
新智元报道
MoE模型的稀疏激活原本是一项显著的优势,但往往面临通信瓶颈的问题。NVIDIA通过软件创新,在三个月内成功将GB200单GPU吞吐量提升了2.8倍,充分发挥了Blackwell硬件的实力。
2026年1月8日,NVIDIA再次以硬核数据刷新了AI推理的性能上限。
英伟达官网透露:基于Blackwell架构的推理软件栈升级,使混合专家模型(MoE)在效率上实现了突破性进展——
单GPU吞吐量显著提升2.8倍,大幅降低了推理成本。
GB200 NVL72专为MoE设计
英伟达之所以能够仅通过软件升级实现如此明显的性能改善,这得益于MoE模型的特殊性质。
例如DeepSeek-R1这一拥有6710亿参数的稀疏MoE模型,在每次推理过程中只激活370亿参数(即「稀疏激活」),看似轻便实则蕴含巨大计算挑战:专家模块之间的动态路由需要频繁的数据交换,预填充和解码阶段计算负载差异显著,传统架构很容易因通信瓶颈或精度损失陷入性能限制。同时MoE架构中多个模型的通信需求也很高。
英伟达提出了一种解决方案,在硬件基础上通过针对性软件升级来发挥其潜力。

图1:GB200 NVL72机柜
GB200 NVL72机架级平台是这一突破的物理基础。
它利用第五代NVLink互连技术将72块Blackwell GPU连接起来,每对GPU之间具有1800GB/s双向带宽高速通道——这种设计专为稀疏MoE架构模型优化,相当于给72个「专家大脑」装上了「超高速神经突触」,确保了专家之间的数据交换不再拥堵。
在软件层面的更新中,NVFP4四比特浮点格式是关键一环。
相较于传统FP4,NVFP4通过NVIDIA自主研发的数值分布优化,在压缩数据量的同时最大限度保留模型精度(这对于MoE稀疏激活至关重要,避免因精度损失导致路由错误)。
结合硬件级NVFP4加速单元,Blackwell使低精度计算成为可能,却仍能保持比其他FP4格式更高的准确性。
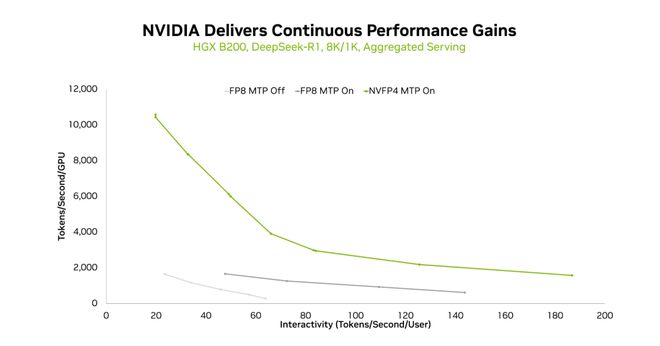
图2:在HGX B200上启用NVFP4与FP8时的吞吐量和交互性曲线对比
此外,「分解服务」策略进一步提升了GB200的能力:预填充(计算密集型)和解码(内存密集型)被分配到不同的GPU组中,并通过灵活拓扑结构实现「计算-内存」分离,避免单一资源成为瓶颈。
软件引擎
TensorRT-LLM在过去三个月内实现了单GPU吞吐量的显著提升
如果说硬件是基础,那么软件则是引擎调校。NVIDIA TensorRT-LLM开源库的优化让GB200 NVL72在DeepSeek-R1上的单GPU吞吐量直接提升了2.8倍。
具体来说,三项关键改进堪称「性能催化剂」:
一是程序化依赖启动(PDL)
减少内核启动延迟,确保GPU时刻待命,在低交互性场景下显著降低空转损耗;
2、底层内核优化
拆解Blackwell Tensor Core的微架构特性,重构计算流水线,使每一单位算力都能发挥最大效能。
三是全对全通信原语革新
直接减少接收端中间缓冲区的数据传输「绕路成本」——这对MoE中专家间的高频通信尤为关键,减少了延迟时间。
上述创新使得GB200在运行DeepSeek R1时相比先前版本软件获得了更高的吞吐量。
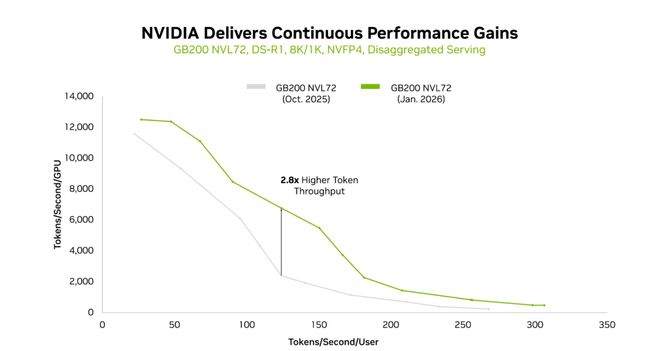
图3:更新的软件为GB200带来的性能提升
随着AI从「可用」走向「高效」,用户对交互性的需求日益增长——聊天机器人需要即时响应,代码助手需实时补全。而吞吐量的提高意味着更低的延迟。
小机柜也适用,
HGX B200同样适用于DeepSeek
并非所有场景都需要GB200 NVL72这样包含72块显卡的大规模系统。
对于采用风冷部署的企业或云服务商,NVIDIA HGX B200(8卡Blackwell)也展现了其卓越性能——核心在于多token预测(MTP)与NVFP4的结合使用。
传统推理中,模型逐个生成token;而MTP通过预测多个候选token让GPU在一次计算中覆盖更多生成步骤,相当于批量处理解码任务中的输出步骤,做到「一次思考,多步输出」的效果。
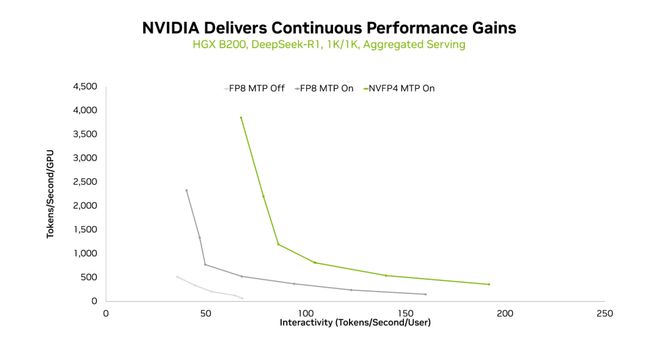
图4:不同配置下MTP与NVFP4带来的性能提升
实验结果显示,在1K/1K、8K/1K和1K/8K等不同的输入输出序列组合中,MTP均显著提升了吞吐量,并且交互性越高(延迟需求越严格),其收益越明显。
当MTP与NVFP4相结合时,性能增益进一步扩大。NVFP4通过四比特压缩减轻内存带宽压力,并利用Blackwell的张量核心实现高效计算。
结合TensorRT-LLM和TensorRT Model Optimizer的全栈支持,在保持精度的同时,HGX B200在启用MTP+NVFP4后吞吐曲线持续右移——意味着相同交互性下可服务更多用户或提供更流畅体验。
对于企业与云服务商而言,现有的Blackwell GPU通过软件升级即可获得2.8倍的性能提升,等同于「免费扩容」,大幅延长硬件使用寿命;对于模型开发者,TensorRT-LLM提供了先进的API支持。
原生PyTorch架构为开发者提供了一种既易于使用又具有扩展性的解决方案,这降低了优化门槛,让更多人能够专注于模型创新而非底层调优工作。
这种「不依赖硬件更换就能实现性能升级」的能力让英伟达在专业显卡领域的竞争优势更加稳固,超越了如AMD和英特尔等竞争对手。
结合Blackwell架构与TensorRT-LLM的解决方案,在混合专家模型推理问题上实现了高精度、低延迟、高吞吐量以及低成本的最佳平衡。这不仅是一套硬件生态系统,更是从底层软件到应用层全方位支持的强大体系。
参考资料:
https://developer.nvidia.com/blog/delivering-massive-performance-leaps-for-mixture-of-experts-inference-on-nvidia-blackwell/