
对话清程极智核心团队:不是所有Token都是好Token
智东西智东西5月26日报道,今天,北京AI Infra创企清程极智举办了一场小范围媒体沟通会,系统性地梳理了其成立以来的技术脉络与产品版图。清程极智成立于2023年底,核心团队来自清华大学计算机系高性能所,在高性能计算等领域有丰富经验。截至2026年3月,清程已完成3轮融资,投资方包括北京市人工智能产业基金、联想、中科创星等知名产业基金。目前,清程极智已经推出了智能计算软件栈八卦炉(Bagualu
科技1 阅读
共找到 5 篇相关文章
智东西智东西5月26日报道,今天,北京AI Infra创企清程极智举办了一场小范围媒体沟通会,系统性地梳理了其成立以来的技术脉络与产品版图。清程极智成立于2023年底,核心团队来自清华大学计算机系高性能所,在高性能计算等领域有丰富经验。截至2026年3月,清程已完成3轮融资,投资方包括北京市人工智能产业基金、联想、中科创星等知名产业基金。目前,清程极智已经推出了智能计算软件栈八卦炉(Bagualu

近日,摩尔线程的旗舰级AI训推一体智算卡MTT S5000,借助自主研发的MUSA软件栈和SGLang开源推理框架,在DeepSeek-V4模型上完成了完整的运行验证。目前,公司已建立起一套涵盖硬件架构核心计算引擎、热点算子支持以及端到端部署验证的系统化适配链路,展示了国产GPU在前沿大模型“框架级兼容、开箱即落地”方面的能力。随着大模型架构的发展,DeepSeek-V4等高级别模型对底层精度能力

新智元报道MoE模型的稀疏激活原本是一项显著的优势,但往往面临通信瓶颈的问题。NVIDIA通过软件创新,在三个月内成功将GB200单GPU吞吐量提升了2.8倍,充分发挥了Blackwell硬件的实力。2026年1月8日,NVIDIA再次以硬核数据刷新了AI推理的性能上限。英伟达官网透露:基于Blackwell架构的推理软件栈升级,使混合专家模型(MoE)在效率上实现了突破性进展——单GPU吞吐量显

新智元报道中兴通讯通过其超节点技术,成功绕开了传统GPU芯片性能的瓶颈,提供了一种系统级的最优解。从系统级协同架构出发,中兴超节点通过六大维度的全方位创新,即硬件架构、高速互联、功耗管理、集群扩展、软件栈及多厂家GPU兼容,全面提升了AI算力的性能和效率。中兴超节点技术的核心优势在于其系统级整合能力,通过硬件和软件的深度协同优化,实现对物理算力的有效调度和利用。这不仅提高了系统的整体效率,还为用户
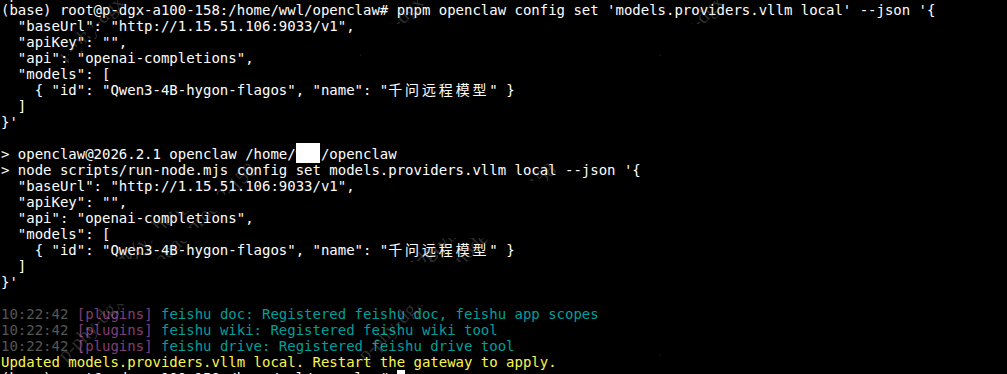
过去人们常常依赖公有云服务来获取AI能力,但随着OpenClaw等智能体工具的广泛使用,无论是个人开发者还是企业都更加倾向于拥有一个能在本地7×24小时运行、能够即时响应指令的“数字员工”。然而,云端方案存在的数据隐私风险和持续高昂的成本问题导致工业级智能体在大规模应用时遇到瓶颈,独立部署大模型服务已经成为构建自主可控AI能力的关键选择。 众智FlagOS是一款完全开源的AI系统软件栈,支持多种异