近日,一篇关于新稀疏注意力机制的研究论文引起广泛关注。
论文提出了一种名为HISA(Hierarchical Indexing Sparse Attention)的新方法,成功解决了大模型中的索引瓶颈问题,并提高了计算效率。
相较于现有的DeepSeek Sparse Attention (DSA) 方法,HISA不仅速度提升了2至4倍,而且无需额外的微调步骤便能实现即插即用的效果。

研究团队在多种大模型上验证了HISA的有效性,包括DeepSeek-V3.2和GLM-5,在保证原有精度的同时大幅提高了性能。
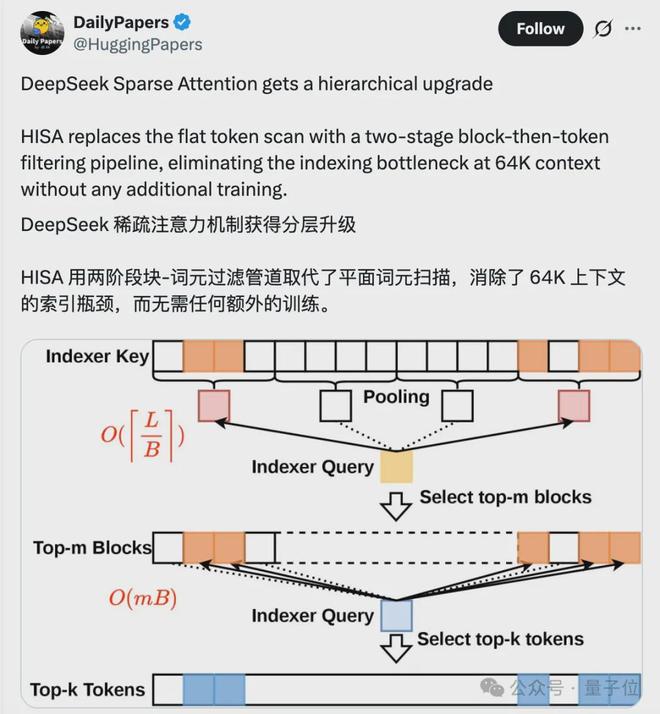
HISA的核心创新在于通过分层索引的方式优化计算过程,从而有效地降低了复杂度并减少了计算资源的消耗。
这种方法首先将长文本分割成固定大小的小块,并为每个小块生成一个整体特征向量以进行初步筛选。
紧接着,在选择出最具潜力的小块后,再对其内部的内容进行精细检索和评估。
通过这种方式,HISA不仅能显著减少计算成本,还能保证结果的准确性和实用性。
目前主流的token级稀疏注意力机制虽然提高了效率,但在处理超长文本时却面临着巨大的挑战。
这主要是由于索引阶段的工作量随着文本长度呈平方增长,导致性能瓶颈难以突破。
为解决这一问题,HISA采用了分层检索策略来简化搜索过程,同时保持了最终注意力计算的准确性。
此外,论文还指出,当采用适当的块大小和选块数量时,HISA在不同长度的文本上都能表现出良好的性能稳定性。
这一特性使其非常适合大规模的实际应用需求,尤其是在处理超长上下文场景下具有显著优势。
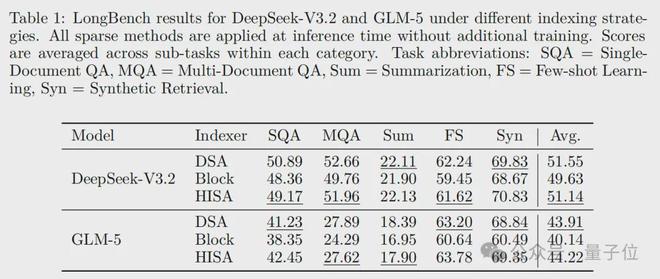
实验结果显示,在64K长度的文本测试中,HISA比传统的DSA方法提高了高达3.75倍的速度,并且在所有评估指标上均达到了与原方法相媲美的精度水平。
这项研究由北京大学张牧涵教授团队完成,他们提出的创新技术为未来的大规模语言模型优化提供了新的思路和方向。
张牧涵现为北京大学人工智能研究院的助理教授兼博士生导师,在加入北大之前曾在美国Facebook AI(现Meta AI)担任研究员。
他的研究成果受到了广泛的认可,谷歌学术引用量超过一万三千次,是国际上具有重要影响力的学者之一。
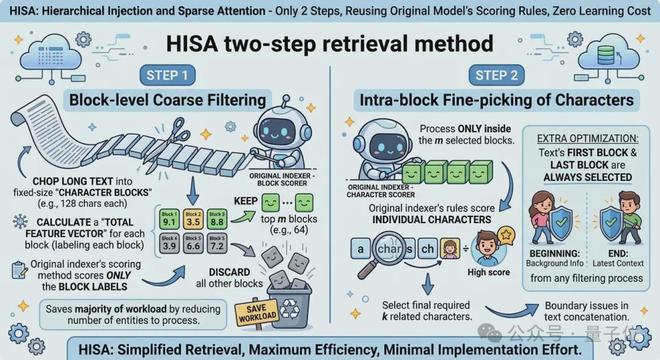
块级粗过滤
- 把长文本切成固定大小的 “字符块”(比如128个字符一块),给每个块算一个 “整体特征向量”(相当于给每块贴个总标签)
- 用原索引器的打分方式,只给这些块标签打分
- 挑出分数最高的m个块(比如64个),直接扔掉剩下的所有块——块的数量远少于字符数。
这一步能省掉绝大部分工作量。
块内精挑字符
只在第一步选出来的m个块里,用原索引器的规则给单个字符打分,再挑出最终需要的k个相关字符。
还加了个小优化:文本的第一个块和最后一个块必选,保证开头的背景信息、结尾的最新上下文不被误筛,也能处理文本拼接的边界问题。
HISA的关键优势在于:复杂度骤降,还能 “无缝替换”
HISA把原索引器每一层 O (L²) 的算力成本,降到了O(L²/B + L×m×B)(B 是块大小、m 是选的块数)
文本越长、块选得越精准,提速效果越明显。
更重要的是它的工程友好性
输出和原索引器完全一致,下游的注意力计算模块不用改;
不用重新训练模型、不用调整KV缓存结构,直接替换原索引器就行;
短文本时会自动 “退化” 成原方法,只有超长文本时才触发分层筛选,全程自适应。
实测提速超猛,精度几乎没丢
论文在DeepSeek-V3.2、GLM-5两大主流大模型上做了全面测试,结果很亮眼:
速度上,在64K长度的文本下,HISA 比原DSA索引器最高提速3.75倍,常规设置也能提速2倍多。
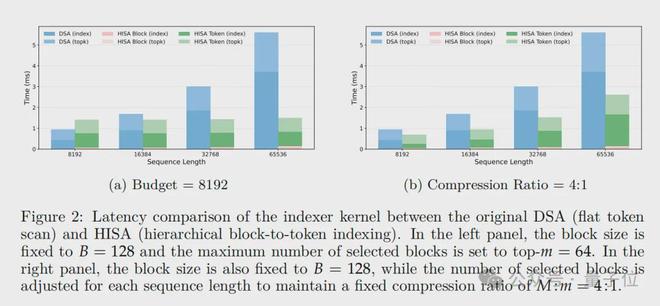
上下文长度越长,HISA的提速效果越显著,完全契合超长上下文(128K/1M)的实际应用需求。
精度上,HISA也几乎完全保留原DSA的精度,且显著优于纯块稀疏方法。
论文进行了“大海捞针”测试,该测试衡量在超长无关文本中,精准检索指定位置关键信息的能力。
结果HISA和DSA几乎一样准,在所有长度和插入深度下,检索精度均接近DSA的近乎满分。

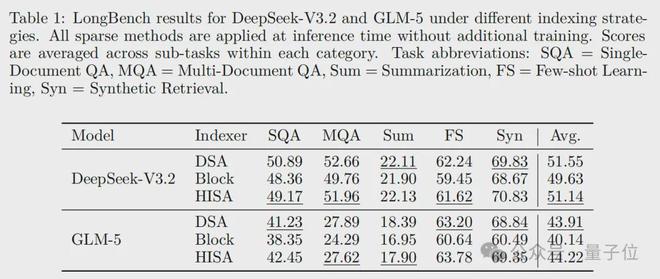
长文本理解(LongBench 基准)上,HISA的分数也和DSA基本持平。
甚至在部分场景,比如合成检索、少样本学习等对token筛选精度要求高的任务中,HISA做到了小幅反超。
而在超参数测试中,不同块大小、选块数量下,HISA表现都很稳定,分数均与DSA高度接近,无显著性能差异
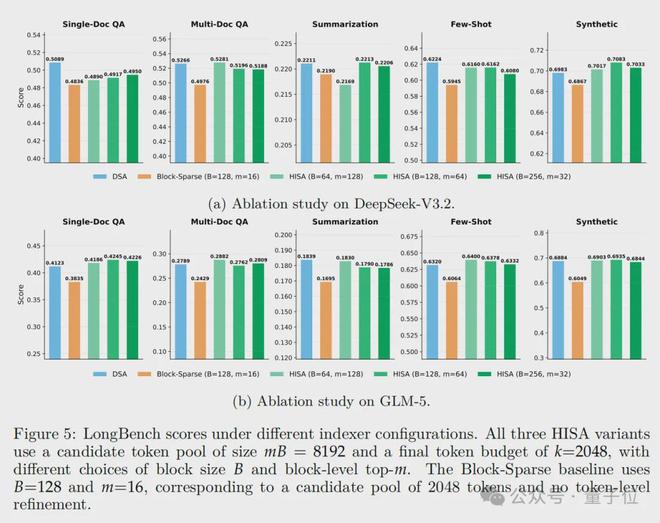
这也说明HISA对超参数的选择不敏感,鲁棒性强,工程落地时无需精细调参。
不过目前HISA还有小瑕疵,作者也提出了后续改进思路:
第一,现在块是固定大小的,若一个块里混了无关和相关内容,块的 “整体标签” 会不准。
未来可以搞自适应块、重叠块,或换更好的块特征计算方式。
第二,目前只是推理时直接用,未来可以把块筛选和模型一起训练,让筛选更精准。
第三,现在只测了索引器的速度,未来整合到完整的大模型服务框架里,测端到端的吞吐量和延迟。
团队背景
这篇论文出自北京大学的张牧涵团队。
张牧涵,北京大学人工智能研究院的Tanure-track助理教授和博士生导师。
回国前曾在Facebook AI(现为 Meta AI)担任研究员,从事大规模图学习系统和问题的研究。

其Google Scholar总引用量超过13000次,其中两篇一作文章引用量分别达到3100+和2400+次,连续多年入选Elsevier全球前2%顶尖科学家(生涯影响力榜单)
Yufei Xu(徐宇飞)和Fanxu Meng(孟繁续)为论文的共同一作。
[1]https://arxiv.org/abs/2603.28458