最近,谷歌推出了新一代开源模型Gemma 4,该版本包含了E2B、E4B、26B和31B四种规格的模型。其中,有两个较小规模的模型——E2B和E4B可以被直接部署在智能手机或树莓派等设备上,并支持离线运行。
自从这两款「小型」端侧模型发布以来,它们受到了许多人的赞誉,被认为是迄今为止最实用的端侧解决方案。雷科技之前也发表了两篇关于实测体验的文章,一篇着重于逻辑推理和多模态功能的表现,另一篇则介绍了在国产千元机上的具体应用情况。
经过一段时间的实际使用后,雷科技团队对这款新模型有了更深入的理解与体会。
图源:雷科技摄制
端侧模型的应用效果比传统百科全书更为出色百倍
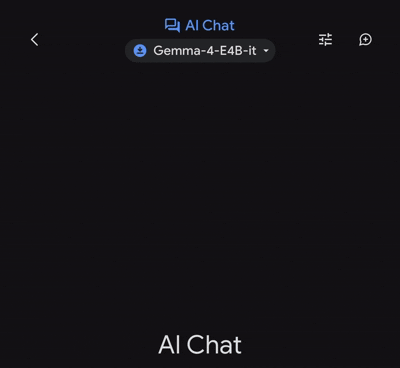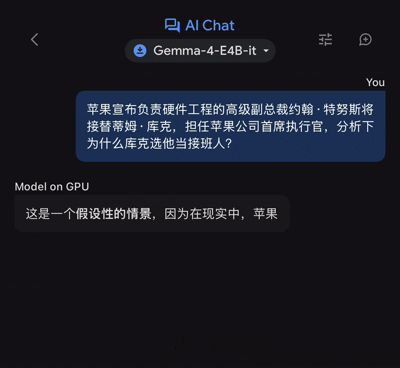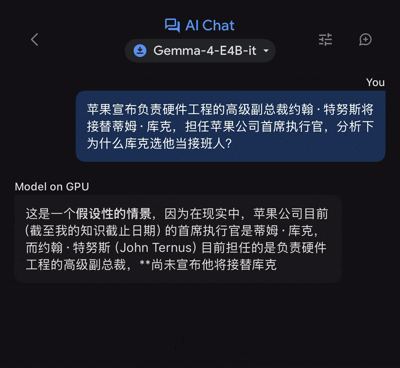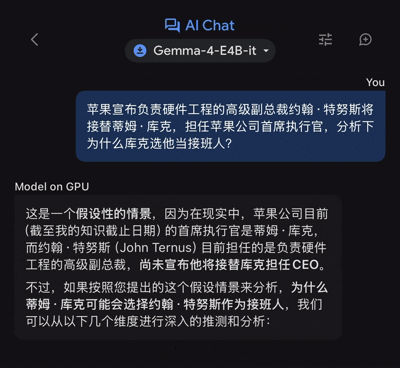
近日,苹果公司宣布由硬件工程高级副总裁约翰·特努斯接替蒂姆·库克担任首席执行官。对于为何选择他作为继任者的问题,我们决定利用谷歌的端侧模型Gemma 4 E4B来尝试解析这一问题。
在输入相关查询信息后,我们可以看到,这款端侧模型在处理过程中几乎不存在延迟现象,立刻开始进行信息输出。(说明:测试设备为iPhone 17 Pro Max)
图源:雷科技
然而,在提供完整答案时却花费了大约46秒的时间。虽然耗时较长,但它仍能较好地解答人们的疑问。

图源:雷科技
这正是端侧模型的核心优势所在:
在硬件成本最低的情况下(即本地运行且不消耗Token),能够给出较为满意的结果或解决方案。
最近,一部热门国产剧《太平年》引发了广泛的讨论。为了测试谷歌端侧模型的功能,雷科技向它提问了一个关于该剧的问题:“在重税政策下,吴越国为何能维持长达八十余年的安定繁荣?”
这是一个相对专业且具体的历史问题,许多非历史专业的大学毕业生可能也难以给出准确答案。让我们来看看Gemma 4 E4B的表现如何。
可以看到,端侧模型不仅仅是离线的百科全书,还可以根据用户的具体需求进行有针对性的回答,涵盖了各类专业知识领域的问题咨询。

图源:雷科技
此外,谷歌表示该版本的知识更新截止时间为2023年10月。在此之前的所有被记录和公开的信息、科学发现、历史事件及文化知识等均可以在模型中查询。(说明:测试设备为iPhone 17 Pro Max)
雷科技认为,对于对古今中外各类信息感兴趣的用户来说,这无疑是端侧模型目前最为实用的应用场景之一。
在体验过这款应用(即Google AI Edge Gallery)后,雷科技编辑将其常置手机主屏上,因为几乎每天都需要用到它。
谷歌还表示,尽管Gemma 4的核心数据集有一个知识截止时间点,但系统会持续更新和微调以提升模型的理解能力和回答质量。
处理简单问题时出现错误频发
我们原本认为,在基础知识领域,端侧AI模型已经能够完全胜任,然而实际情况却让人失望。
例如,Gemma 4 E4B在提供唐诗名篇《将进酒》的全文和作者信息时出现了明显的错误。
原因在于端侧模型整体参数量较小,至今仍无法覆盖所有知识领域。因此,在某些细节上会出现“失真”或“幻觉”的情况。

图源:雷科技
对于古诗文、古籍等资料信息的查询,建议将原文直接发送给模型以获得更准确的结果。
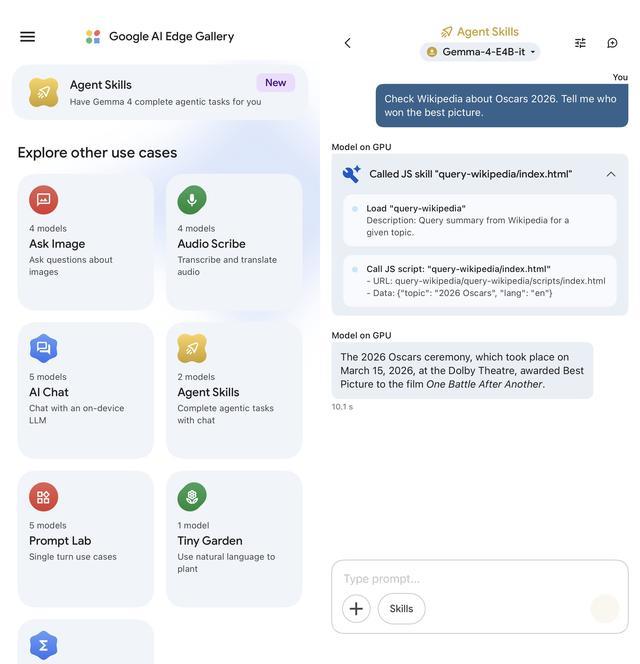
针对端侧模型参数量小的问题,谷歌首次尝试在其上引入了「智能体」的功能模块。
但是目前的信息检索功能只能通过联网访问在线百科网站(如维基百科),没有提供可以下载的离线知识库资源作为补充。
在工作协助和实际操作场景方面,端侧AI模型也有所尝试。然而,在进行文章语病检查这类任务时,其表现并不尽如人意。
图源:雷科技
这主要是因为此类高精度任务需要大量的编辑语料以及强大的语言分布记忆能力。
当给出“进行基本语法错误检测和修正”的指令后,端侧模型可能无法完全理解意图。然而,如果换成“仅检测并标注出文中的错误”这样的命令,则会得到更为明确的回答。
谷歌Gemma 4具备system role、function calling等控制功能,但前提是用户需要提供简洁清晰的提示模板和任务描述。
实测发现,在处理长篇文章语病检查这类复杂精细度的任务上,英文相比中文支持得更好。这可能与预训练数据集以英语为主有关。

图源:雷科技
目前看来,端侧模型更适合特定场景的应用?
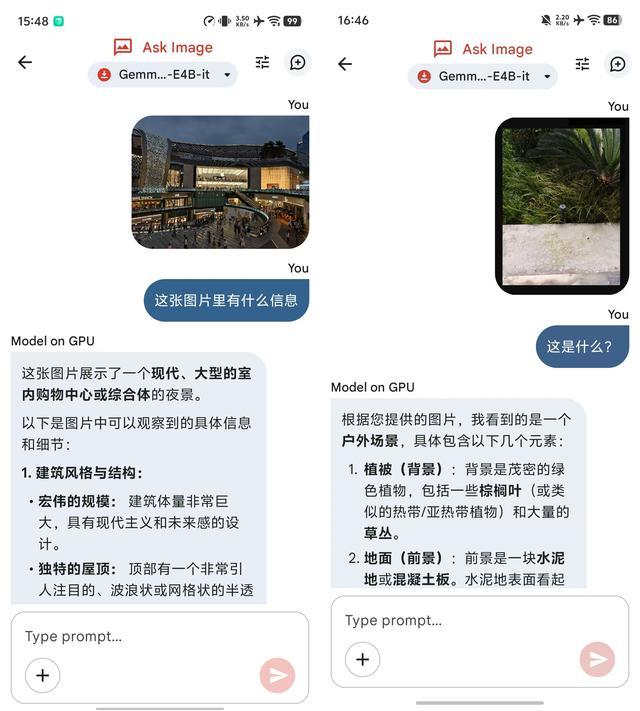
除了上述提到的功能外,雷科技还体验了Gemma 4 E4B的原生多模态(图像、音视频)能力。它可以识别图片内容,并理解简单的音频和视频信息。
在离线或网络不佳的情况下,用户可以将相册中的照片发送给端侧模型以获取基本信息。
然而,在面对复杂的图像和音频信息时,目前的端侧模型仍然难以解析更多的细节信息。
那么,当前端侧模型最擅长的功能是什么呢?
无疑是这些:离线翻译、计算器、简单问题解答及训练测试等工具应用,以及在专业领域(如健康)的基础信息咨询和科普。
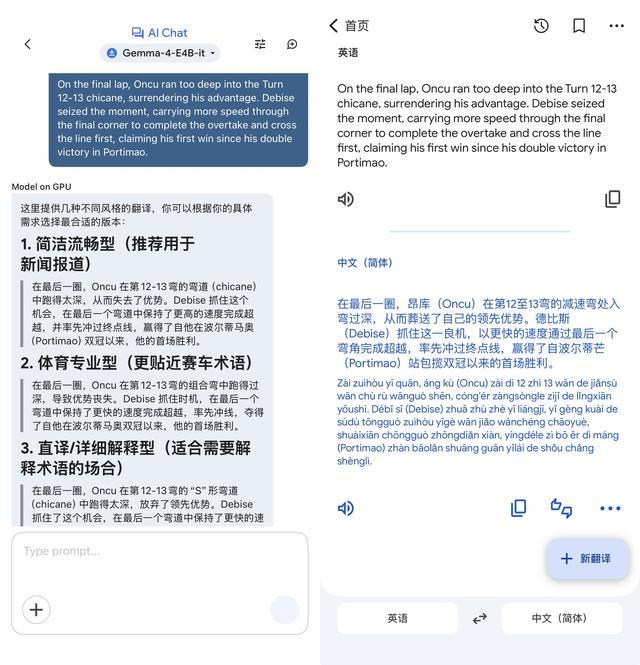
值得一提的是,谷歌此前基于Gemma 3开发了专门的翻译模型TranslateGemma。通过专项训练流程,其性能已经可以与规模较大的基准模型相媲美。
图源:雷科技
腾讯混元最近也开源了一款手机端离线翻译模型Hy-MT1.5-1.8B-1.25bit,支持大量外语的即时转换。
目前来看,谷歌Gemma 4的推出标志着向移动设备部署端侧模型迈出了关键一步。
当下阶段适合使用该技术的人群主要分为两类:
第一类是频繁查询古今中外信息的“百科类”用户;第二类则是手机中安装了大量离线应用的“工具型”用户。
对于那些想要体验新功能或见证其发展过程的人来说,下载并试用也是一个不错的选择。
iPhone用户需要注意的是,在未来苹果公司推出自家端侧模型时,其性能大概率会与谷歌Gemma相仿。因此,在此基础上进行改进的空间可能不大。
关于回答速度的问题,它与手机内存和算力密切相关。对于iPhone而言,推荐至少8GB运存起步;安卓设备则建议12GB起。
用户可以在App Store或各大应用商店下载Google AI Edge Gallery App,并通过该软件直接将谷歌相关端侧模型部署至本地进行体验。
从技术层面来看,这标志着谷歌向中国内地市场开放了一个全新的大模型产品线。
展望未来,随着旗舰手机内存步入16GB阶段,“小模型”将在更多、更强的技能表现上实现突破,并具备更大的本地知识库容量。
这将使得端侧模型为用户带来全方位升级后的使用体验。这一天已经越来越近了。
当然,你想尝鲜,或者说见证端侧模型的一路成长,也可以下载体验。
对于iPhone用户,苹果即便在未来推出自家的端侧模型产品,大概率也就是谷歌Gemma端侧模型后续可以实现的程度。可以期待的「增量」或「加强」技能,主要也就端侧模型对于手机各项操作指令的「完美联动」和「无缝接入」。
图源:谷歌
需要指出的是,谷歌Gemma 4端侧模型的回答和响应速度,与你手机的运行内存和算力水平有着莫大关系。
iPhone用户,建议运存8GB起步,推荐12GB;安卓用户,建议运存12GB起步,推荐16GB。这样的配置,可以体验目前端侧模型的最佳运行表现。
至于如何在手机上下载谷歌Gemma 4端侧模型,步骤极其简单,所有国内用户均可体验:
先在国区App Store或安卓应用商店下载配套的App,即Google AI Edge Gallery;其后可在App中对谷歌相关端侧模型直接进行本地部署(下载)和使用体验。
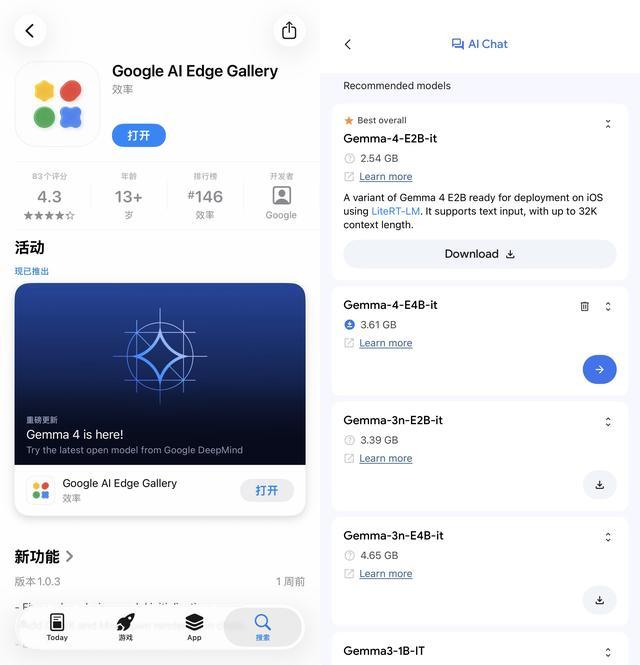
图源:雷科技
端侧模型,成了谷歌面向中国内地用户完全开放下载、并可直接使用的大模型产品。
而这似乎也预示着谷歌端侧模型(注:经过审查和备案后),未来有可能全面部署乃至预装到更多国产终端硬件设备,包括小型物联网终端设备等。
在这方面,谷歌已经在发力。Gemma 4模型支持业界通行的Apache 2.0许可,这意味着开发者可以更加自由地使用、修改和分发该模型,消除了以往商业化应用中的各项顾虑。
而通过与谷歌Pixel硬件团队以及高通、联发科等移动终端芯片平台企业合作,谷歌试图让Gemma 4端侧模型可以在更多安卓移动设备(尤其非高运存设备)上实现真正的「近乎零延迟」使用体验。
图源:雷科技摄制
可以想象,伴随未来旗舰手机(包括iPhone)运行内存全面迈入16GB阶段,「小模型」更多、更强、更高效的技能表现(尤其是与智能体的更成熟联动),以及更大的本地知识库信息储备量,端侧模型也将给用户带来全方位的加强版体验。
这一天,已经为时不远了。