最近,关于开源模型的争议再次引起广泛关注。
这次,事件的焦点集中在一家国产开源模型与硅谷初创公司之间。
值得注意的是,双方在这次事件中的立场似乎发生了转变。
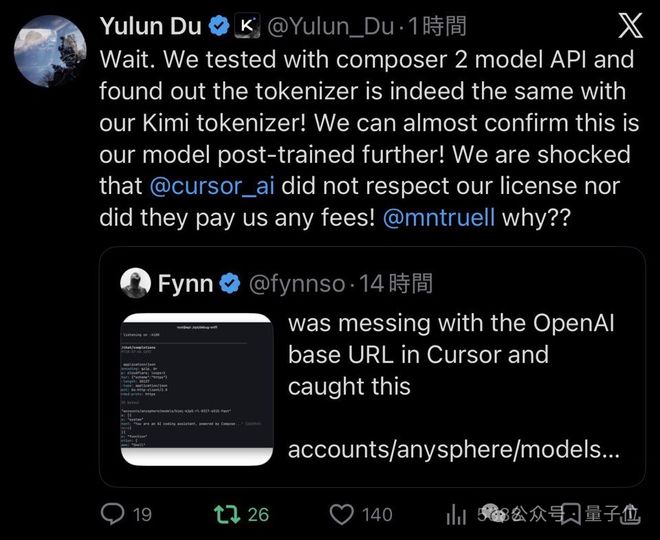
月之暗面的预训练模型负责人杜羽伦,直接点名Cursor的CEO Michael Truell,质问其为何没有遵守许可协议且未支付任何费用。
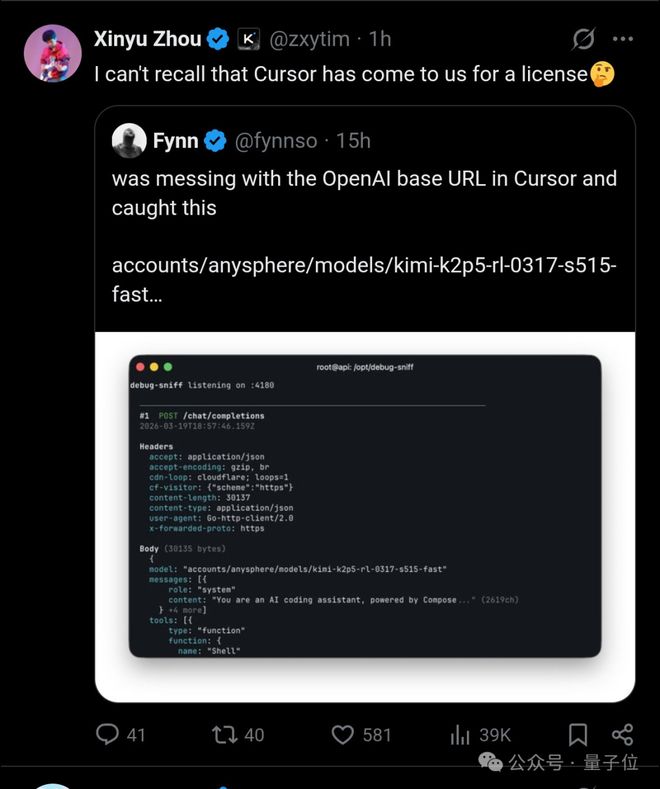
月之暗面的另一位联合创始人周昕宇也对Cursor进行了严厉批评。
周昕宇表示,他不记得Cursor曾经向他们申请过授权。
面对质疑,Cursor终于给出了正式回应,承认其所谓的「自研」模型实际上是基于Kimi模型开发的。
至于为何没有署名,Cursor方面表示这是一次疏忽,承诺未来不会再次发生。
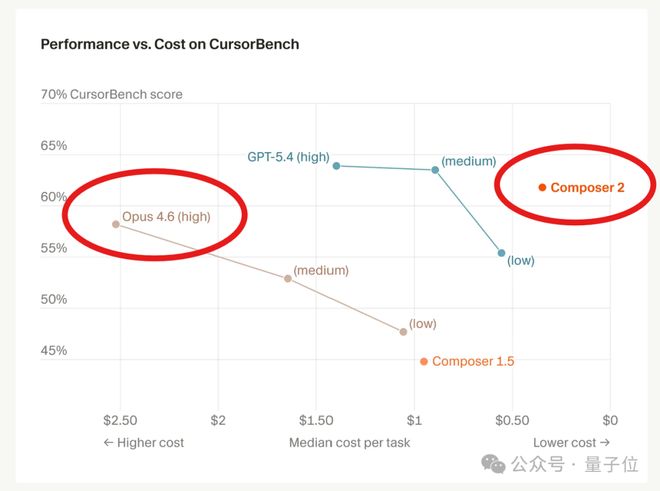
当时,Cursor宣称他们的模型名为「倒反天罡」,具有极低的成本和卓越的性能。
然而,很快就有网友指出,Cursor在基准测试中扮演了双重角色,既当裁判又当运动员。
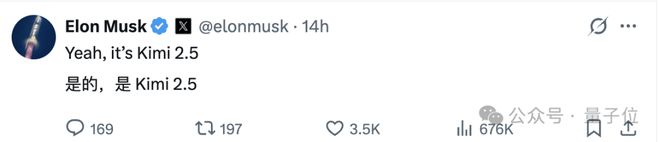
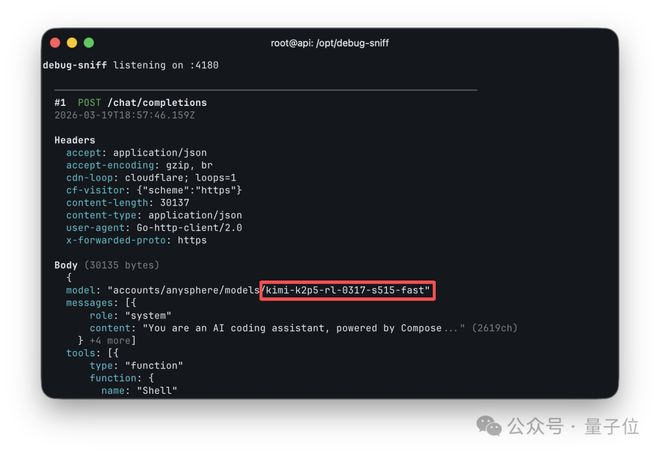
一个网友无意中在Cursor的日志中发现了模型名称为Kimi K2.5,这一发现让Cursor措手不及。
Cursor官方迅速关闭了这一渠道,试图平息事态。
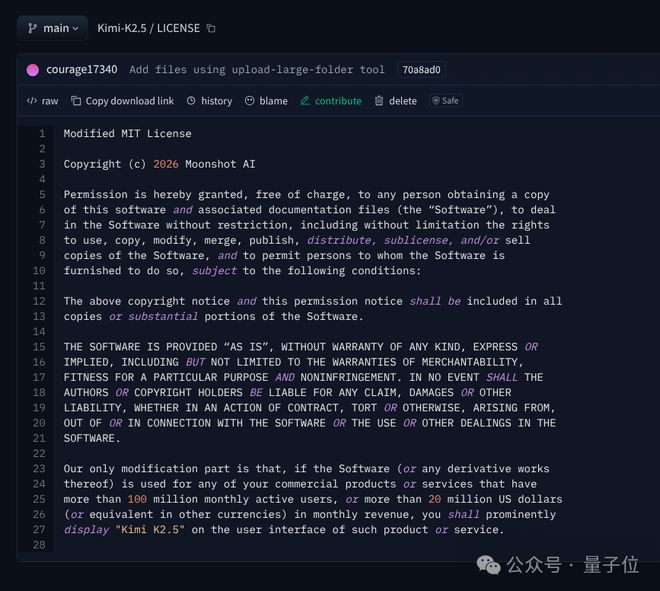
然而,Kimi模型的许可协议明确规定,如果使用该模型进行商业产品开发且规模较大,则必须明确标明Kimi K2.5。
Cursor的估值和月收入都远超这一标准,因此,其行为显然违反了相关规定。
月之暗面联创周昕宇对Cursor的回应表示质疑,并认为Cursor的行为令人难以置信。
杜羽伦通过技术手段进一步证实了Cursor模型与Kimi模型的关联性。
随后,杜羽伦直接向Michael Truell提出了疑问。
有人评论道,Cursor的行为就像是在假装自己很懂模型,但实际上却是在抄袭。
回顾Cursor当初发布的声明,其中提到的性能提升主要是通过持续预训练和强化学习实现的。
事实上,帮助Cursor实现这一突破的,正是Kimi模型。
事件发酵后,周昕宇和杜羽伦在社交媒体上的相关讨论已经消失。
目前,Kimi方面仅发布了一条官方声明,表示Cursor的Composer 2模型是基于Kimi k2.5开发的,并且双方之间存在授权的商业合作关系。
Cursor创始人Aman Sanger随后也承认了Kimi k2.5的强大性能。
全网炸锅。
关于为何在发布博客中未署名,Aman Sanger解释这是一次失误,并表示歉意。
但为时已晚。
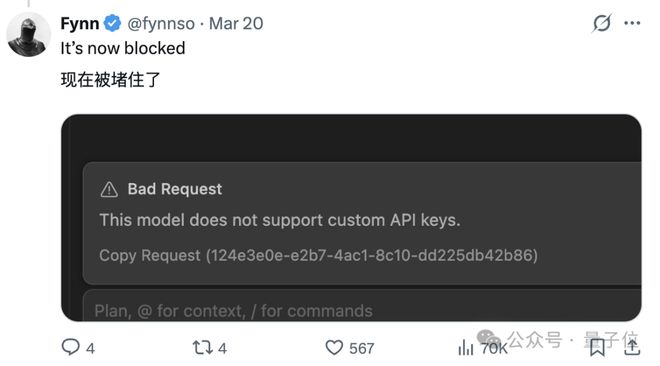
从Cursor发布新模型后的技术解读来看,很难相信这只是单纯的疏忽。
事实上,Composer模型的透明度问题一直存在争议,许多网友对其真实性表示过怀疑。
在这些质疑面前,Cursor从未正面回应。
而这次事件,从某种程度上也反映了国产模型的实力。
类似的情况在日本的Rakuten AI 3.0中也出现过,该模型也被发现与DeepSeek-V3模型非常相似。
在社区的强烈反对下,Rakuten才承认了其模型的来源。
尽管「拿来主义」行为不妥,但这也侧面证明了中国模型的影响力。
调侃归调侃,但也许……Cursor和月之暗面私下签了什么特殊定制协议呢?
毕竟体量这么大,这也是一次重磅级的发布,应该不至于白嫖吧???
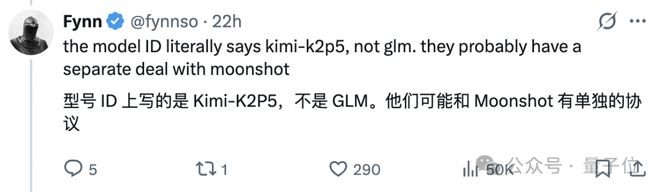
直到月之暗面联创周昕宇下场,一记重锤锤死Cursor。
- 我好像不记得Cursor有来找我们申请授权。
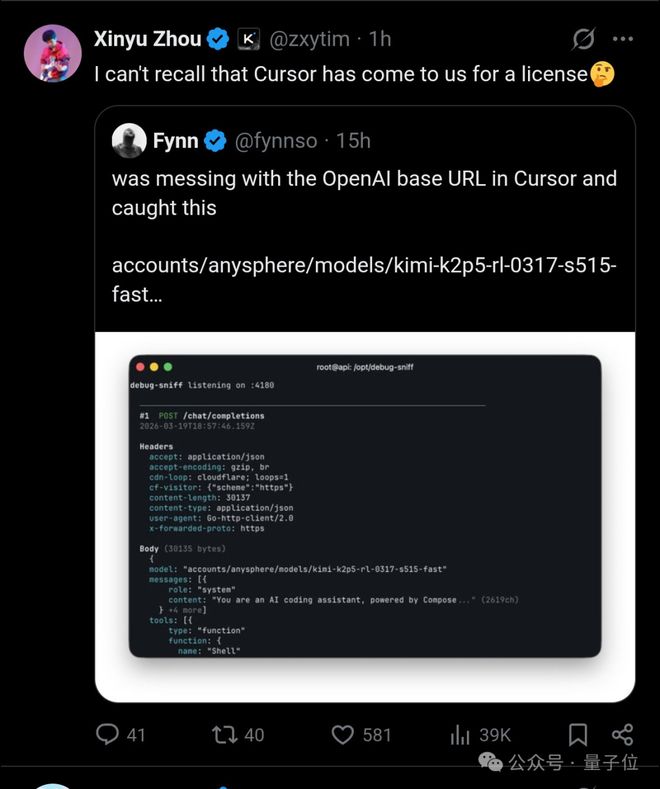
杜羽伦,得知消息后,当即去测了Composer 2的API,随即在技术层面给出更多证据。
结论:这模型的tokenizer,和Kimi一模一样。
几乎可以实锤,Cursor「暴打」Claude的最强自研模型,就是在Kimi基础上做了一道后训练。
仅此而已。
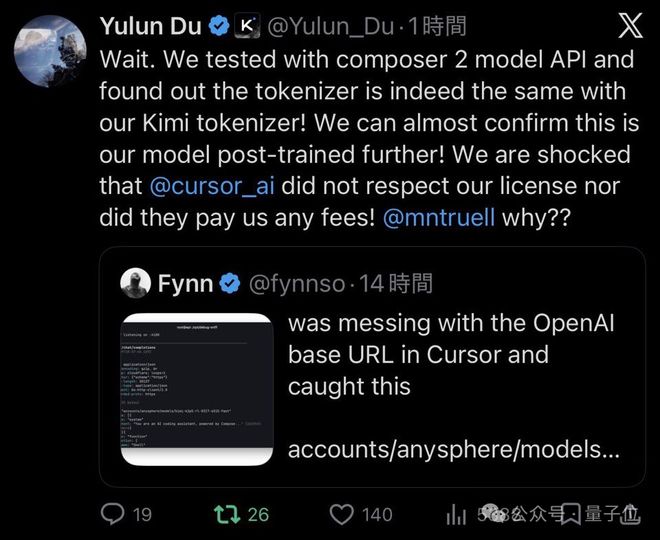
对此,杜羽伦表示「难以置信」。
- Cursor既没有遵守我们的许可协议,也没有向我们支付任何费用。
随即直接点名Cursor CEO:
- Michael Truell,为什么??
舆论彻底被引爆。
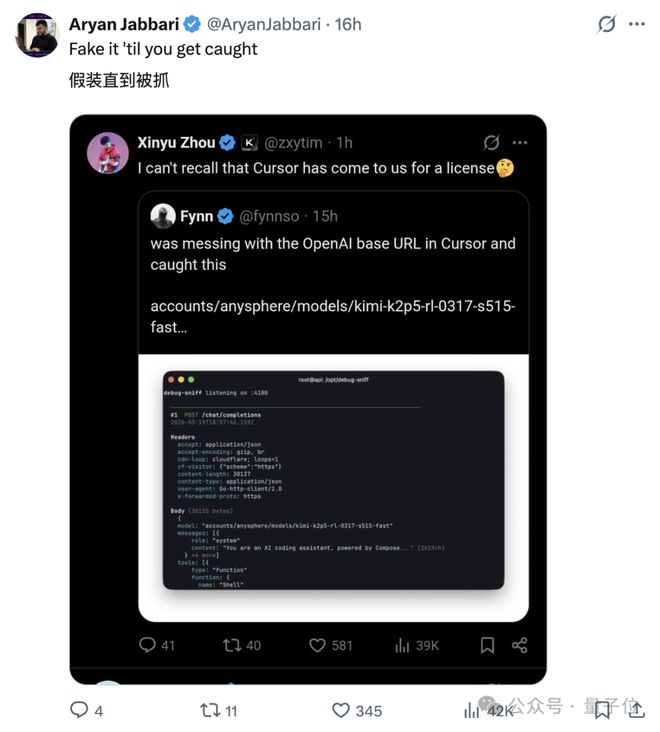
大概就是在嘲讽Cursor死不承认,结果现在被人家抓了现行。
印象最深刻是这条评论,攻击力极强:
「如果你是套壳AI应用,就好好当你的模型二道贩子,别装得自己很懂模型一样。」

如今再回头看Cursor当时更新「自研」模型表态,确实很感慨啊:
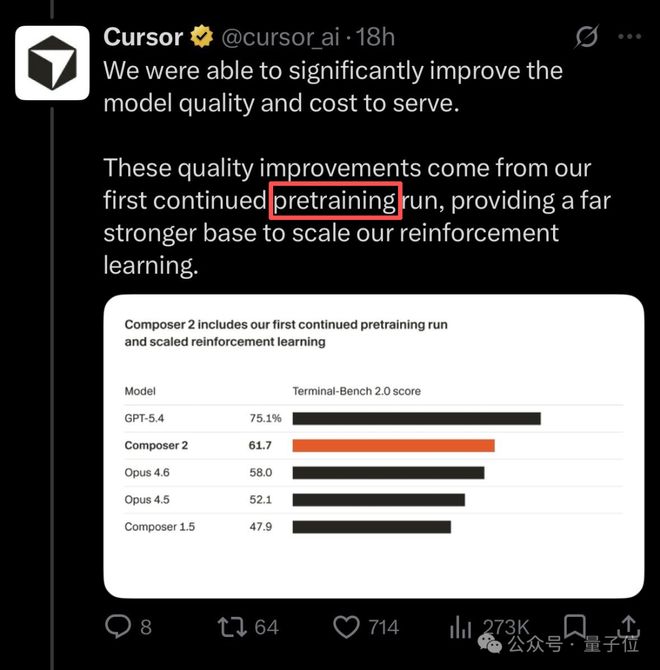
- 这些性能提升,来自我们首次进行的持续预训练,为后续扩展强化学习提供了坚实基础。
实在有些尴尬。
Cursor此次最大的卖点是强化学习,他们确实搞出了一种自我总结的RL方法,能解决上下文过长的问题。
但是,预训练???
哈??
谁曾想呢,帮助Cursor翻身把歌唱,把Claude压着打的,其实是Kimi。

反转来了?
以上是昨天夜间发生的故事,等今早一觉睡醒,想不到还有新瓜可吃。
X上,周昕宇和杜羽伦的相关推文、回复全没了。
Kimi的一条官方声明成了唯一的回应:
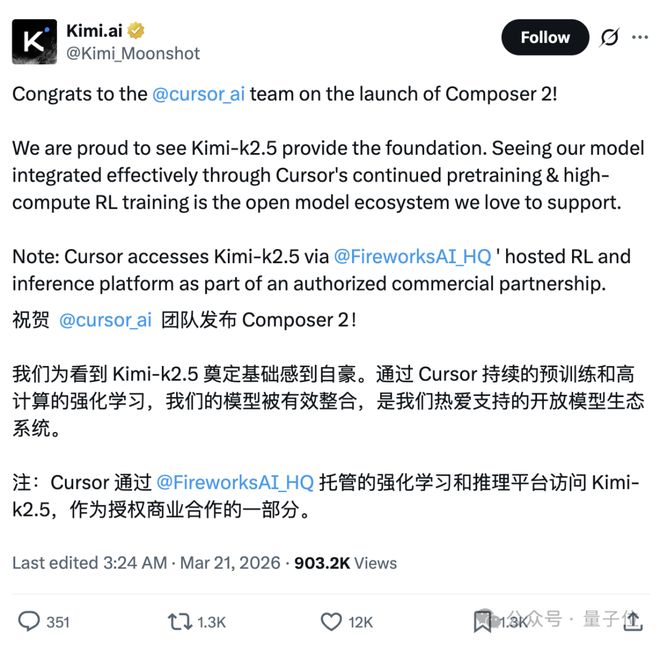
- 恭喜Cursor团队发布Composer 2!
我们很高兴看到Kimi-k2.5成为其基础模型。看到我们的模型通过 Cursor 的持续预训练和高算力强化学习训练被有效整合,这正是我们所支持的开放模型生态。
补充说明:Cursor是通过FireworksAI提供的托管强化学习与推理平台来访问Kimi-k2.5的,这是一个经过授权的商业合作关系。
不用过多翻译,读到这儿的你肯定已经和我会心一笑了吧doge。
优雅,实在太优雅了。
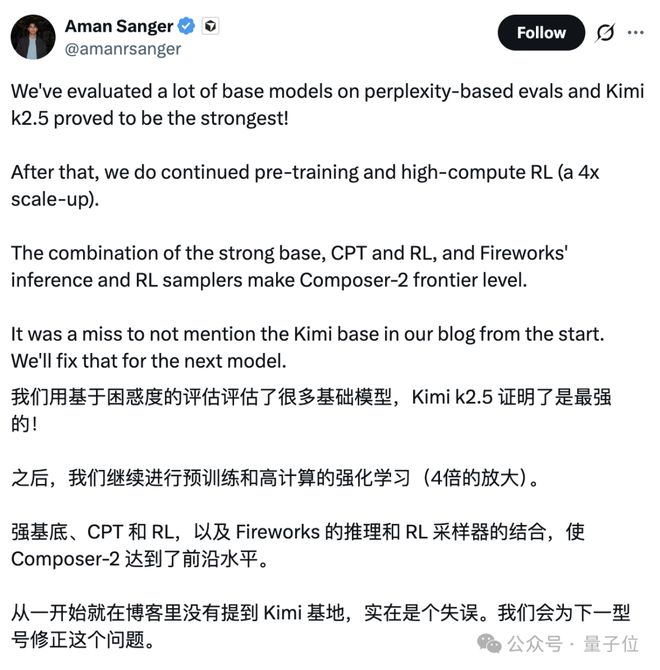
随后Cursor创始人Aman Sanger好像也终于想起了开源协议这件事,上来就对Kimi一顿猛夸:
- 我们做了很多评估,Kimi k2.5是最强的!

至于为什么发布博客里没署名?
Aman Sanger没有详细解释,只以滑跪结尾,说是一个失误,并表达了歉意。
网友们当然不会买账。
这这这,Cursor在发布新模型后一顿技术解读,又是预训练,又是RL的,换谁也不相信是单纯忘记署名了啊。
- 哦,忘记说了,其实模型用的是Kimi,但我们自己做了很多技术优化噢。

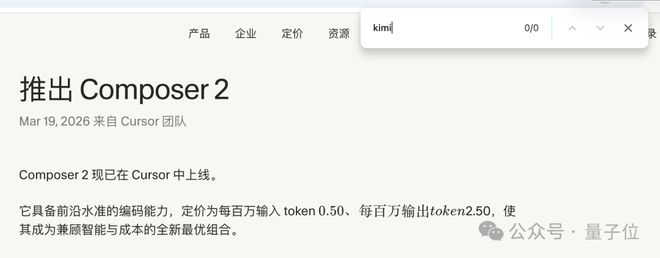
截至发帖,Cursor依然未在Composer 2的博客上补充任何Kimi相关说明。
One More Thing
其实,Cursor也不是头一次干类似的事儿了,只是之前没像这次被苦主用铁锤锤死。
Composer刚出来,就有网友对Cursor「自研」的真实性表示过怀疑。
主要博客实在写得太含糊了,只说用了RL、在MoE架构上做了优化,对模型底子完全只字不提。
- Composer的透明度缺失简直离谱。他们提到用了强化学习,但没交代模型的其他训练过程。
到底是自己预训练的,还是拿现成模型改的?
在他们公开更多细节、或有人能独立复现结果之前,我对这些说法都持保留态度。

后面确实也被网友扒出来蛛丝马迹,该模型的CoT里总是会莫名突然冒出中文;此外,模型表现和智谱GLM非常相似。
面对这些质疑,Cursor对此从没承认,也从来没否认。
不过,智谱的开源协议采用的是MIT,也就是说使用其模型的产品,即便商用,也不对署名做强制要求。
其实在业内,套壳这件事对小公司来说,也很正常。
从零训一个coding模型,成本太高了,风险也大,为了市场还必须持续抢SOTA,算力和时间成本都不划算。
在此背景下,好用又开源的国产模型,无疑成了资源受限条件下的最佳选择。
不止初创公司,就连日本闹得沸沸扬扬的「最强自研模型」Rakuten AI 3.0,也没能撑住。
发布不到12小时,就有,开源社区开发者直接在Hugging Face仓库的config.json文件里看到:
- “model_type”: “deepseek_v3”
参数规模、MoE结构……几乎和DeepSeek-V3一模一样啊。
更火上浇油的是:初始上传时,乐天疑似故意没上传DeepSeek原有许可文件和NOTICE,只留自家Apache 2.0。
被社区锤爆后才紧急补上一个NOTICE文件,承认来源。
怎么说呢,「拿来主义」确实很不好……
但也算是某种对中国模型实力的侧面印证吧。
[1]https://x.com/fynnso/status/2034706304875602030
[2]https://x.com/Kimi_Moonshot/status/2035074972943831491
[3]https://x.com/amanrsanger/status/2035079293257359663