过去人们常常依赖公有云服务来获取AI能力,但随着OpenClaw等智能体工具的广泛使用,无论是个人开发者还是企业都更加倾向于拥有一个能在本地7×24小时运行、能够即时响应指令的“数字员工”。然而,云端方案存在的数据隐私风险和持续高昂的成本问题导致工业级智能体在大规模应用时遇到瓶颈,独立部署大模型服务已经成为构建自主可控AI能力的关键选择。
众智FlagOS是一款完全开源的AI系统软件栈,支持多种异构AI芯片,使AI模型与智能体能够轻松实现快速部署。此次FlagOS联合腾讯云HAI(面向AI和科学计算的容器镜像中心),将Qwen3-4B-hygon-flagos模型镜像正式上线至腾讯云HAI社区,开发者可以随时拉取使用。基于该镜像,可以在加速卡上迅速运行FlagOS + OpenClaw,实现小模型驱动智能体执行,为从公有云API转向自建本地AI服务提供了可操作的解决方案。
安装及测试过程
依托于FlagOS系统软件栈的跨芯能力,众智FlagOS社区将Qwen3-4B适配至多款GPU硬件。以下内容重点介绍部署与配置FlagOS版Qwen3-4B的过程,仅用于复现实验结果,并不影响对Agent功能的评估。
- 安装Qwen3-4B-hygon-flagos
- 首先,在HAI社区平台上找到Qwen3-4B-hygon-FlagOS并按照README.md文件中的说明拉取模型并启动服务。
以ModelScope为例,下载模型权重数据
| Plain Text pip install modelscope modelscope download –model Qwen/Qwen3-4B –local_dir /share/Qwen3-4B |
- 点击【部署当前镜像】获取镜像拉取命令,并从HAI社区中提取相应镜像。
| Plain Text docker pull haihub.cn/baai/flagrelease_hygon_qwen3:v1.0.0 |
- 使用以下代码来启动容器:
这段代码可以直接使用,也可以根据需要修改容器名称,在第四行更改–name=flagos中的name值即可。
| SQL #Container Startup docker run -it \ –name=flagos \ –network=host \ –privileged \ –ipc=host \ –shm-size=16G \ –memory=”512g” \ –ulimit stack=-1:-1 \ –ulimit memlock=-1:-1 \ –cap-add=SYS_PTRACE \ –security-opt seccomp=unconfined \ –device=/dev/kfd \ –device=/dev/dri \ –group-add video \ -u root \ -v /opt/hyhal:/opt/hyhal \ -v /share:/share \ haihub.cn/baai/flagrelease_hygon_qwen3:v1.0.0 \ /bin/bash |
- 登录到容器(如果之前改过容器名,请在此处调整为相应的名称)。
| Plain Text docker exec -it flagos bash |
- 启动服务
| Plain Text flagscale serve qwen3 |
- 安装和配置OpenClaw
安装流程参考:https://github.com/openclaw/openclaw?spm=5176.28103460.0.0.696675514ZMILC,通过源码安装OpenClaw。
| Python git clone https://github.com/openclaw/openclaw.git cd openclaw pnpm install pnpm ui:build # auto-installs UI deps on first run pnpm build pnpm openclaw onboard –install-daemon # Dev loop (auto-reload on TS changes) pnpm gateway:watch |
配置过程:
- 访问以下链接以获取“模型配置”文件格式:https://cloud.tencent.com/developer/article/2625144。根据文档中的说明进行相应调整后,您可以按照如下命令执行操作。
在本地模型配置过程中,请确保使用加速推理工具如vllm作为厂商。
| SQL pnpm openclaw config set ‘models.providers.vllm_local’ –json ‘{ “baseUrl”: “http://1.15.51.106:9033/v1”, “apiKey”: “anykey”, #key不可为空,如果原来模型没有配置key,任意填写即可 “api”: “openai-completions”, “models”: [ { “id”: “Qwen3-4B-hygon-flagos”, “name”: “远程模型” } ] }’ |
执行完毕后,您会看到以下信息提示:
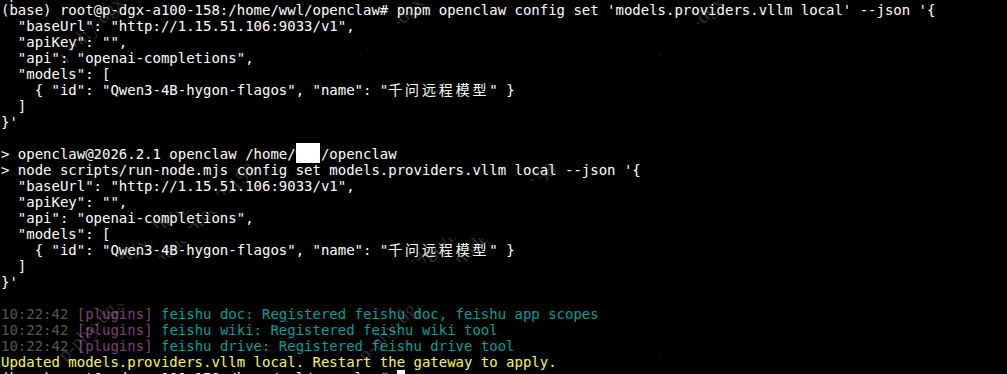
启用并设置为默认模型
| Plain Text 合并配置模型 pnpm openclaw config set models.mode merge |
| Plain Text 切换为当前模式 pnpm openclaw models set vllm_local/Qwen3-4B-hygon-flagos |
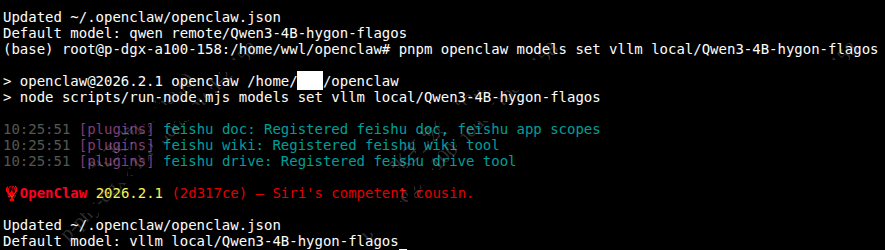
显示当前默认的模型已切换为Qwen3-4B-hygon-flagos。
- 通过执行下面代码可以确认模型已经切换完成。
| Plain Text pnpm openclaw configure |
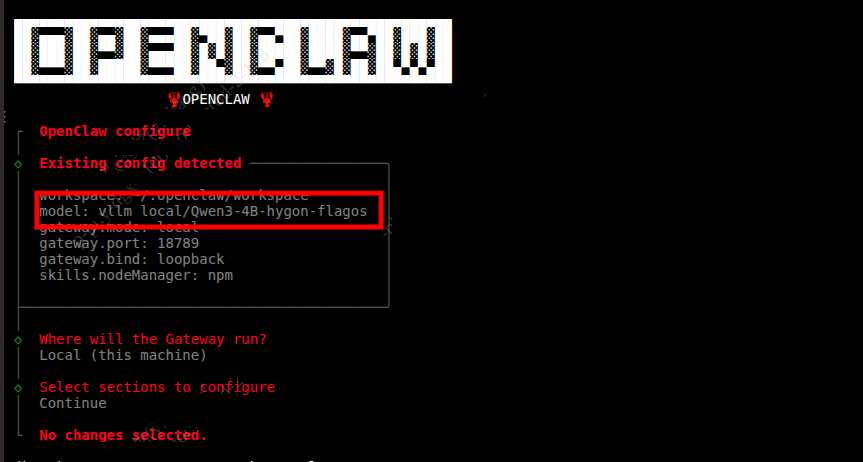
模型切换成功。
- 设置channel为QQ
参考文档:https://cloud.tencent.com/developer/article/2626045,这部分需要替换为自己的ID和密钥。配置完成后,请执行以下步骤:
- 启动OpenClaw网关,命令如下所示:
| Plain Text pnpm openclaw gateway |
- 网关启动成功后,您可以在QQ软件中尝试与已经接入OpenClaw的QQ机器人进行单独聊天或群聊对话。如果QQ机器人能够以AI的方式回答问题,则表明已成功完成OpenClaw应用接入。
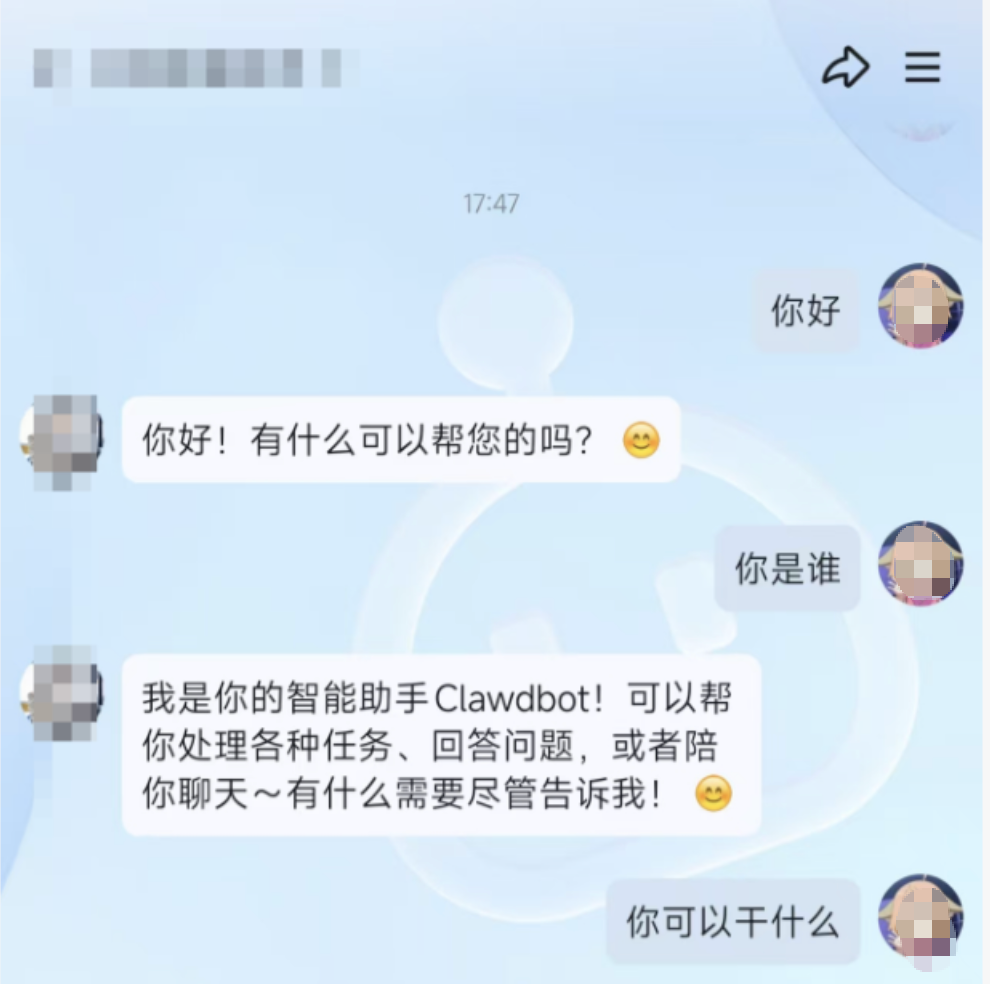
接下来,您可以探索更多关于在QQ环境中使用OpenClaw连接机器人的应用场景。
趋势展望
在这次测试中,Qwen3-4B-hygon-flagos与OpenClaw的结合显示了智能体能力边界的扩展趋势。
关键信号:
如果您需要一个能够本地运行并能调用工具以及连接企业系统的Agent内核, 少即是多,FlagOS是关键! |
| 关于众智 FlagOS 社区
众智FlagOS是一款专为异构AI芯片设计的开源、统一系统软件栈,支持一次开发即可无缝移植至各类硬件平台。它包括大型算子库、统一编译器、并行训推框架和统一通信库等核心项目,致力于构建“模型-系统-芯片”三层贯通的技术生态,通过“一次开发跨芯迁移”的方式释放硬件计算潜力,并打破不同芯片软件栈之间的隔离壁垒。 社区官网:https://flagos.io GitHub地址:https://github.com/flagos-ai GitCode地址:https://gitcode.com/flagos-ai |
| 关于HAI
高性能应用服务(Hyper Application Inventor,HAI)是一款面向AI和科学计算的GPU环境产品,提供即插即用的强大算力与常见开发环境,帮助中小企业及开发者快速部署LLM。 HAI社区则是一个针对AI、科学计算等GPU环境的容器镜像中心,提供了丰富的官方维护和社区贡献的资源。它支持企业和开发者迅速部署AIGC大模型、计算机视觉、自然语言处理以及数据科学等多个领域的容器,并原生集成开发工具与组件。 社区官网:https://haihub.cloud.tencent.com/index |
本文系量子位授权转载自智源研究院,观点为原作者所有。