
深度体验:腾讯推出QClaw,无缝对接微信,无需复杂操作即可上手
机器之心编辑部今天看到一张令人捧腹的梗图:近期,OpenClaw 引起了广泛关注,但高昂的成本让许多用户感到压力巨大。腾讯 推出了基于 OpenClaw 开源生态的 QClaw 版本,旨在简化安装流程,方便普通用户使用。现在,即使是非专业人士也能轻松体验「小龙虾」的魅力了。类似于 OpenClaw,QClaw 让人们能够通过对话的方式控制电脑,并连接主流大语言模型如 DeepSeek、Kimi 和
科技192 阅读
共找到 57 篇相关文章
机器之心编辑部今天看到一张令人捧腹的梗图:近期,OpenClaw 引起了广泛关注,但高昂的成本让许多用户感到压力巨大。腾讯 推出了基于 OpenClaw 开源生态的 QClaw 版本,旨在简化安装流程,方便普通用户使用。现在,即使是非专业人士也能轻松体验「小龙虾」的魅力了。类似于 OpenClaw,QClaw 让人们能够通过对话的方式控制电脑,并连接主流大语言模型如 DeepSeek、Kimi 和

最近,“养龙虾”的活动在网络上迅速流行起来。开源AI智能体工具OpenClaw因其图标形似红色龙虾而得名,它可以通过调用通讯软件和大语言模型,在用户的电脑上自主处理诸如文件管理、邮件收发及数据整理等复杂任务。随着“养龙虾”风潮的蔓延,多家企业已经正式宣布推出相关的“龙虾”版本,并且部分地区的政府机构也开始将该工具应用于政务服务领域。不过,“养龙虾”的行为也带来了不少的风险和隐患。3月11日,在社交
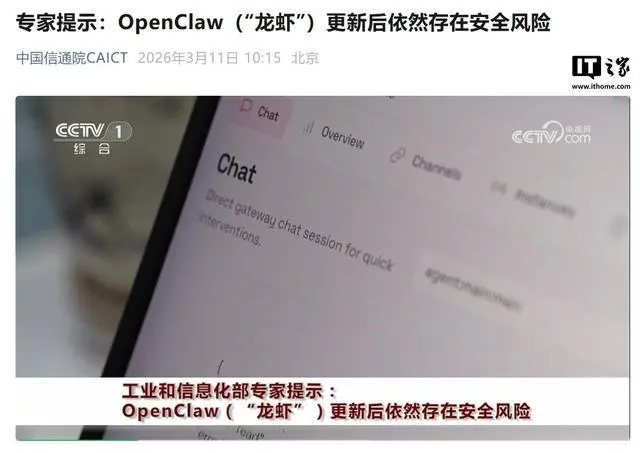
中国信通院 CAICT 公众号于今日发布文章称,开源 AI 智能体工具 OpenClaw 近期在网络上引起广泛关注,同时也带来了严峻的安全问题。此智能体因其图标形似一只红色龙虾而被网友昵称为“龙虾”,能够通过整合调用通信软件与大语言模型,在用户的电脑上执行文件管理、邮件收发和数据处理等复杂任务。尽管该工具具备强大的自主操作能力,但也给用户带来了严峻的安全挑战。工信部网络安全威胁和漏洞信息共享平台已

大语言模型在数学计算、指令执行和智能决策方面表现突出,展现出强大的思考能力。然而,在实际应用中,一个问题逐渐显现:大语言模型的推理成本难以控制。在一些看似简单的任务上,模型有时会过度思考,生成冗长且发散的答案,浪费大量计算资源却未能提高准确性。我们称这种现象为“过度思考”。对于复杂问题而言,由于预算限制,模型可能在关键环节草率作答,导致错误频出,这被称为“思考不足”。目前主流的做法是通过统一减少推

最近,「AI 教父」杨立昆终于有机会证明他的观点:大语言模型并非通向通用人工智能的正确道路。作者|桦林舞王当地时间 3 月 9 日,由他创立的 AMI Labs 宣布完成了一轮融资,金额达 10.3 亿美元,估值达到 35 亿美元——这是欧洲历史上最大的种子轮之一。投资者包括了英伟达、贝索斯家族的投资机构以及新加坡淡马锡等知名公司,同时还有一众科技界重量级个人投资者如 Tim Berners-Le

这是一次关于AI技术发展及其对软件工程影响的深入对话,探讨了从模型设计到应用实践等多个方面。 本次访谈中,Jeff Dean分享了他对当前大语言模型的看法,并强调了未来的发展趋势。 在讨论多模态能力时,Dean指出,早期强调视频输入是为模型提供最高带宽的沟通方式。 关于Gemini项目的起源和进展,Dean提到多个团队独立研发算力分散的问题及整合后的成果。 谈话中还探讨了在编程任务上使用AI助手

近期arXiv面临投稿量激增的问题,连这个平台也感到压力山大了。 一项由《自然》杂志报道的新研究显示,AI“水论文”现象愈发严重,这项研究的发起人之一是arXiv的创始人Paul Ginsparg。 arXiv负责人亲自介入的原因很简单:近年来投稿量激增导致系统不堪重负,而问题源头很可能是AI技术的发展。 为了验证这一点,研究人员测试了13个主流的大语言模型,看看当用户明确要求“编造数据”、“虚

从傅盛的分享中可以感受到他对AI技术的深刻理解和应用体验。他强调了AI在自动化执行任务方面的能力,并认为“三万”龙虾能极大地提升效率和创造力。凤凰网科技 出品作者|赵子坤傅盛提到,尽管大语言模型如EasyClaw(简称“三万”)能够完成许多复杂的任务,但它仍需人类设定明确的目标才能发挥作用。这说明了AI在自主决策上存在局限性。他指出,当前社会中技能交换的模式正在发生变化,人们需要从基础教育开始适应

新智元报道近期的一项研究揭示了苹果M4神经引擎的真实性能,包括其在大语言模型中的潜力。这项工作由Ronald Mannak和Maderix共同完成。Maderix通过逆向工程的方式深入挖掘了苹果的M4神经引擎(ANE),发现其真正能力远超官方描述。该研究证明,在正确的网络结构下,ANE能够在2.8W功耗条件下实现19 TFLOPS FP16性能。这标志着苹果硬件在能效方面具有显著优势。研究中还详细

我是李国豪,目前专注于大语言模型和代理研究领域。本科毕业于哈尔滨工业大学电子信息工程专业,并在沙特阿卜杜拉国王科技大学(KAUST)攻读博士学位。我的学术兴趣从强化学习延伸到图神经网络,最终聚焦于大语言模型及其应用。作者|王艺我的兴趣演变始于强化学习,但很快发现它难以解决跨领域问题的泛化性挑战。因此,我转向探索更通用的表征学习方法,并研究图神经网络(GNN)。然而,在ChatGPT出现之后,我发现
在3月4日凌晨,阿里巴巴Qwen团队的技术领导者林俊旸通过社交平台宣布即将离任,并深情地写道:“再见了,我深爱的Qwen。”作为阿里云通义千问项目的先锋人物以及公司最年轻的P10级技术专家之一,他在该项目中发挥了关键作用。林俊旸不仅领导了Qwen大语言模型及其多模态模型系列的研发工作,还负责推动这些模型的开源进程。他本科毕业于北京大学计算机科学系,并在该校外国语学院攻读硕士学位,专业方向为语言学与

新智元报道本文探讨了如何在给定硬件约束条件下使大语言模型达到最优性能的研究成果,并揭示了软硬协同设计的重要性。研究表明,传统的堆算力方法并不足以充分发挥芯片的潜力,优化架构才是关键所在。马赫100自研芯片与星环OS操作系统、MindVLA智能驾驶大模型共同构成了理想汽车完整的技术栈,并通过软硬协同设计实现高效能利用。在传统模式中,开发团队通常需要花费数月时间才能为新硬件找到最优的架构方案。然而,借
美军近期对伊朗发动袭击时采用了AI大模型“克劳德”。(央视新闻曾报道)《华尔街日报》援引美国《参考消息》称,据匿名消息来源透露,在最近的空袭中,美军使用了由Anthropic公司开发的大语言模型“克劳德”,尽管美国总统特朗普在几天前下令停止与该公司合作。据报导,五角大楼利用人工智能(AI)处理情报、确定目标及模拟不同场景。这表明Anthropic公司的模型已融入美军的决策系统中。此外,在针对委内瑞

近年来,基于大语言模型的多智能体系统(MAS)在复杂推理任务中得到了广泛应用。传统方法通常让多个独立生成决策的代理通过投票或辩论等方式进行聚合,从而提高算术、常识推断及专业问答等领域的准确率。当test-time compute成为常见的性能提升策略时,一个自然而然的问题随之产生:随着agent数量的增加,MAS是否能够持续增强其能力?直观上来看,这种想法似乎是合理的:类似ensemble或sel

全球首个深度思考的扩散模型诞生! 它摒弃了传统的自回归模式,成为世界上生成速度最快的模型。 对比之下,传统自回归的“打字机式”输出方式(逐个token按顺序生成)就像乌龟一样慢: 实际测试结果显示,在英伟达GPU上运行的Mercury 2扩散推理大语言模型可实现每秒1009个tokens的速度。 这一速度比GPT-5(mini版)和Claude-4.5(haiku版本)等传统模型快了五倍之多

过去两年间,大型语言模型在推理领域的进步显著。从数学与编程生成到解决复杂的逻辑和科学问题,这些模型不断刷新基准测试的记录。随着“推理模型”概念的兴起,越来越多的研究开始将推理能力视为通向通用人工智能的关键标志。在能力迅速提升的同时,一个更为基础的问题逐渐显现:当模型在执行推理任务时出现错误,这些失误是随机波动还是表明了深层次的设计缺陷?近期发表于 TMLR 的论文《大型语言模型推理失败》对该问题进

在评估大语言模型(LLM)生成代码的能力时,一个日益凸显的问题浮现出来:当这些模型在 HumanEval 和 MBPP 等经典基准测试中取得近乎饱和的成绩时,我们究竟是在衡量其真实的泛化推理能力,还是仅仅检验它们对训练数据的记忆力?目前的代码基准正面临两大核心挑战:一是数据污染的风险,二是测试严谨性的不足。前者可能使评测退化为「开卷考试」,而后者常常导致一