
该论文的第一作者为北京大学硕士生安睿川,他是在张文涛教授和鄂维南院士的共同指导下完成的研究工作。研究重点在于统一生成理解模型以及以数据为中心的人工智能领域。安睿川已发表过4篇关于一作或共一作者身份的论文,并曾在微软亚洲研究院实习。该项目的通讯作者由北京大学的张文涛教授担任。
在AGI-Next前沿峰会上,姚顺雨提出了一个极具争议的观点:大模型实现高价值应用的关键在于能否有效利用上下文信息。近期OpenAI研究员Jiayi Weng也在一次访谈中表达了类似的见解:上下文决定了模型与人类认知的界限。当信息不对等被消除后,普通人也能胜任顶尖工作——这本质上反映了处理上下文的能力是智力差异的重要因素。
在这种共识的影响下,混元和复旦团队最近发布的CL-Bench显得尤为关键。作为姚顺雨加入腾讯后的首次亮相,CL-Bench设立了一个新的标准:它严格评估了模型在长时间交互过程中学习新知识的能力。
然而故事并未就此结束。
CL-Bench成功解决了理解输入端上下文的问题(即情境学习),但在生成输出时,我们发现了一个更为棘手的难题:
如果上下文不仅仅是用于「学」的知识,而是对「创造」行为的一种复杂限制,模型还能应对自如吗?
这正是GENIUS (Generative Fluid Intelligence Evaluation Suite) 诞生的原因。

- 论文标题:GENIUS: Generative Fluid Intelligence Evaluation Suite
- arXiv论文链接:https://arxiv.org/abs/2602.11144
- GitHub代码库地址:https://github.com/arctanxarc/GENIUS
- Unified Model 下半场 Blog(内含 Takeaway 和 Insight):https://chawuciren11.github.io/GENIUS/
从「晶体」到「流体」:
晶体智力指的是运用过去知识和经验的能力,现在的模型通过大量数据学习获得了惊人的晶体智力,可以精确地复制出一只完美的猫,因为它们在训练阶段见过数以亿计的例子,并能在推理时进行概率性的再现。
GENIUS的核心目标就是评估生成式模型在生成过程中的通用智能水平,而不仅仅是它们对「画一只更逼真的狗」这类任务的晶体智力依赖。
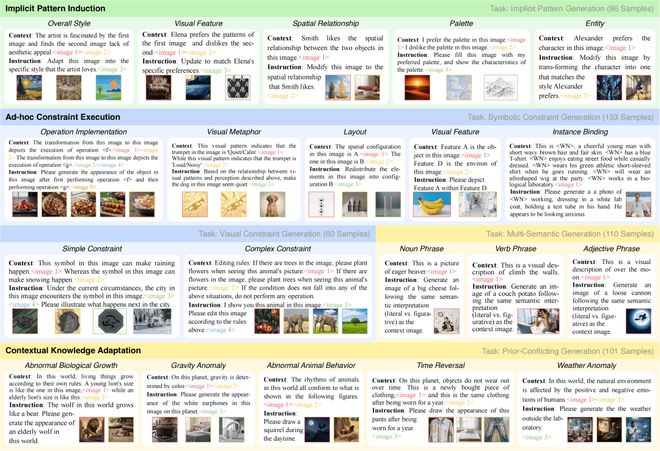
02 GENIUS基准:
隐式模式归纳(对应图一绿色部分)
执行即时约束(对应图一蓝色部分)
适应上下文知识(对应图一黄色部分)
解构生成式流体智力
03 实验结果分析
数据显示
晶体智力与流体智力的差距
预训练知识的障碍
模型失败的原因诊断:为什么成绩不佳?
常规推理策略的局限性
上下文理解是核心问题:我们在上下文中引入了显式的提示(包括纯文本提示与多模态提示),模型的生成质量有所提高。如果模型能够像人类一样深度解析语境,这一瓶颈理论上可以被打破。
生成失败主要源于执行能力不足
基于注意力的无训练增强
向通用生成智能迈进
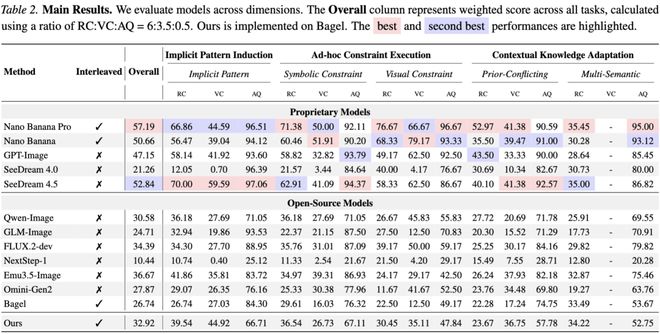
量化测评结果
[1] Learning without training: The implicitdynamics of in-context learning
[2] GENIUS: Generative Fluid IntelligenceEvaluation Suite
2. 预训练知识的阻力
在三大维度中,「适应上下文知识」的准确率普遍最低。这证实了模型存在严重的预训练知识阻力。例如在「反重力」任务中,模型往往会忽略 Context,顽固地生成符合现实物理规律的图像。这说明当前模型的思维具有很强的僵化性,缺乏人类那种在「现实」与「想象」模式间灵活切换的可塑性。
3. 故障诊断:为什么模型会不及格?
面对模型在流体智力上的溃败,我们并没有止步于分数的罗列,而是通过一系列诊断性实验,试图定位失效的根本原因。
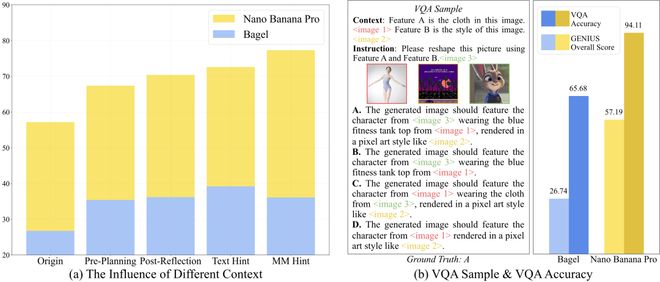
常规推理增强策略的失效:面对复杂的推理任务,直觉告诉我们要让模型「多想一会儿」。然而,如图三 (a) 所示,我们尝试了 Pre-Planning(思维链模式)和 Post-Reflection(测试时扩展,即生成-打分-再生成)等策略,结果却令人失望——带来的性能提升非常有限。这表明,GENIUS 所考察的流体智力,现有的推理范式并不能很好地迁移到这种多模态的即时生成任务中。
上下文理解是核心瓶颈:我们在上下文中引入人工编写的显式提示(Text Hint 纯文本提示与 MM Hint 多模态提示),模型(如 Nano Banana Pro)的生成质量能够得到进一步提升。这种显式提示本质上源于人类对语境的深度解析。如果模型能够构建起类人的理解机制,这一瓶颈在理论上是可以突破的。而在多模态细则约束下,部分模型(如 Bagel)甚至出现了性能回退,这直观反映了当前模型在处理多模态交错输入时的理解乏力。
生成性失败主要源于执行能力不足,而不是理解能力缺陷:为了验证模型对上下文的理解程度,我们将生成任务转换为视觉问答形式,如图三 (b) 所示。实验结果显示,模型在理解类任务上的成功率较高,证明其已具备相当程度的语境感知。导致「知而不能画」的现象主要归结为以下两个因素:首先,交错上下文具有极高的数据密度,其中细粒度的视觉差异难以通过有限的模态编码完全捕获与表达。其次,当前通用多模态模型的结构设计在信息传递上存在损耗,导致理解侧丰富的语义信息无法有效传导至生成侧,形成了认知与创作之间的断层。
04 方法论:
基于注意力的免训练增强

图四 注意力分布观察:左:Bagel 的注意力分布,右:我们改进后的注意力分布
基于上述诊断,我们进一步从底层机理探究了模型失效的根源。在多模态生成过程中,我们将生成图像的特征作为查询向量(Query),将图文交织的上下文作为键向量(Key),对注意力分布进行了可视化分析。结果表明,Bagel 模型在处理图像时的注意力分布异常杂乱,呈现出大量不规律的噪声与随机的激增。由此引出一个核心问题:注意力分布的偏移在多大程度上干扰了模型对上下文的理解?我们是否能通过对注意力权重进行轻量级调制,来实质性地提升模型的生成表现?
受到相关文献 [1] 的启发,我们将「上下文学习本质上是一个隐式梯度更新过程」这一理论,在数学上严格推导并拓展至 Bagel 的架构中(详细推导过程见论文 [2])。从这一理论视角出发,高质量的上下文能够为这种隐式的「梯度下降」提供明确且精准的优化方向。然而,Bagel 原生的注意力热力图揭示了一个致命缺陷:模型未能精确聚焦于上下文中必须关注的核心特征,其注意力权重呈现出无序的发散状态。这直接导致模型在隐式梯度更新时丢失了正确的下降路径,最终受困于预训练固化的数据分布中难以跳出。针对这一困境,我们提出了一种免训练的注意力校准机制,强制引导模型将注意力收敛于关键的视觉与语义区域。定性与定量实验均证实,该方法能够有效纠正模型的优化轨迹并带来显著的性能增益,为该领域构建了一个简单的基线。
05 总结与展望:
迈向真正的通用生成智能
GENIUS 的提出,旨在回应生成式 AI 发展进程中的一个核心命题:我们究竟需要什么样的智能?
当前的生成式多模态大模型已经在晶体智力上取得了令人瞩目的成就:它们能够完美拟合海量数据分布,复现高质量的视觉内容。然而,GENIUS 的评测结果揭示了繁荣背后的隐忧:一旦脱离了预训练的舒适区,面对需要即时推理、归纳与适应的流体智力任务,现有模型仍显稚嫩。
从「晶体智能的拟合」走向「流体智能的推理」,是生成式多模态大模型下一阶段发展的必经之路。
GENIUS 仅仅是一个开始。我们希望这一基准能为社区提供一个严谨的测试平台,推动生成式模型从熟练的「模仿者」,进化为具备真正通用推理能力的「思考者」。
引用:
[1] Learning without training: The implicitdynamics of in-context learning
[2] GENIUS: Generative Fluid IntelligenceEvaluation Suite