Meta团队耗时九个月打造的大规模语言模型终于问世了!这款新模型由余家辉、宋飏和Jason Wei等专家共同研发,旨在解决Llama系列之前的不足。
 一水
一水主打原生多模态
再见了,所有的羊驼。
亚历山大王领导的团队在短短九个月内完成了对Meta所有AI技术栈的重建工作,并成功推出了超级智能实验室的第一个项目:Muse Spark。
Muse Spark的主要特点在于其原生多模态能力。

模型发布后,Meta股价随即上涨了约7%,最高涨幅接近10%,最终收盘时增长了6%左右。
这一新产品的市场反响热烈。
对这款模型的研究表明,背后汇聚了一批业内顶尖的专家:包括思维链理论的主要作者Jason Wei、o1项目的核心贡献者Hyung Won Chung以及被马克·扎克伯格以高价挖来的余家辉等。
当这些专家共同合作时,不难发现一个关键点:推理能力。
Jason Wei透露,在九个月前的讨论中,他们就确定了要开发一款专为逻辑推理设计的语言模型脚本,并且现在这款完全体终于面世。
通过顶尖人才的努力与长时间的技术打磨,Muse Spark在第三方评测中的表现已经足以让Meta进入第一梯队,弥补了Llama系列过去的一些缺陷。
Meta这次的发布策略有所不同,他们并没有强调模型的所有技术优势,而是较为低调地表示:
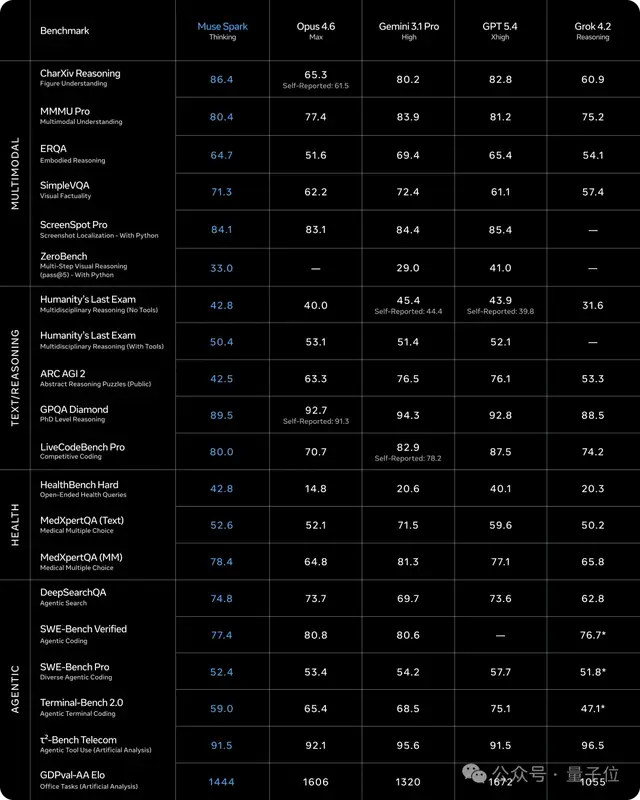
Muse Spark在多模态感知、推理以及健康问题领域表现出色,但在编程和持续性任务方面仍有提升空间。
这次的发布似乎也缓解了之前llama 4带来的负面情绪(doge)。
此外,Muse Spark的推出终于结束了关于Meta是否会选择开源道路的长期争论:
这次是真闭源了。
目前这款模型已经在Meta官网和应用程序中上线,并且API仅向部分合作伙伴开放。
(不过亚历山大王暗示未来可能会考虑将后续版本开源)
“Meta回来了”
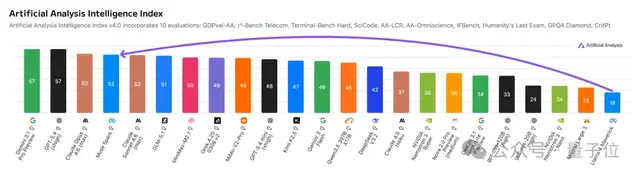
接下来,我们来看一下一些重要的测评结果。
作为Meta迄今为止最强大的语言模型,Muse Spark在以下几个方面尤为突出:
一是多模态理解能力。
在图像转代码、屏幕阅读以及论文图表分析等方面的表现均名列前茅或与Gemini 3.1 Pro、GPT-5.4等顶级产品旗鼓相当。
根据网友的测试反馈,它似乎对图片转码任务特别擅长。
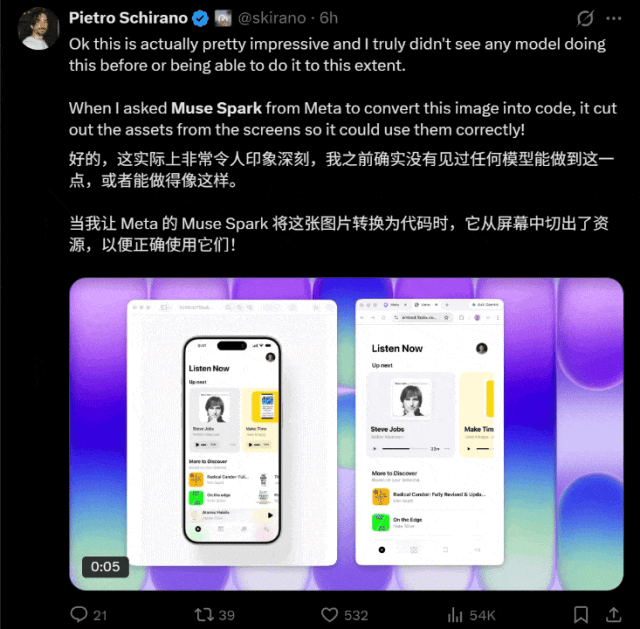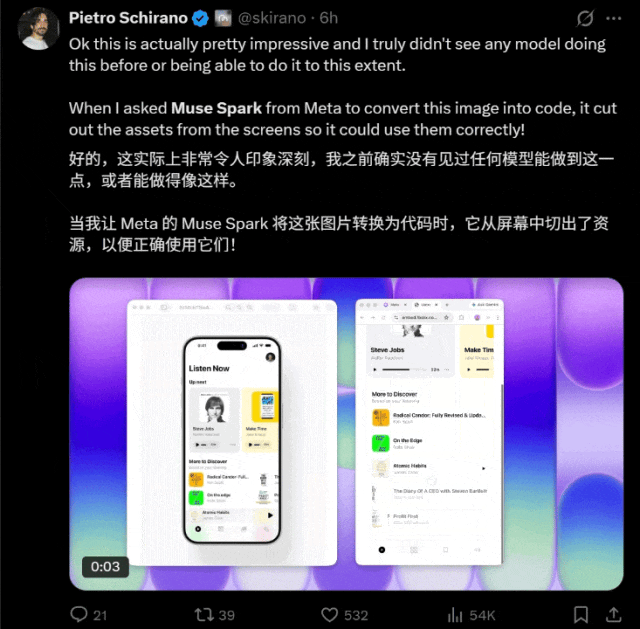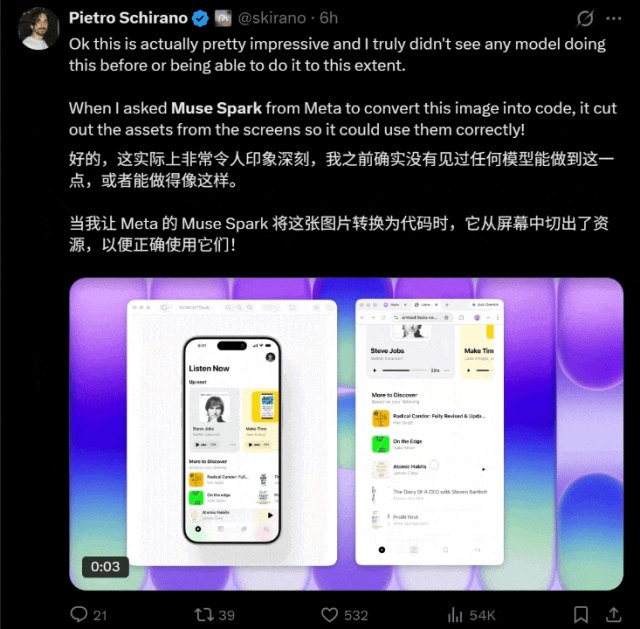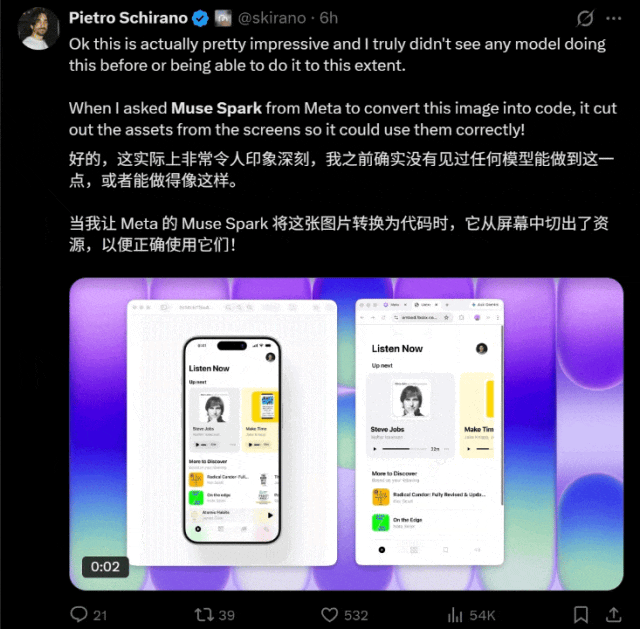
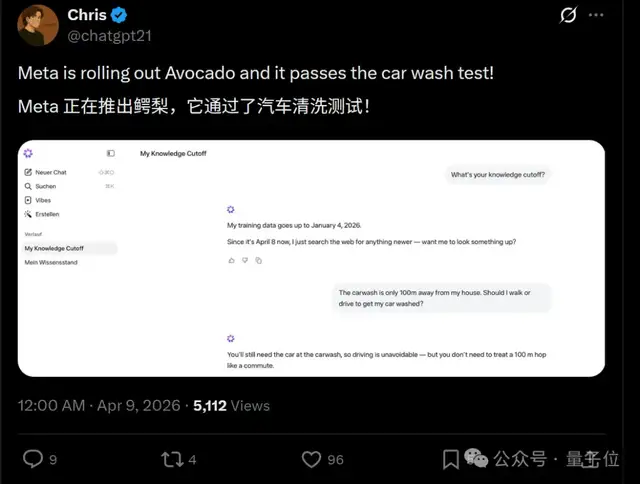
它在文本处理方面同样表现出色(doge),在近期的一次挑战中,轻松通过了新的“弱智吧”风格洗车问答题目的考验。
例如:如果离你一百米的地方有一家洗车店,你会开车去还是步行?Muse Spark的答案是应该开车过去,但不必像上下班那样频繁往返。
此外,它还具备强大的医学知识能力,在开放式健康问答和多模态医学问答的测评中表现出色。
不过在编程和自主任务执行上,Muse Spark仍存在一定的不足之处。
为了尽可能缩小这一差距,Meta团队推出了沉思模式。
这种新模式允许多个代理同时思考同一个问题,并汇总得出最佳解决方案。
在这种策略下,Muse Spark可以与Gemini Deep Think、GPT Pro等极限推理模式直接竞争。
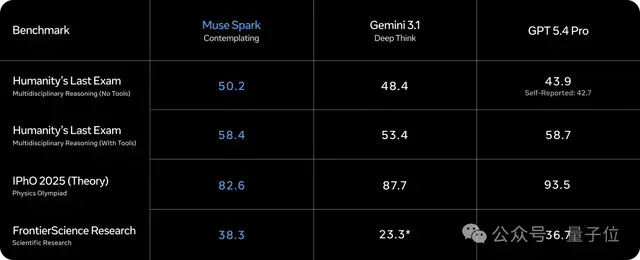
例如,在“人类最后的考试”中,它已经能够轻松应对大多数挑战(尽管在物理竞赛理论题上略逊一筹)。
目前沉思模式正在Meta网站进行灰度测试。
另外值得一提的是,Muse Spark还推出了购物助手功能。
亚历山大王表示,这款模型会根据用户在ins、Facebook和Threads上的偏好信息提供个性化的购物建议。
这次Meta没有给外界留下太多讨论的空间,因为OpenAI之前因为广告问题而受到不少批评。
随着Muse Spark的发布,第三方机构也给出了自己的评测报告:
他们认为Meta已经重新回归人工智能领域的领先地位。
在关键的人工智能分析指数上,其成绩仅次于Gemini 3.1 Pro、GPT-5.4和Claude Opus 4.6。
这一结果也与Muse Spark团队的自我评估基本吻合。
对于外界而言,初步来看,Muse Spark确实帮助Meta重新回到了人工智能的第一梯队。
关于Muse Spark如何实现这一突破,Meta还详细介绍了背后的训练细节。

亚历山大王指出关键在于:九个月的重构工作。
新的技术基础设施、架构以及数据管道均得到了全面升级。
背后训练细节
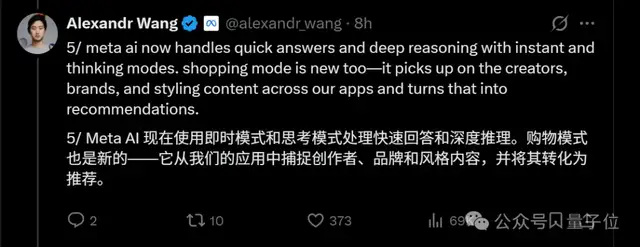
在预训练阶段,与Llama 4相比,Muse Spark在使用更少计算资源的情况下达到了相似的效果。
强化学习阶段显示了平滑且可预测的性能提升,并具有良好的泛化能力。
测试时间阶段,在引入长度惩罚机制后,“思维压缩”开始生效,模型学会了用更少的token来解决问题。

所有改进都旨在提高每单位算力的价值。
- 为了验证这一点,他们进行了一系列对比实验:用小模型模拟出“计算能力-性能”的Scaling曲线,并据此估算达到特定性能所需的资源量。
- 结果显示,在相同水平下,Muse Spark相比Llama 4减少了十倍以上的计算需求(10.3倍)。
- 预训练完成后,他们利用强化学习进一步增强模型能力。

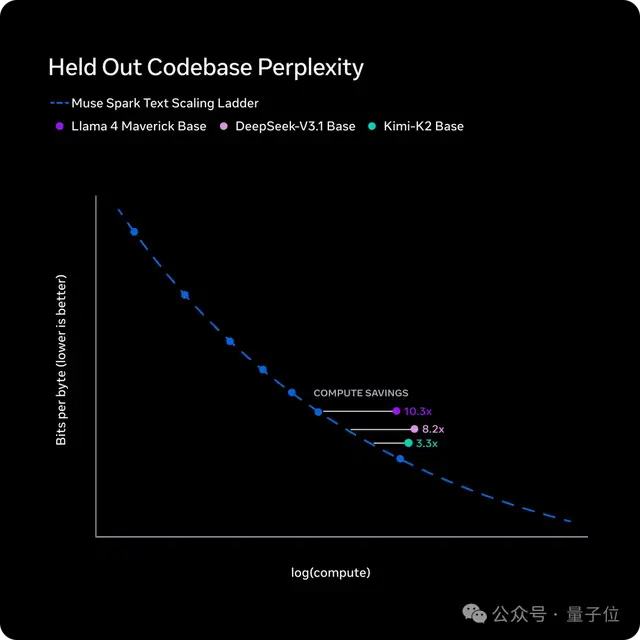
尽管大规模RL训练通常不稳定,但Meta的新架构声称可以稳定提升性能。
如图所示,随着训练步数增加,模型在训练数据上的成功率呈现对数线性增长。
这证明了强化学习既能提高可靠性又不会破坏推理多样性。
同时,在前所未见的任务上准确率也稳步提升——这表明能力的增强具有可预测性和泛化性,并非简单的机械记忆。
为了实现模型在回答复杂问题前的“思考”阶段,团队继续使用强化学习训练其这种测试时推理的能力。
然而,在这一阶段,由于token使用的高昂成本,如何提高效率成为了关键挑战。
Meta团队采用了两种核心策略来解决这个问题:
一种是时间惩罚机制,鼓励模型用更短的推理路径得出正确答案,迫使它学会“思维压缩”;
另外一个是多智能体协作模式,多个代理或模块共同作业,在不牺牲响应速度的前提下提升整体表现。
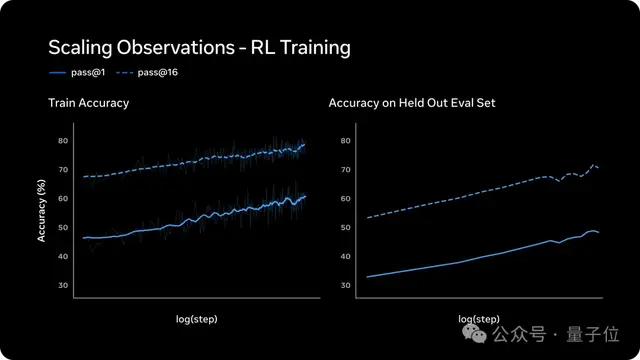
在像AIME这样的高难度测试集上,他们观察到了一个有趣的三阶段变化:
模型最初会自动延长思考时间以提高正确率;
但是很快就会触发“思考时间惩罚”,迫使模型简化推理流程,学会用更少的token解决问题。
而在精简之后,模型进一步展现了扩展性能——能够在高效的基础上继续优化解法,最终实现用较少资源获得更强的表现力。
尽管Muse Spark已经将Meta带回了第一梯队,但在编程和代理类任务上仍有改进空间。
新模型发布后不久便出现了一些翻车案例:
有人尝试使用它生成网站,结果三个请求都没成功,并且基础的前端功能也缺失;
后来才发现这可能是偶然错误,在正常情况下模型可以顺利实现这一任务。
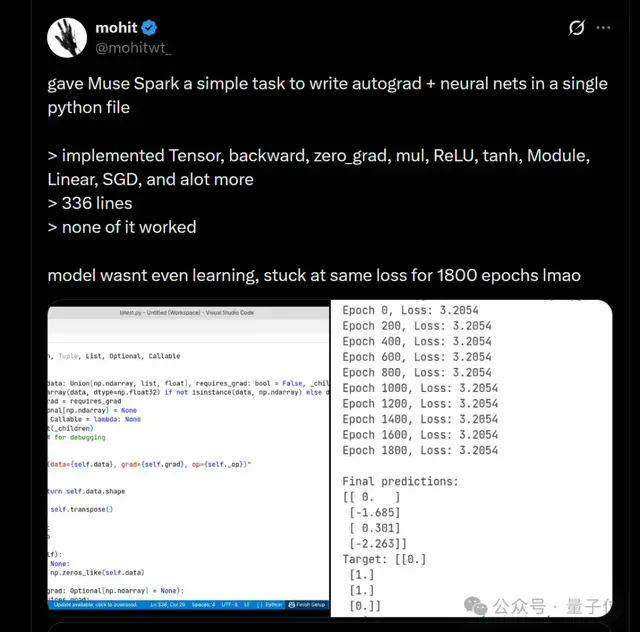
在一个简单的编程测试中,Muse Spark虽然产生了很多代码但大多数都不运行;
也不乏翻车的
对于在Python文件中自动微分和神经网络的实施,结果同样不佳。
甚至有网友戏称,训练了1800个周期后损失函数值却一直停滞不前(正常情况下应逐步下降)。
那么问题来了,有试用过的朋友们认为亚历山大王的第一个作品如何呢?
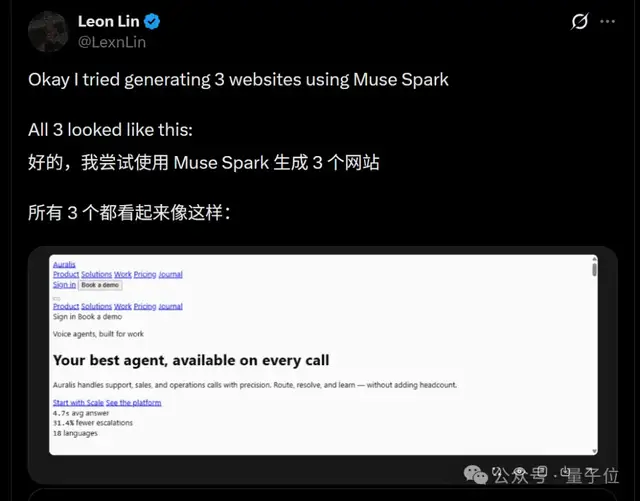
不过后来贴主发现可能是偶然错误,模型正常情况下做出来的前端是这样的。
一个简单的编程任务,Muse Spark虽生成了一大堆东西,但根本跑不通。
在一个Python文件里实现自动微分(autograd)和神经网络。
网友甚至调侃,模型根本没在学,训练了1800个epoch,损失函数却一直卡在同一个值上没动过。
白白浪费算力了……
(正常情况下,随着训练进行损失应该逐步下降,表明模型在“学习”)
所以问题来了,有试过的朋友觉得亚历山大王的首个模型如何?