ICLR'26会议探讨了离线强化学习方法从局部优化向全局布局转变的新策略。
 一水
一水新算法的核心在于先构建整体框架,再细化细节。
当面对复杂的连续任务时,现有的生成式离线强化学习技术常常陷入困境。
它们所设计的路径虽然在某些方面看似合理,但总体上却偏离了正确方向。
这些方法过于专注于每一个步骤的具体执行,而忽略了最终目标的整体规划。

针对这个问题,厦门大学和香港科技大学的研究人员提出了一种名为MAGE的新算法。
相较于现有的序列生成策略,MAGE采用自上而下的“由粗到细”生成方式,先构建宏观路径的模型,然后逐步细化微观细节。
这一方法符合人类思维中的直觉:“从大处着眼、从小处着手”。
就像画素描一样,在描绘出全身轮廓后才会逐渐勾勒脸部特征。
(微观动作)
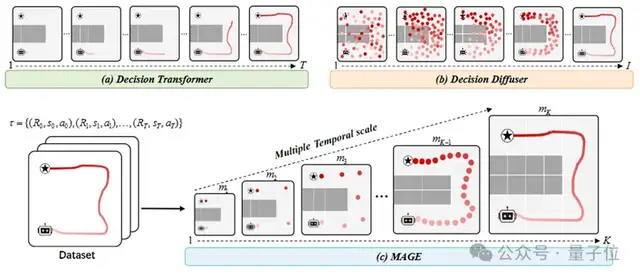
△MAGE的思考过程
通过迷宫寻宝实验揭示了AI规划的局限性
研究人员设计了一项迷宫吃金币的任务,用以展示现有模型的问题所在。智能体需从随机位置开始,根据环境的空间理解来决定路径,优先收集银币然后才是金币,并最终到达终点。
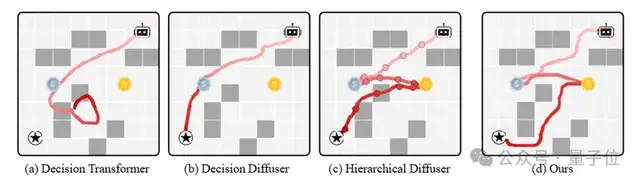
在这个需要整体规划的场景中,现有的模型表现出了明显的缺陷。
Decision Transformer由于缺乏全局上下文信息,在长程规划过程中迷失方向,无法达到终点。
- 决策扩散算法则因为生成过程中的局部偏差问题,虽然智能体能够到达目的地,但未能收集所有金币,整体连贯性较差。
- 层次化扩散算法尽管尝试通过分层结构来建模全局路径,但由于固定的层次设计过于僵硬,导致高低层级之间缺乏有效协作,生成的轨迹甚至出现了违反物理规则的现象。
- MAGE则利用多尺度“由粗到细”的架构成功完成了任务。它首先在最宏观的时间尺度上建立包含所有关键节点的整体框架,然后通过多尺度Transformer逐步细化,最终规划出完整的路径。
MAGE的核心理念:从画轮廓到细节描绘
MAGE采用“自顶向下、由粗至细”的生成方式。该方法包括两大核心模块,并配备了精确的调控机制:
MTAE多尺度轨迹自动编码器:MAGE将长序列路径转化为从宏观到微观的多尺度离散Token,确保全局结构和局部细节都被准确建模。
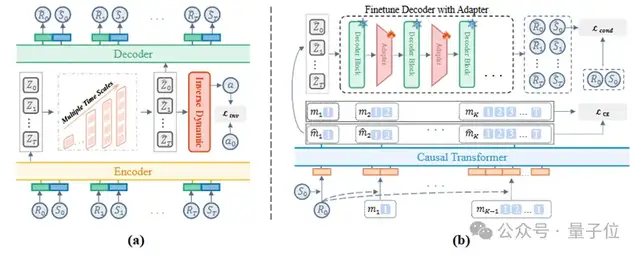
△MAGE的架构图
条件引导下的自回归生成过程:模型通过Transformer分层生成这些Token。每一层级都以“目标回报”和“初始状态”作为约束条件进行生成,保证智能体每一步行动都向着最终目标前进。
细化与决策结合的策略:由于连续世界的复杂性容易导致信息丢失,普通的生成过程可能会使轨迹起点偏离实际环境。MAGE通过在解码器中加入轻量级适配模块,并采用条件引导损失函数来确保初始状态和真实环境的一致性。
实验结果表明,在多个长序列任务中全面超越现有算法
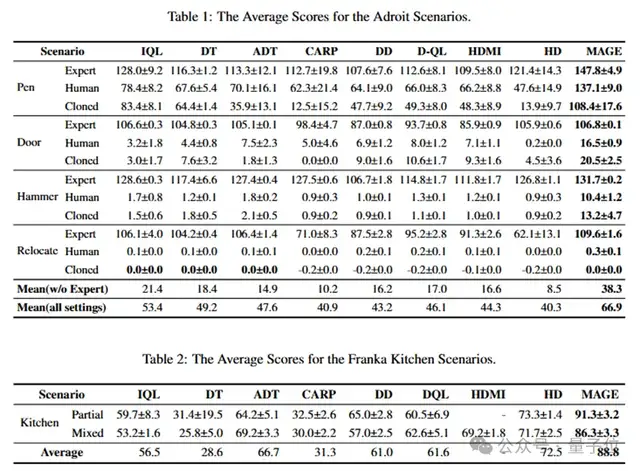
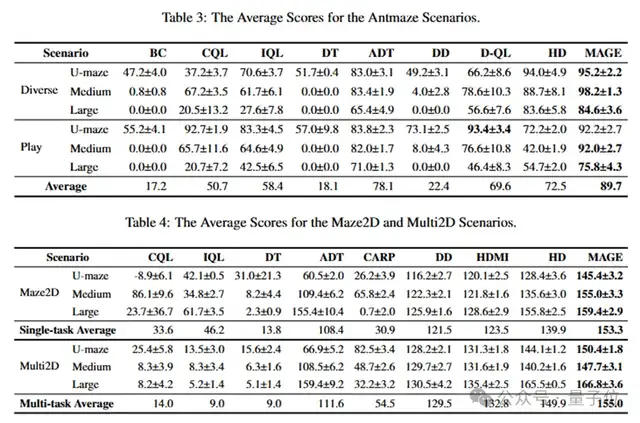
研究团队将MAGE与15种代表性基线算法进行了广泛的对比测试,涵盖了Adroit、Franka Kitchen等五个离线RL基准数据集。
在挑战性极高的高维连续控制机械臂任务中,面对极其稀疏的奖励,MAGE实现了显著的性能提升,大幅超越了所有竞争方法。在强调子目标顺序执行的任务中,MAGE凭借其对全局结构和局部细节的有效捕捉,在Franka Kitchen组合任务中以较大优势获胜。
多任务表现出色
在迷宫导航任务的所有数据集中,MAGE均取得了最佳表现,验证了它处理长序列导航任务的能力。
高效的推理速度与实际部署潜力
MAGE在保持高性能的同时,实现了卓越的计算效率。实验结果显示,其运行速度快于Hierarchical Diffuser约50倍,比Decision Diffuser快80倍,每步推理时间控制在27毫秒内,完全满足了真实机器人实时操作的需求。

MAGE成功地结合多尺度轨迹建模与条件引导技术,通过“由粗至细”的自回归框架生成连贯且可控的高回报路径。当有一天,机器人能够自主审视全局环境、制定长远规划并流畅执行时,也许真正的智能飞跃将不再遥远。
结语
https://arxiv.org/abs/2602.23770
论文链接:
https://github.com/xmu-rl-3dv/MAGE
https://github.com/xmu-rl-3dv/MAGE
实验室主页:
https://asc.xmu.edu.cn/
作者介绍:
本文第一作者来自厦门大学空间感知与计算实验室(ASC Lab)2024级硕士生林晨兴、2025级硕士生高鑫辉,通讯作者为厦门大学沈思淇副教授,并由张海鹏、李欣然(香港科技大学)、王海涛、梅松竹副研究员、刘伟权副教授(集美大学)、王程教授共同合作完成。研究团队长期聚焦于强化学习,多智能体系统以及大模型智能体。