谷歌Gemma 4详评:虽非完美,却是移动端的理想选择
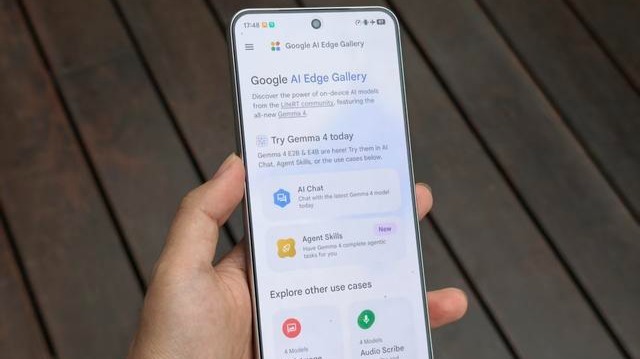
最近,谷歌推出了新一代开源模型Gemma 4,该版本包含了E2B、E4B、26B和31B四种规格的模型。其中,有两个较小规模的模型——E2B和E4B可以被直接部署在智能手机或树莓派等设备上,并支持离线运行。自从这两款「小型」端侧模型发布以来,它们受到了许多人的赞誉,被认为是迄今为止最实用的端侧解决方案。雷科技之前也发表了两篇关于实测体验的文章,一篇着重于逻辑推理和多模态功能的表现,另一篇则介绍了在
科技7 阅读
共找到 8 篇相关文章
最近,谷歌推出了新一代开源模型Gemma 4,该版本包含了E2B、E4B、26B和31B四种规格的模型。其中,有两个较小规模的模型——E2B和E4B可以被直接部署在智能手机或树莓派等设备上,并支持离线运行。自从这两款「小型」端侧模型发布以来,它们受到了许多人的赞誉,被认为是迄今为止最实用的端侧解决方案。雷科技之前也发表了两篇关于实测体验的文章,一篇着重于逻辑推理和多模态功能的表现,另一篇则介绍了在

新智元报道【新智元导读】Opus 4.7发布48小时,口碑两极撕裂。官方榜单并列全球第一,逻辑推理公开测试却从94.7%暴跌到41.0%。token消耗涨了35%,旧接口直接报错,用户集体控诉「更贵、更蠢、更爱顶嘴」。Anthropic到底升级了什么,又搞砸了什么?「4.6根本没法用,4.7的消耗速度像核反应堆一样。」Opus 4.7发布后,一位Reddit用户在Anthropic官方帖子下的留言

ReCALL团队在量子位平台上发布了一篇文章,探讨了生成式模型的应用效果。当多模态大模型具备强大的视觉和逻辑推理能力时,人们期待它们能轻松解决图像检索任务,尤其是组合图像检索问题。然而实际应用中却发现,将这些大型生成式模型改造为判别式的检索工具后,其性能反而显著下降。这种从生成转向判断的转换过程中产生了严重的功能退化现象。最近,紫东太初团队与新加坡国立大学的研究人员合作解决了这一行业难题,并提出了

IT之家 3 月 31 日消息,小米创办人、董事长兼 CEO 雷军今日分享了 MiMo-V2-Pro 大模型最新“战绩”。在大模型权威评测榜单 Text Arena,MiMo-V2-Pro 凭借在复杂逻辑推理、长指令遵循及多轮对话中的稳定表现,在 Model Rank 维度成功突破全球前五。同时,在衡量实验室综合研发实力的 LabRank(实验室排名)维度,Text Arena(ArenaExpe

凤凰网科技讯 3月31日,凤凰卫视在香港举办三十周年台庆的庆典,活动发布了多项重要合作。凤凰卫视执行副总裁兼运营总裁李奇与国内AI训练数据领域龙头企业——海天瑞声创始人、董事长贺琳出席仪式并交换文件,双方将携手深入挖掘海量音视频、文本及多语种、多模态内容,建设具备高知识密度和多元文化视角的高质量数据,为训练大模型逻辑推理、跨文化认知能力提供“黄金语料”。凤凰卫视三十周年台庆签约现场据凤凰卫视执行副

养虾热潮席卷全民,就连马化腾也对此表示惊讶:“没想到会有这么火”。然而随着深入体验,“神作”级别的OpenClaw却出现了一些令人头疼的问题,比如硬件要求高、Token消耗大以及“赛博健忘症”。在AI开发领域,处理长对话一直是个棘手问题。你是否遇到过这样的情况:编写代码时,突然发现AI失去了几分钟前的关键信息?或者为了节约Token,系统直接删除了之前的对话记录,导致无法继续逻辑推理?正当许多“养

你是否也在对这个问题感到疑惑? AI大模型之间的实际差距,真的就像各种榜单上显示的那样明显吗? 确实,这些排名看起来一目了然。 参数和得分都很清晰,但总觉得用特定题目和维度来评估AI的能力,似乎有些限制其潜力。 如果将它们置于复杂互动环境中,这些模型的逻辑推理能力是否还能像在标准测试中那样拉开差距呢? 我相信不止我一个人有这种疑问。 目前已经有新的方法开始应用了,并且引起了极大的关注: 将全
