
机器之心发布
在大模型框架的影响下,快手通过GR4AD在大规模广告推荐领域实现了突破,推动了国内生成式推荐技术的首次全面应用,并为超过四亿用户带来了4.2%的广告收入增长。

论文链接:https://arxiv.org/pdf/2602.22732
一、引言:"如何进行推荐"的新思路
近十年来,深度学习推荐模型(DLRM)几乎成为工业界推荐系统的主导力量。然而,在大语言模型(LLM)兴起后,人们开始思考能否直接生成推荐结果。
此思想在自然场景中得到了验证,但当转向大规模广告系统时,情况变得复杂得多,因为这类系统对延迟、收益和商业价值有着极高的要求。
快手的研究论文提供了一种工业级解决方案。GR4AD是一个集表征学习和服务为一体的生成式推荐广告系统,并已在快手平台全面部署。
快手的这篇论文,正是对这一问题交出的一份沉甸甸的工业级答卷。他们提出了GR4AD(Generative Recommendation for ADvertising),一个横跨表征、学习、服务三大层面协同设计的生成式广告推荐系统,并已全量部署于快手广告平台,服务超过 4 亿用户
二、挑战与难题:广告场景下的核心问题
直接将LLM的训练和推理方法应用于广告推荐并不适用,原因在于广告场景存在独特的三个挑战:
挑战一:如何统一编码广告内容中的多模态信息及其业务信号。
广告包含视频创意、商品详情等多元信息,以及转化类型和账户等关键商业指标。这些信息没有明显的语义意义,因此设计一个既能捕捉语义又能编码业务信息的Token体系成为难题。
挑战二:如何在最大化商业价值的同时进行列表级优化。
广告推荐的目标远不止于预测用户点击行为,而是要在eCPM排序和NDCG等指标下实现收益最大化的优化。传统的生成式方法并不完全适用于大规模广告场景的持续在线学习。
挑战三:在高QPS和低延迟条件下快速生成大量高质量候选广告。
与LLM聊天应用不同,广告系统需要极短时间内的高效处理能力,并通过Beam Search同时生成多个优质选项。这提出了一个全新的推理优化问题。
三、方法:全链路协同设计的破局之道
三、解决方案:全链条设计的创新路径
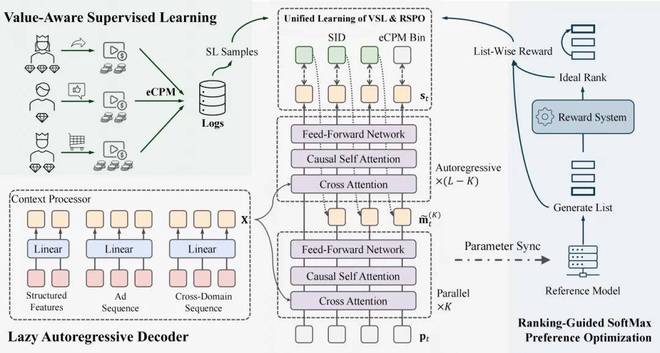
GR4AD的方法可以概括为“表征-学习-推理”的统一策略,下面将分别介绍:
3.1 统一广告语义ID(UA-SID):为每条广告创建唯一的标识符。
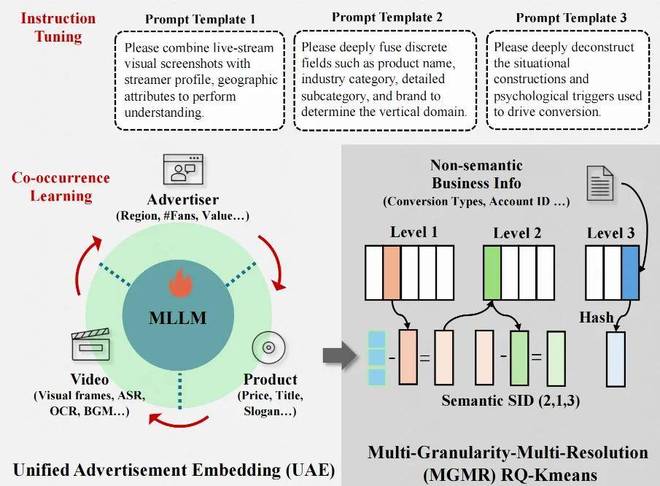
通过一个端到端微调的多模态大模型生成统一嵌入,并进行指令和共现学习,以提高SID的质量。MGMR量化技术的应用进一步提升了编码效率。
- 3.2 值感知的学习与优化(VSL + RSPO):结合价值感知训练信号和列表级NDCG优化算法。
- VSL用于基础分布的学习,而RSPO则在模型排序与奖励排序偏差小时加强精细化价值优化。两者通过样本级对齐分数动态调整权重实现统一在线训练。
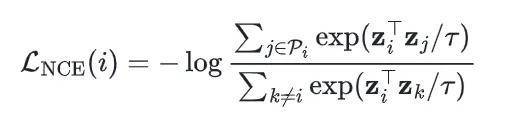
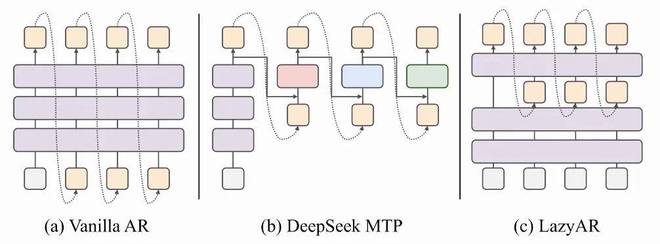
3.3 推理技术的创新(LazyAR + DBS):针对推荐特性的专门设计和效率提升机制。
LazyAR技术在保证精度的同时大幅提高了吞吐量,DBS则通过动态Beam宽度和流量感知自适应调整实现了更高的推理性能。
- 多分辨率(MR):低层级使用更大的码本捕获主导语义因子,高层级用较小码本建模低熵残差,有效提升码本利用率。
- 四、实施与优化:工业系统的闭环解决方案
GR4AD已在快手广告系统中全面部署,并形成了“奖励评估-在线学习-实时索引-实时服务”的完整闭环体系。

奖励模型用于生成候选集的eCPM评分,确保训练信号的质量;在线模块则实现了VSL和RL两种训练方式的持续更新推送。
实时索引利用SID替代传统嵌入,提升冷启动物料覆盖度与时效性;服务引擎负责处理用户请求并返回排序广告列表。
论文的一个关键观察是:第一层 SID 最难学、损失最大,但它的 Beam 只有 1(从 BOS 开始);后续层级更容易,Beam 却呈指数级膨胀。 大部分计算被浪费在了 "简单的事情" 上。
五、效果评估:收入增长及推理效率双丰收
- RSPO作为单组件优化贡献最大,显著优于其他方法,证明了列表级RL在广告场景中的重要性。LazyAR则通过极小的精度损失换取吞吐量翻倍的关键技术优势。
- 动态Beam搜索进一步提升了效率,在低峰期还能反向提升收入水平。
为什么 LazyAR 有效?
GR4AD不仅实现了显著的商业化效果,还系统地解决了生成式推荐在工业级广告场景中的实施路径问题。其独特性在于不照搬LLM技术,而是专门针对广告特性进行设计与优化。该研究对于未来更多广告平台采用这一范式的推进具有重要启示意义。
2. 前 K 层在潜空间中进行推理,能编码关于候选 token 的有用信号。
3. 引入 MTP 辅助损失,强制前 K 层即使没有上一步 token 也能学到足够信息。

论文特别指出:这个设计是推荐原生的,不适用于标准 LLM 解码 —— 因为 LLM 解码通常不用 Beam Search,且后续 token 的预测难度不一定下降。
3.3 价值感知的监督学习(VSL)
在广告场景中,不同样本的商业价值天差地别。VSL 围绕 "价值感知" 做了三件事:
①SID + eCPM 联合预测: 在标准 SID 交叉熵损失之外,将 eCPM 离散化为桶并追加为额外的预测 token:

②价值感知样本加权: 每个样本的权重 ,高广告价值用户和深度交互行为(如购买)获得更高权重。

③MTP 辅助损失: 配合 LazyAR,强制前 K 层并行解码的表征质量。
最终 VSL 目标:

3.4 排序引导的强化学习(RSPO):从 "学分布" 到 "优排序"
VSL 能拟合历史数据分布,但它不直接优化下游排序目标,也不支持对未知标签分布的探索。论文因此引入了 RSPO(Ranking-Guided Softmax Preference Optimization),一个面向列表级 NDCG 优化的 RL 算法
RSPO 的核心 loss
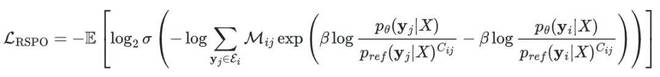

几个精妙的工程设计:

- VSL 与 RSPO 的统一在线训练:通过样本级对齐分数动态调整两个目标的权重 —— 模型排序与奖励排序偏差大时加重 VSL(学好基础分布),偏差小时加重 RSPO(精细化价值优化)。
四、线上部署:工业级系统的全闭环设计
GR4AD(0.16B 参数)已全量部署于快手广告系统,实现了一套 “奖励估计 → 在线学习 → 实时索引 → 实时服务” 的完整闭环。
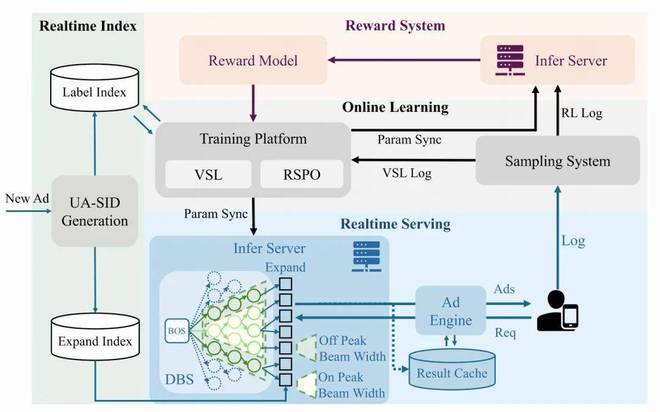
4.1 四大核心模块
- 奖励系统(Reward System):训练独立的 Reward Model 对 GR4AD 生成的候选集进行 eCPM 评分,在放松延迟约束的环境下进行更大 Beam 的探索,为 RL 训练提供高质量信号。
- 在线学习模块:实时构建 VSL 和 RL 两种训练信号,持续进行 mini-batch 更新,实时推送参数到推理服务。
- 实时索引模块:用 SID 替代传统嵌入索引。新物料到达时只需计算 UA-SID 并更新双向索引(UA-SID ↔ Item ID),秒级生效,大幅改善冷启动覆盖和时效性。
- 实时服务引擎:处理用户请求并返回排序广告列表。
4.2 推理效率优化:把算力用在刀刃上
动态 Beam 服务(DBS)是本文的又一亮点,包含两个子机制:
- 动态 Beam 宽度(DBW):用递增的 Beam 调度(如 128→256→512)替代固定宽度(512→512→512),在不损失最终候选质量的前提下大幅削减中间层计算。
- 流量感知自适应 Beam 搜索(TABS):根据实时 QPS 自动调整 Beam 规模 ——低峰期加大 Beam 提升推荐质量,高峰期收缩 Beam 保障延迟和吞吐
此外还有一系列工程优化:Beam 共享 KV Cache:将 Beam 从 batch 维度转移至序列维度进行组织,实现 KV Cache 的共享,显著提升内存访问效率(+212.5% QPS)、TopK 预裁剪:先并行选取每个 Beam 的 K 个候选结果,再对聚合候选集进行全局 Top-K 选择,在有效缩减搜索空间的同时保证准确性(+184.8% QPS)、FP8 低精度推理(+50.3% QPS)、短 TTL 结果缓存(+27.8% QPS)。
最终效果:<100ms 延迟,500+ QPS/L20 GPU
五、实验效果:广告收入和推理性能的双赢
5.1 总体性能与消融实验
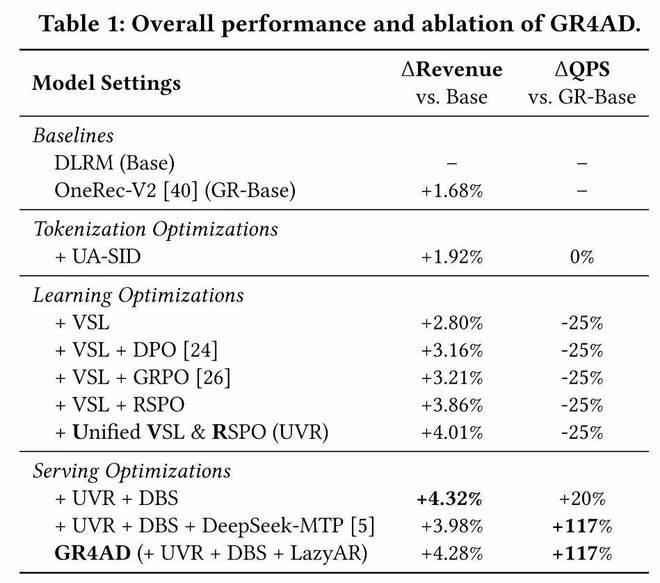
几个关键发现:
- RSPO 是所有优化中增益最大的单一组件,显著优于 DPO 和 GRPO,验证了列表级 RL 在广告场景的不可替代性。
- LazyAR 以极微小的精度代价换来了吞吐量翻倍,是实际部署的关键使能技术,优于 DeepSeek-MTP。
- DBS 在不损失收益的前提下进一步提升了效率,TABS 机制在低峰期还能反向提升收入。
5.2 Scaling Law
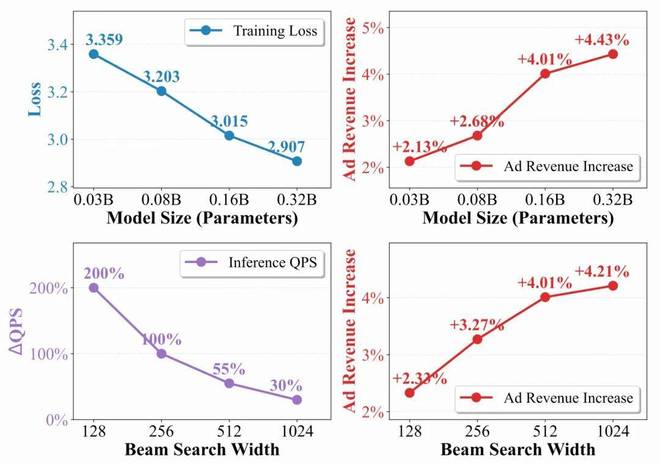
模型规模方向:从 0.03B 到 0.32B,收入提升从 + 2.13% 单调增长到 + 4.43%,训练损失也持续下降。生成式广告推荐的 Scaling Law 是成立的
推理规模方向:Beam 宽度从 128 增加到 1024,收入从 + 2.33% 提升到 + 4.21%。这意味着更强的推理时搜索能进一步释放模型潜力—— 这与当前 LLM 领域 Test-time Scaling 的趋势遥相呼应。
5.3 UA-SID 质量
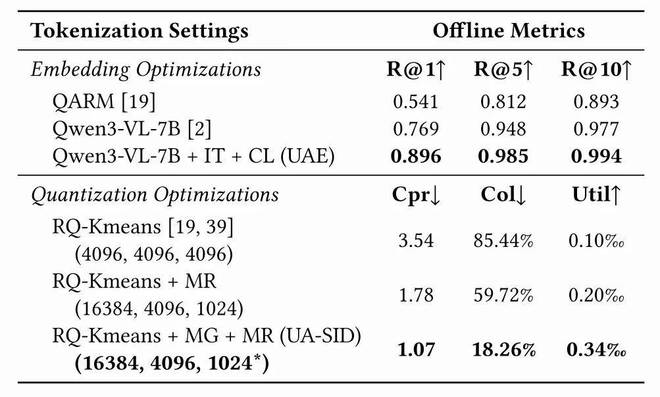
在嵌入质量评估(photo-to-photo recall)中,经过指令微调和共现学习的 UAE 达到了 R@1=0.896,远超基线 QARM(0.541)和原始 Qwen3-VL-7B(0.769)。MGMR 量化将 SID 碰撞率从 85.44% 降至 18.26%,码本利用率提升 3 倍以上。
5.4 商业指标的全面胜利
- 商业化广告收入4.2%+
- 中小广告主投放量提升17.5%
- 广告转化率提升10.17%
- 低活用户转化率提升7.28%
基于内容的 SID 带来的更强泛化能力和更实时的索引对冷启动物料的更好支持,实现了平台、广告主、用户的三赢
六、总结与思考
GR4AD 这篇论文的价值,不仅在于它达成了 4.2% 的收入提升这个数字,更在于它系统性地回答了一个关键问题:生成式推荐在广告这个最 "硬核" 的工业场景中,到底应该怎么做?
它的答案是:不要照搬 LLM,要做推荐原生的设计
- Token 化不能只看内容语义,要把业务信号编码进去(UA-SID + MGMR)。
- 训练不能只做单点概率生成,要做价值感知的列表级优化(VSL + RSPO)。
- 推理不能只套用 LLM 加速技巧,要针对 "短序列、多候选、Beam Search" 的推荐特性做专门设计(LazyAR + DBS)。
- 系统不能离线批处理,要做实时索引、在线学习、闭环反馈的全链路打通。
GR4AD 是生成式推荐走向广告工业核心场景的一个重要里程碑。 快手用超过 4 亿用户的真实流量验证了这条路径的可行性。可以预见,接下来会有更多广告平台跟进这一范式。