最近,普林斯顿大学的研究团队发布了新的开源通用视觉推理RL框架——Vero。
 鱼羊
鱼羊该研究指出,数据的广泛性是推动视觉推理强化学习发展的关键因素之一。
Vero由刘壮领导,并得到了陈丹琦的重要贡献。该项目旨在提供一个适用于各种视觉任务的训练平台。
在此之前,尽管许多大型模型已经展示了强大的视觉推理能力,但相关的强化学习方案多为私有化模式,并未广泛共享。
Vero团队认为,通过合理的资源和技术投入,在学术领域也能够实现与顶尖工业界团队相媲美的成果。
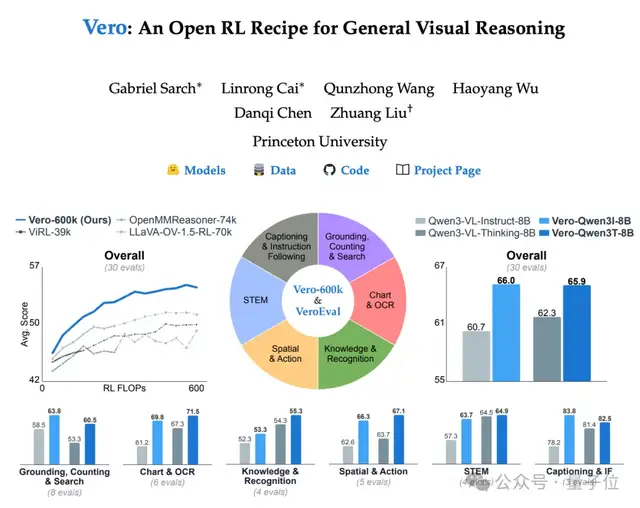
该开源框架解决了以往通用视觉任务中模型训练的局限性,使单一任务训练不再成为瓶颈。
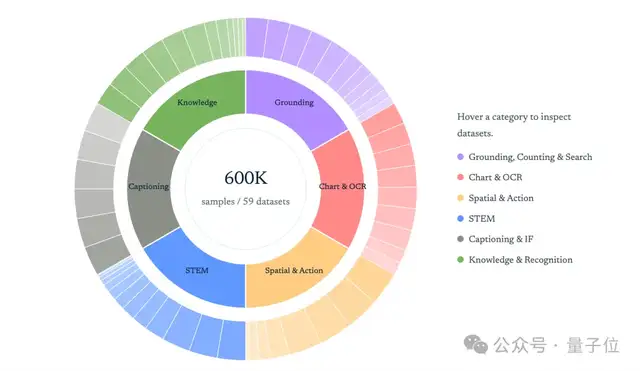
研究人员发现,不同类型的视觉推理任务需要不同的策略和能力。为解决这一问题,他们创建了一个包含60万高质量样本的数据集——Vero-600K。
这个多样化数据集包括图表与OCR、空间与动作、知识与识别等多种类型的任务。
通过广泛的训练数据覆盖,模型能够学习到更加通用的视觉推理模式,并且避免了在单一任务上过度优化导致的能力下降问题。
此外,Vero团队还提出了一种创新性的任务路由奖励机制。该系统可以根据不同的任务类型自动分配相应的验证器来计算奖励。
这一机制确保了模型能够根据具体任务的需求灵活调整输出策略,从而提高了整体的准确性和效率。
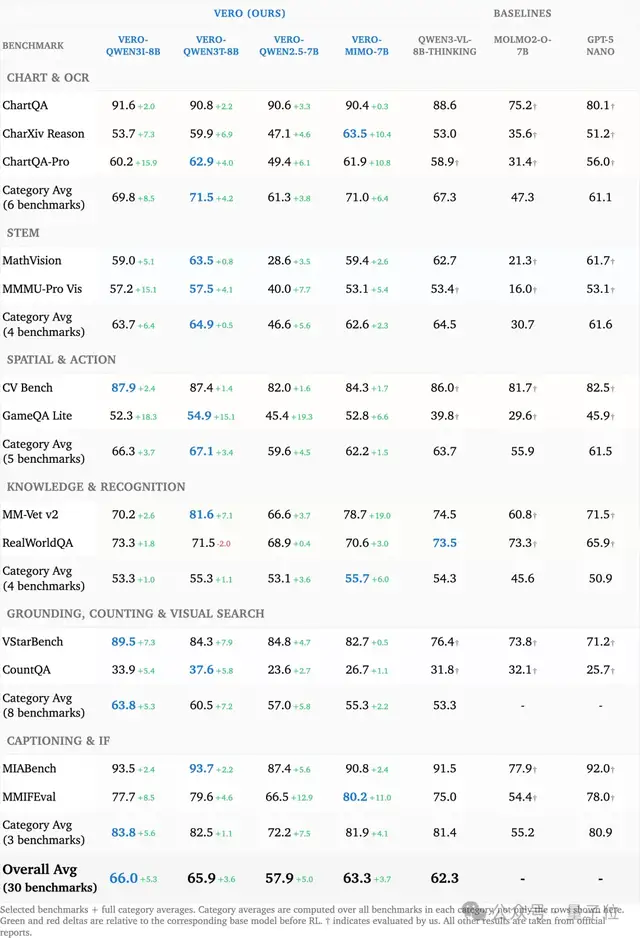
实验结果表明,在没有使用任何私有“思考”数据的情况下,基于Vero训练的模型在多项基准测试中超越了经过专门微调的Qwen3-VL-8B-Thinking。
该团队还通过一系列消融实验验证了广泛的数据覆盖对视觉推理强化学习的重要性。
目前,所有相关的数据、代码和模型均已向公众开放。
该项目的主要贡献者包括普林斯顿大学的博士后研究员Gabriel Sarch及硕士生Linrong Cai,陈丹琦也是其中一位通讯作者。
Gabriel Sarch在卡内基梅隆大学获得博士学位,并继续从事视觉语言模型中的推理研究工作。
这些样本被分为六类:
- Linrong Cai是天津第一中学的校友,在威斯康星大学麦迪逊分校完成了本科教育,目前在普林斯顿攻读硕士学位。
- STEM
- 项目负责人刘壮则来自清华大学姚班,博士毕业于加州大学伯克利分校,并在Meta FAIR担任高级研究科学家期间与谢赛宁合作开发了ConvNeXt模型。
- 刘壮的多项研究成果受到了业界的高度认可,包括CVPR 2017上获得的最佳论文奖。
- 定位、计数与搜索(Grounding,Counting & Search)
- 描述与指令遵循(Captioning & Instruction Following)
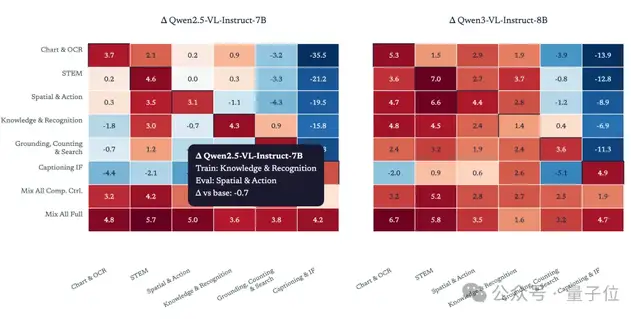
研究人员发现,单任务RL训练出来的模型无法实现可靠的泛化,针对某一类别的训练往往会降低模型在其他任务上的表现。
相比之下,在广泛且均衡的数据集上进行RL训练, 模型能够学到通用的视觉推理模式,避免了在单一任务上训练导致的能力退化。
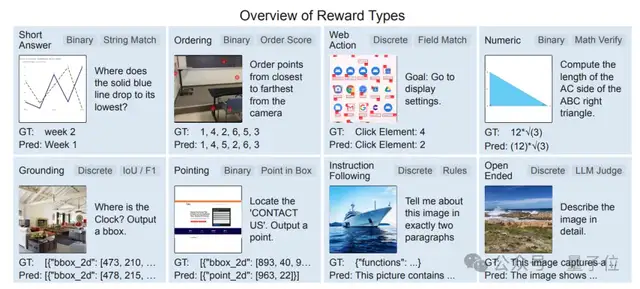
任务路由奖励机制(Task-Routed Rewards)
在视觉推理中,不同任务的答案格式之间其实存在很大的差异。
为此,Vero提出了任务路由奖励机制:设计了一套多路奖励系统,能根据任务类型的不同,自动把输出路由给相应的验证器,来分别计算奖励。
比如,对于选择题,评分标准是选项选得是否正确;对于数学题,则需要数学校验;对于开放描述,Vero会引入另一个大模型作为裁判,来评估回答的质量。
单阶段强化学习
相比于闭源模型依赖于私有“Thinking”数据的强化学习方案,Vero提出:
只要拥有高质量的数据过滤、均衡的任务混合,以及精确的路由奖励,仅仅通过单阶段强化学习,就能激发基础模型的通用视觉推理能力。
实验结果显示,在没有引入任何私有“思考”数据的情况下,基于Vero训练的模型在30个基准测试中的23项上,超越了经过专门微调的Qwen3-VL-8B-Thinking。
研究团队的消融实验还表明:
广泛的数据覆盖是视觉推理强化学习Scaling的主要驱动力。
目前,Vero的所有数据、代码、模型均已开源。
研究团队
Vero的两位通讯作者是Gabriel Sarch和Linrong Cai。
Gabriel Sarch博士毕业于CMU,目前是普林斯顿大学PLI(Princeton Language and Intelligence)的博士后研究员——
论文的作者之一陈丹琦,现在也是PLI的副主任。
Linrong Cai,天津第一中学校友。本科毕业于威斯康星大学麦迪逊分校,目前正在攻读普林斯顿大学计算机科学专业硕士学位,师从刘壮。同时Gabriel Sarch也是他的mentor。他的研究方向是视觉语言模型中的推理。
刘壮则是Vero的项目负责人。刘壮本科毕业于清华姚班,后于加州大学伯克利分校获得博士学位,现在是普林斯顿大学计算机科学助理教授。
在CVPR 2017上,刘壮的一作论文DenseNet获得了最佳论文奖。ConvNeXt则是他在Meta FAIR任高级研究科学家期间,和谢赛宁合作发表的成果。
在Meta期间,刘壮和何恺明、LeCun等亦有深度合作。
项目地址:
https://vero-reasoning.github.io/