
何庭波、梁文锋,给出了同一种答案
历史从不因某个定律被“提出”而改变,历史只因某个定律被“验证”而改变。头图及封面来源 | 网络及AI制作又一个极限微操。如同DeepSeek用算法榨干GPU一样,华为也打算在半导体领域做同样一件事。5月25日,由电气电子工程师学会(IEEE)举办的国际电路系统研讨会ISCAS 2026在上海举行。会上,华为公司董事、半导体业务部总裁何庭波在题为《半导体新路径探索与实践》的主旨演讲中,正式发表了“
科技1 阅读
共找到 63 篇相关文章
历史从不因某个定律被“提出”而改变,历史只因某个定律被“验证”而改变。头图及封面来源 | 网络及AI制作又一个极限微操。如同DeepSeek用算法榨干GPU一样,华为也打算在半导体领域做同样一件事。5月25日,由电气电子工程师学会(IEEE)举办的国际电路系统研讨会ISCAS 2026在上海举行。会上,华为公司董事、半导体业务部总裁何庭波在题为《半导体新路径探索与实践》的主旨演讲中,正式发表了“

5月27日,SK海力士股价在韩国早盘最高上涨11.1%,市值升至约1,624万亿韩元。按美元折算,约1.08万亿美元,正式跨过万亿美元门槛。SK海力士是英伟达高带宽内存的关键供应商。彭博称,过去一年公司股价累计涨幅超过900%。它不是做大模型的公司,也不是造GPU的公司,但它卡在AI数据中心最关键的环节之一:让GPU不断拿到足够快、足够近的数据。这并不是SK海力士一家公司的行情。5月早些时候,三

过去两年,AI算力的主角几乎只有一个:GPU。训练大模型需要GPU,推理大模型需要GPU,英伟达的股价、数据中心收入和供应链话语权,也都建立在这个判断上。但AMD CEO苏姿丰现在给出了另一个说法:AI智能体会把CPU市场重新拉起来。5月22日, Nikkei Asia报道称,苏姿丰再次预计,到2031年,CPU市场年增长率可能超过35%。这和过去3% 到4% 的历史增速相比,是一次非常激进的上

前沿模型公司的利润表,终于出现了正数。据《华尔街日报》报道,Anthropic正在迎来一个关键季度:公司预计2026年第二季度收入将超过109亿美元,较第一季度的48亿美元增长超过一倍,并首次实现季度营业利润。路透社随后跟进,称Anthropic二季度预计营业利润约5.59亿美元。过去几年,关于AI泡沫的质疑一直没有消失。大模型固然火热,但也确实是太烧钱了:训练模型要钱,推理服务要钱,GPU、数据

摩尔线程不想只做中国英伟达。文|Stargazer编|刘俊宏一家国产GPU公司的产品跨度能有多大?5月18日,摩尔线程的2026产品发布会现场,出现了一幅颇具反差的画面。舞台一侧展示的是夸娥万卡智算集群,另一侧是自研“长江”SoC驱动的智能终端MTT AICUBE和MTT AIBOOK。软件端,摩尔线程给的是从数字世界智能体“小麦”,到加速物理AI落地的首个全栈具身智能仿真平台MT Lambda,
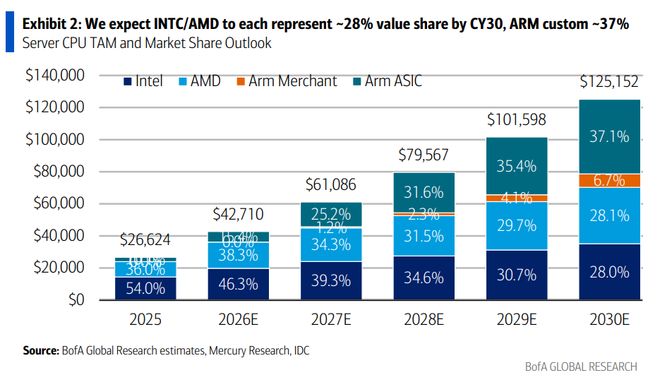
AI硬件的主线,正在从“GPU够不够”扩展到“系统哪里会堵”。训练时代,GPU和定制加速器吃掉了大部分增量预算;到了推理、Agentic AI和企业AI阶段,任务不再只是一次模型调用,而是规划、检索、工具调用、API交互、状态管理、数据库访问和多轮循环。CPU重新进入定价框架——但更关键的问题是:这轮增量,x86还是ARM在接?据硬AI,美银证券分析师Vivek Arya等在研报中的核心判断是:"


智东西作者 杨京丽编辑 云鹏智东西5月18日报道,今天,百度发布2026年第一季度财报并开展电话会议。一季度,百度总营收321亿元,除爱奇艺等业务外,一般性业务收入260亿元,同比增长2%,恢复正增长;核心AI业务收入达136亿元,同比增长49%,占百度一般性业务收入的52%,占比首次过半;AI云收入88亿元,同比增长79%,GPU云收入同比增长184%;AI应用收入25亿元;AI原生营销服务收入

机器之心编辑部如果只看这场 Meetup 的嘉宾名单,你大概会先想到海外芯片巨头,或者某家国际 AI 基础设施公司。毕竟,SGLang、TileLang、Triton 、Mooncake…… 这些今天大模型推理栈里最活跃、也最有存在感的开源项目,几乎都有核心开发者来到现场。但真正把这群人聚到一起的,竟然是摩尔线程。这才是这件事最值得看的地方。它说明一件事:国产 GPU 厂商开始不只是追着生态跑,而

金磊 发自 凹非寺量子位 | 公众号 QbitAI没有大厂高管站台,一屋子却挤满了开源圈的熟面孔。随便往台下扫一眼,就能对上好几个GitHub上的明星ID:有目前大模型推理框架顶流SGLang的核心开发者BBuf(Xiaoyu Zhang);有主导下一代算子编程生态TileLang的维护者唐正举有操刀KVCache解耦与传输神器Mooncake的核心贡献者马腾有来自智源人工智能研究院、围绕Trit

国产GPU组了个开源局,把SGLang等核心开发者都摇来了! 十三 2026-05-14 17:51:46 量子位 国产GPU开启

机器之心编辑部过去十年,AI 卡的是算力;未来十年,物理 AI 卡的是数据。而数据的前提,是仿真。没有可规模化的仿真世界,就没有可规模化的机器人数据;没有统一的仿真标准,就不会有真正的物理 AI 生态。仿真,正在成为物理 AI 时代的 CUDA。CUDA 曾经把 GPU 计算变成 AI 时代的统一底座。今天,仿真正成为物理 AI 时代新的标准层。物理 AI 的核心瓶颈已经变了回望过去的技术演进,每

智东西编译 刘煜编辑 陈骏达智东西5月11日消息,《财富》杂志今日放出了对高通总裁兼CEO克里斯蒂亚诺・阿蒙(Cristiano Amon)长达50分钟的专访。在本次采访中,Amon明确2026年为AI智能体元年,同时预判终端业态与6G技术变革趋势。在数据中心领域,他反对“唯GPU论”,预告高通将于六月底推出基于CPU与推理算力的高能效定制化方案。采访中提及智能手机与AI终端发展,Amon分享到,

5月8日,在北京召开的NAVIGATE 2026领航者峰会上,新华三集团发布了以UniPoD S80000超节点为核心的新一代AI基础设施全栈产品。为了应对当前大模型应用中的算力利用率低和集群扩容难题,该公司力求为政府及企业客户提供更优的Token性价比。紫光股份董事长兼首席执行官于英涛在峰会上指出,目前人工智能产业正在经历基于Token经济的变化。针对数据中心GPU使用率不足60%以及网络拥堵带

近日,马斯克将旗下价值高达300兆瓦的Colossus 1超算集群中的全部GPU资源悉数提供给Claude使用。 梦晨 2026-05-07 09:13:33 量子位

三个月前,马斯克还在骂Anthropic“邪恶”;三个月后,他把自家最强的超级计算机租给了它。5月6日,SpaceX和Anthropic官宣:Anthropic拿下Colossus 1超级计算机的全部使用权,包括22万颗英伟达GPU,共300兆瓦算力,本月交付。双方还放了个更大的风:正在谈数千兆瓦级的轨道AI数据中心合作。这笔交易最有意思的地方,是马斯克的变脸速度。今年2月,他还在X上炮轰Anth

在最近一期关于 2026 财年的第一财季(即从 2025 年 12 月 28 日到 2026 年 3 月 28 日)的财报电话会议上,AMD 的首席执行官苏姿丰指出,智能体人工智能技术正在改变服务器中央处理器市场的格局。苏姿丰强调,在本季度内,AI 已成为推动增长的关键因素。各大主要云服务提供商都在扩大霄龙(EPYC)芯片的应用范围,涵盖通用计算、数据处理以及新兴的智能体应用等领域。苏姿丰进一步解

在AI时代,如何充分利用GPU资源?据报道,《The Information》最近的一篇文章引发了人们对马斯克旗下的xAI公司关注,其使用的GPU资源利用率仅为约11%。目前,xAI在Memphis和Colossus数据中心集群中运营着大约55万块英伟达的H100和H200系列GPU,并且其中一部分设备采用了液冷技术。尽管这些GPU型号属于上一代产品(比最新的Blackwell系列早),但其规模仍
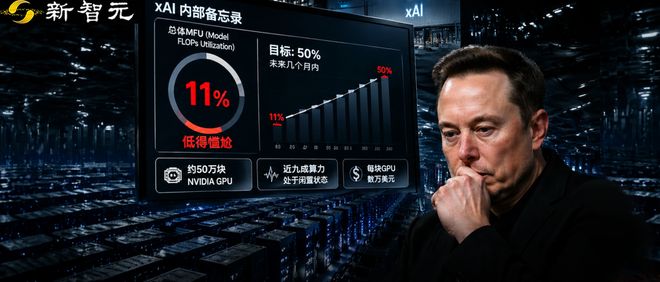
新智元报道据最近的报道,马斯克手上的数十万张GPU仅发挥了约11%的有效利用率。xAI总裁Michael Nicolls在内部备忘录中对此表示尴尬。尽管存在质疑的声音,但这一说法已经得到了证实和广泛讨论。《The Information》首次披露了这个消息,并且Business Insider随后确认了Nicolls的备忘录内容。Michael Nicolls在备忘录中直接指出,目前xAI所持有的

本文探讨了未来数字世界的核心商品——Token,并分析其在人工智能时代的重要性。黄仁勋于2026年的GTC大会上,定义了AI时代的底层通货,并将数据中心比喻为生产智能的工厂。在过去几年里,全球绝大多数此类“工厂”都依赖英伟达的GPU和CUDA生态进行运作。然而,这种情况引发了人们对算力供应链单点依赖的关注,尤其是在全球人工智能市场Token供给方面的问题。2026年4月24日,DeepSeek