2023年,全国散落在千万部设备上的端侧算力总和,就已经是数据中心的12倍。
智能的终局,注定是分布式的。
这才是“智能密度”比任何一次跑分都重要的原因。它指向的不是“谁的模型今天更强”,而是“AI最终以什么形态、多低的成本、来到每一个普通人身边”。
回到马斯克那句“Impressive intelligence density”。与其说他在夸赞一家中国公司的某次发布,不如说他在确认一个正在发生的转折:
AI的下半场,不属于最大的模型,属于最密集的智慧。