中国具身模型在全球独占鳌头!机器人步入人类数据时代
 鹭羽
鹭羽灵初智能仅凭10万小时的数据集,便一战成名
这批年轻创业者凭借自身实力,在业内迅速崭露头角。
目前行业内的大部分数据集规模较小,大多集中在几千到几万小时之间。而英伟达的EgoScale包含约两万小时的数据。
灵初此次推出的新数据集则达到了一个新的高度:10万+时长,并且开源了其中一千小时的部分。
此次发布采用了一种新颖的方式——直播形式,吸引了大量关注者。
在这次直播中,AI博主弗兰克与灵初智能的联合创始人陈源培深入解析了具身智能的关键问题。
总结来说,整场活动主要讨论了两个关键点:如何为机器人训练提供高质量的数据以及设计出合适的架构体系。

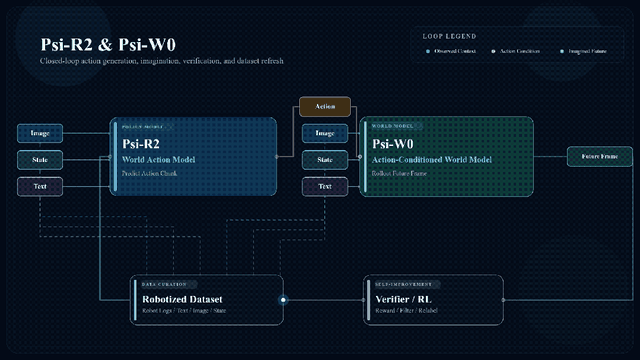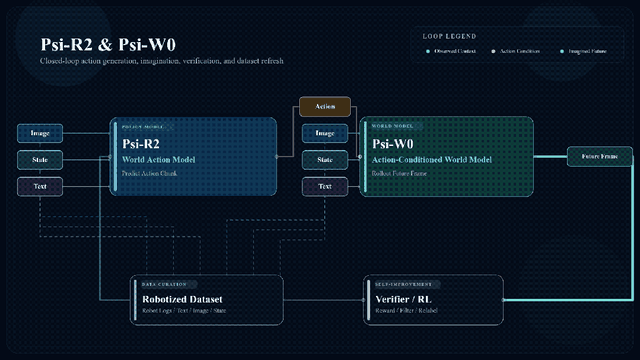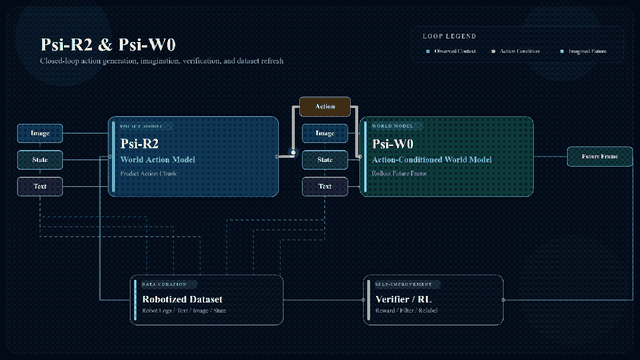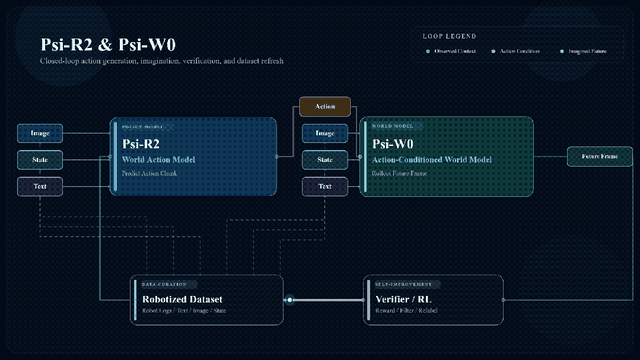
灵初提出的方案是直接从人类数据中提取信息,并使用Psi-R2和Psi-W0双系统来实现落地应用的目标。
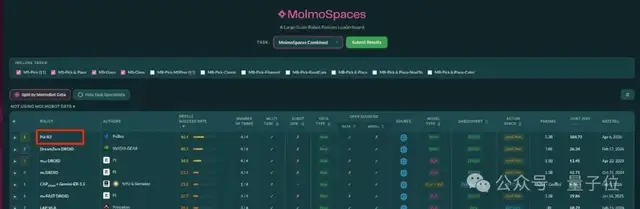
这一策略取得了显著成效,使得灵初的Psi-R2模型在MolmoSpace平台上的测试中遥遥领先。
MolmoSpace由美国艾伦人工智能研究所发起,是全球公认的具身智能技术评测标准之一。众多顶尖团队参与了此次评估。

灵初的成果不仅超越了其他竞争者,还表现出比传统基线模型更高的成功率。
具身智能面临的数据短缺问题,灵初通过大规模的人类操作数据集来解决。
为了回答为何具身智能会遭遇“数据荒”的疑问,首先要认识到这类技术与自动驾驶或大语言模型等领域的固有差异。
后者可以通过累积大量现实场景和互联网的数据,在计算资源的加持下不断优化性能。
然而,物理世界的复杂性意味着具身智能难以找到成熟的数据集,也难以像其他产品一样通过实际使用来积累数据。
因此,灵初选择了人类数据作为突破口。直接利用人类操作的真实记录可以极大地节省成本和时间。
例如,在收集触觉数据方面,机器人所需的成本远高于人类的十倍以上。
另一方面,采用人类标准作业流程的数据能让机器人更快速地掌握复杂任务,并符合商业环境中的高效率要求。
灵初通过大量的人类操作数据训练出首个大规模的操作数据集。这为机器人的预训练提供了坚实的基础。
这个过程包括了从清洗到标注,再到质量检测等一系列完整的流程处理。
在捕捉人类手部动作方面,灵初利用外骨骼手套将误差控制在亚毫米级别,以保证机器人能够精准复制操作细节。
Psi-R2作为世界行动模型(WAM),通过图像和语言指令预测未来操作视频与执行动作。但其反应速度较慢,需要进行优化处理。
为此,灵初利用缓存、编译等技术手段将单次推理时间缩短至100毫秒以内。
另一模型Psi-W0则专注于通过机器人视角预测未来场景,并提供失败情况的模拟训练。
相比之下,Psi-R2仅能输出成功的操作策略,而不能预测可能遇到的问题。因此,Psi-W0在填补这一空白方面扮演了重要角色。
这两个模型共享相同的架构和数据格式,在训练过程中加入了额外的失败样本。

Psi-W0通过强化学习将人类动作转换为机器人可以执行的动作指令,并持续生成新的优质数据以供进一步学习使用。
该系统能够支持长程任务规划、自主恢复以及复杂场景下的应用需求。
在直播中,两位嘉宾一致强调技术落地的重要性。灵初智能不仅注重大规模真实人类操作数据采集,还与多家企业达成生态合作。
这一策略体现了公司自成立以来就致力于提供通用全栈解决方案的承诺。
从长远来看,开源是推动整个行业发展的关键手段之一。它有助于构建广泛的技术生态系统,并促进具身智能技术的发展和普及。
对于灵初来说,早期进入市场并积累大量数据将使其在未来获得持续的竞争优势。
他们的成功不仅源于对未来的远见卓识,还在于脚踏实地的执行力和实践精神。
这场由年轻团队引领的技术革新风暴正在为整个行业带来新的面貌。
另一方面,人类数据的SOP也可以使操作速度达到机械臂物理运动上限(如1200),远超遥操作可达的800,也更适配商业工厂的高节拍要求。

所以灵初最终选择了人类数据,并造出了首个可用于预训练的大规模人类操作数据集。
其中,在人类数据和机器人数据的融合处理中,灵初遵循的是一条化繁为简的思路:Raw Data In,Raw Data Out(原生数据进,原生数据出)。
舍弃人工设计的复杂数据处理,直接进行人类关节与机器人本体的运动学对齐,让模型在海量数据中自行探索。另外,Auto Labeling也会替代人工进行数据质检和标注,最后再交由人工审核。
最终模型预训练使用的数据集将包括真机数据(5417小时)和人类数据(95472小时)两部分,总计10万小时数据。
目前其中1000小时已开源,到年底整个数据集还将Scaling到百万量级。
具体来讲,人类数据包括灵初自研外骨骼手套采集数据与裸手操作数据,覆盖294种场景、4821种任务与1382种物体。

至于为什么要强调触觉数据呢?归根结底,还是为了更好地弥补人机之间的embodiment gap。
虽然人类与机器人在多个方面差异明显,但二者在接触信号上却保持了惊人的高度一致,能够有效补偿动力学差异,以及在显著提升世界模型能力的同时,还能更好地预测机器人与物体之间的交互情况。
这样一整套高质量数据预训练下来,机器人的泛化能力、长流程操作能力和操作精度都会有所突破,后续也仅仅只需要不到100条轨迹的真机数据就能完成微调。
另外值得关注的是,灵初在此期间,还发现了另一处华点:
数据信噪比才是决定人类数据能否有效支撑预训练的核心因素。低信噪比的数据甚至还会起到反作用。
如果要想判断数据信噪比,可以从两方面看:
1、数据集分布:操作任务多样性>物体多样性>>场景多样性。
泛化能力其实是模型最难学会的能力之一,但如果在预训练阶段可以见到更多任务和操作对象,自然而然模型接手新任务速度就越快。
2、感知模态:精准3D位姿>>触觉模态>2D图像特征。
在全模态信息中,人手全域3D位姿追踪是2D到3D模型转化的关键,也和机器人动力学特性匹配度最高。

简单来说,灵初认为无论是精准采集的可复现数据,还是舍弃部分精度的粗糙泛化数据,都缺一不可。
二者相互补充,既保证模型精度又确保泛化。
具身智能长出双系统新脑
所以基于以上认知,灵初全新发布Psi双系统架构——Psi-R2和Psi-W0。

先看Psi-R2,这是一款能让机器人学习人类做事的模型,核心就是靠这10万+的海量数据,学会精细操作。
图像和语言指令将作为输入,输出预测的未来操作视频和可执行动作,所以Psi-R2可以称之为世界行动模型(WAM)。
其中训练骨干网络选用Wan2.2-IT2V-5B-480P,预训练阶段同步使用真机数据和人类数据,还搭建了一套完整的数据处理流程,从数据清洗、自动标注,到质量检测、人工核对,Psi-W0还会帮忙检查数据质量。
同时,采用专门技术精准捕捉人类手部动作轨迹,比如通过外骨骼手套,将动作误差控制在亚毫米级,以确保人类的操作细节能被机器人精准模仿。

视频链接:https://www.psibot.ai/from-human-skill-to-robotic-mastery/
但WAM模型架构普遍存在一个bug——反应慢。单次推理要2.2秒,反映到机器人身上,就是明显的卡顿。
于是灵初通过DiT缓存、Torch编译、模型量化等多项技术优化,把反应时间极限压缩到了100毫秒以内。
再看Psi-W0,它和Psi-R2的基础架构相似,但分工完全不同。Psi-R2是学习怎么做,Psi-W0是协助做得更好。
首先它和Psi-R2一样,都是基于预训练视频生成模型构建的,但在Psi-W0里,机器人动作是输入,输出的是对未来场景视频的预测,所以Psi-W0也被定义为动作条件型世界模型(AC-WM)。
这里就引出了另一个问题:Psi-R2也能输出预测,那为什么还要做Psi-W0?
答案很简单,为了反事实推理。Psi-R2学到的只有成功的操作,比如成功抓起苹果,但没有办法预测到苹果抓不稳这类失败情况。
但老话说得好,失败是成功之母,机器人亦是如此。失败经验能够帮助机器人避开错误、优化动作,Psi-W0就是专门负责填补这部分空白。
具体来讲,两个模型的训练骨干和数据格式都是一致的,只是在Psi-W0的训练数据中额外加入了30%的失败样本。

视频链接:https://www.psibot.ai/from-human-skill-to-robotic-mastery/
显然,Psi-R2和Psi-W0并非孤立存在,而是彼此之间协同配合。当Psi-R2学完人类操作后,Psi-W0就会模拟人类操作场景,让Psi-R2再演练一遍,也就是进行策略评估,检查它有没有学漏学歪。
Psi-W0还有一项核心功能,是通过强化学习将人类数据转换为机器人数据。
传统方法中,数据转换靠的是仿真环境调整,不仅复杂而且准确性不高。但用Psi-W0替代后,它就会模拟机器人视角和动作模式,再通过强化学习的试错调优,将人类动作调整为机器人能精准执行的动作。
更厉害的是,在这个过程中还能持续生成新的优质数据,当把这些数据反向喂给Psi-R2和Psi-W0继续学习,就能构成闭环数据飞轮。
当然也可以故意给Psi-W0进行随机扰动以模拟部分特殊场景,然后再生成目标场景和训练数据。
高质量数据滋养模型高性能,模型场景落地反哺数据扩充。于是自然而然,轮子飞起来了。
最终整套系统能够实现长程任务自主规划、任务自主恢复和适配多场景复杂任务。
开源是最高效的落地杠杆
回看整场直播,无论是弗兰克还是陈源培聊的内容,其实贯穿技术始终的都是同一个关键词——落地。
弗兰克站在观众角度,好奇什么时候具身智能才能落地。陈源培则站在厂商视角,给出了灵初智能的落地方案:
技术端,从大规模的真实人类数据采集,再到实际应用中的具身模型,无一不是从切实的落地场景中出发构建。
应用端,灵初智能也同时宣布要和北京石景山共建数采厂,以及和腾讯云、抖音、觅蜂、智域基石达成生态合作。

不难看出,灵初这家公司从诞生之初的DNA就是聚焦技术落地、提供通用全栈技术。它的每一步都在验证一个行业共识:
具身智能从诞生之初就锚定的终点,绝非实验室,而是每一个具体可感的复杂场景。而这恰恰才是检验具身智能的标准所在。
在通往落地的过程中,灵初也率先意识到,单打独斗并非最优解,开源是必要的。
对于它们自身而言,只有开源,才能让全行业帮助他们快速采集海量数据,才能弥补上这套数据飞轮体系中的关键一环。
而且AI时代,时间和数据就是最稀缺的黄金资源。越早进场、拥有越多数据,就能抢先收获长尾效益。
再放眼整个行业,开源不仅是情怀,也是打破技术封闭孤岛的钥匙。它能够建立起广袤的开发者生态,通过标准化的数据管线和预训练底座,让具身智能不再是孤立的厂商个体。
而全行业开源共建,还能反向喂养灵初这类硬核玩家,让他们集中精力攻坚最难的技术瓶颈。集众智,才是具身智能跑赢节拍、实现商业落地的唯一捷径。

而灵初无疑是当中走得最快最稳的一位明星选手。
最后化用一句老话,用来描述我眼中的灵初智能——有仰望星空的勇气,亦有脚踏实地的努力。
具身智能正在因这场青春风暴而面目一新。