
在长视频的三维重建中,"看不清" 并不是最让人头疼的问题。
虽然短片段拍摄效果很好,但一旦序列变长,问题就会逐渐显现出来,导致模型在处理大场景时产生累积误差。
最近,浙江大学、地平线机器人和之江实验室合作推出了一项名为Scal3R的新技术,旨在解决这一难题。
以前的研究主要集中在如何将长序列分割成小块并重新组合上。
Scal3R 则侧重于从训练阶段就开始处理超长序列的问题。通过测试时的训练方法,作者设计了一套全局上下文模块及同步机制,使模型能够更好地学习和应对大规模场景下的三维重建挑战。
运用Scal3R技术,可以实现超过一万帧几千米的大规模场景三维重建,并输出精确的相机位置信息和点云数据。以下为浙江大学紫金港校区的实际拍摄效果:

视频链接:https://mp.weixin.qq.com/s/Yi8AMQ3BxcTCLUDlzvLlcg
与Depth Anything 3(Streaming模式)进行可视化对比的结果如下所示:
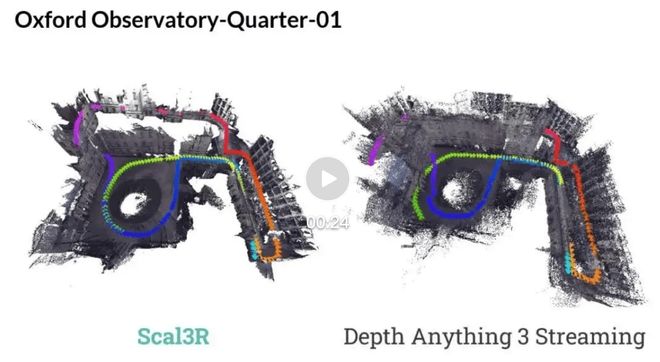
视频链接:https://mp.weixin.qq.com/s/Yi8AMQ3BxcTCLUDlzvLlcg
相关论文《Scal3R: Scalable Test-Time Training for Large-Scale 3D Reconstruction》已发表在arXiv上,代码和模型权重分别发布在GitHub和Hugging Face平台上:

- 论文链接:https://arxiv.org/abs/2604.08542
- 论文主页:https://zju3dv.github.io/scal3r/
- 代码仓库地址为:https://github.com/zju3dv/Scal3R
- 模型的获取路径是:https://huggingface.co/xbillowy/Scal3R
超大规模场景重建面临的主要挑战是什么?
近年来,VGGT这类前馈式三维基础模型已经能够直接从RGB图像中估计相机参数、深度和点云数据,并且精度相当高。
但当场景变大或序列拉长时,问题就会显现出来。
首先,处理长序列的计算成本会急剧增加;其次,在训练阶段使用短序列而在测试时需要处理大量帧数会导致模型无法准确预测长期依赖关系。
目前解决这些问题的方法主要有两种。
一种是通过压缩token来容纳更长序列。虽然这种方法可以减少计算量,但会牺牲细节和长远的依赖性。
另外一种方法是分块处理:先将序列分成多个重叠片段独立重建,再进行跨块对齐。这种方法较为实用且具有较好的扩展性,但是前提是每个局部几何预测必须足够准确。
所以问题的核心在于如何让模型在训练阶段就学会处理长序列,并保持一致的机制用于测试时的应用场景中。
Scal3R 是怎么工作的?
Scal3R 在视觉几何能力的基础上进一步发展。虽然局部几何仍然很重要,但Scal3R试图通过相同的机制来解决长序列中的问题。
作者认为要使模型在测试阶段处理长视频时表现稳定,就需要从训练阶段开始就让其接触并学习超长序列。
围绕这一思路,论文中提出了两个核心模块:全局上下文记忆(GCM)和同步机制(GCS)。
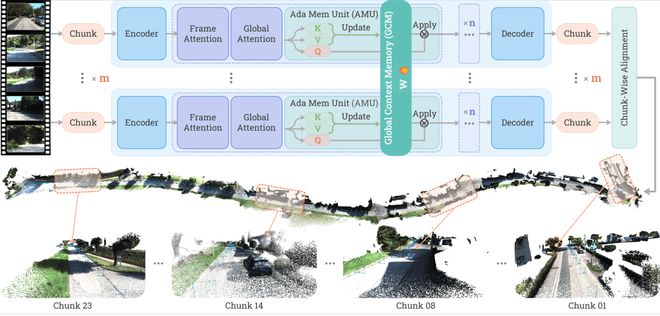
GCM 由多个自适应存储单元组成,用于捕获和维护长时间依赖关系。而GCS则负责协调不同片段之间的信息流动,确保整体的一致性。
Scal3R 不仅提升了长序列三维重建的质量,还在效率和一致性上做出了显著的改进。论文中详细评估了相机位姿估计和三维重建点云的效果,并展示了在多种场景下的优越表现。
除了技术上的突破,Scal3R 还重新定义了大规模三维重建的问题视角。
它没有简单地追求更大的骨干网络或更多的token数量,而是关注如何从训练阶段开始就让模型掌握处理超长序列的能力。
Scal3R 提供的不仅仅是一个更强大的方法,而是一种全新的思考方式。这种思路不仅可以应用于三维重建领域,还可以扩展到其他涉及大规模视频场景理解的任务中。
GCM 管逐 chunk 更新和上下文累积,GCS 负责把这些更新在不同 chunk 之间同步起来,使用 PyTorch DDP 的 all-reduce 机制,在不同的 chunk 之间同步自适应存储单元的自监督梯度。
如果你对这些问题感兴趣:如何在长时间段内实现高质量的三维重建;基础模型如何适应公里级的场景变化;测试时训练除了自然语言处理和分类任务外,在三维视觉中的应用潜力,那么Scal3R 是一份值得深入研究的文献。
关键的点是,作者并没有把 test-time training 当成测试阶段的临时补丁,而是把它变成支撑长序列训练和长序列推理对齐的一种方式;GCM/GCS 则在这种长序列机制里做更新、保留和同步。
为什么 Scal3R 的做法可以稳住长序列
长序列重建里最棘手的情形,经常不是 "看不见",而是局部都能看懂、时间跨度一长就不一定稳得住。
大尺度室外场景里的重复纹理、长距离视角变化、稀疏采样、长走廊、回环闭合 —— 每一项都在考验局部几何预测的鲁棒性。局部块必须先算得准,跨块同步和长程约束才有意义;否则局部误差会顺着整条序列一路被放大。
Scal3R 的价值就在这里。
它没有把长视频简单切开再拼回去,而是让模型在训练阶段就反复经历 "长序列 + 逐 chunk 更新 + 跨 chunk 同步" 的完整过程。等到测试时,模型遇到的行为模式和训练时是一样的。
这时 memory 的角色就清楚了:GCM 不替代局部几何预测,只是在逐 chunk 训练和推理里提供一份可更新的上下文状态,把前后 chunk 的信息接起来 —— 前提依然是局部几何得可靠。
所以 Scal3R 重要的地方不在削弱局部几何,而在把局部几何、可更新上下文、长序列训练、测试时同步这四件事放到同一个框架里。
一,长序列被拆成 chunk 来算。这把原本随序列长度平方增长的计算压力摊平了。按论文里的视角,全序列注意力的复杂度会随长度快速上升,chunk-wise 处理则把问题改写成更可控的局部计算,再通过融合扩展到整段序列。
二,不是简单分块,而是逐 chunk 更新、再做同步。很多分块方法块和块之间是割裂的,算完就算完了。Scal3R 会在每个 chunk 上算可更新模块的变化,再由 GCS 把这些更新在 chunk 之间同步起来。网络虽然按块处理,但训练和测试时都在学习怎么把局部结果放回长序列里。
三,训练时就直接面向长序列。论文里讲得比较清楚:训练阶段会直接采样连续长序列,再用不同 GPU 分组去覆盖不同的有效序列长度。TTT 在这里更像是一种手段 —— 让长序列训练可行,也让测试行为和训练行为保持一致。
这三条合起来就能解释为什么 Scal3R 不止是 "能跑长序列",而是在长序列上把局部几何质量、效率和整体一致性都稳住了。
在基准测试上的效果
论文从相机位姿和三维重建两部分做了比较完整的评估,覆盖室内外和不同尺度的场景,结果显示提升很扎实。
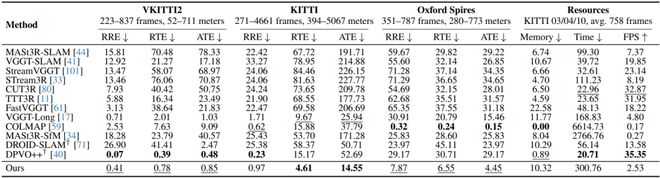
论文主表中的位姿与资源对比,覆盖 VKITTI2、KITTI Odometry 和 Oxford Spires。
相机位姿估计:表里 baseline 大致可以分成三类。SLAM / SfM 方法在条件合适时很准,比如 COLMAP 在 Oxford Spires 上很强,DPVO++ 在 VKITTI2 上误差也低;但它们要么需要内参,要么速度慢,在资源统计中,COLMAP 平均一次推理要 6614.73 秒。前馈和 streaming 方法更快,但长序列漂移压不住,FastVGGT 还会遇到显存问题。最接近的对照是 VGGT-Long:它比不少 streaming baseline 稳,但 KITTI 上 ATE / RTE / RRE 仍是 25.94 / 9.67 / 1.71,而 Scal3R 是 14.55 / 4.61 / 0.97;Oxford Spires 上也从 15.46 m 降到 4.45 m。
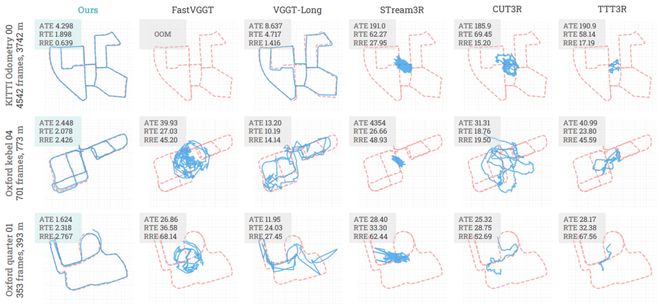
大规模多场景轨迹对比。蓝线是预测轨迹,红色虚线是真值轨迹。
轨迹图更直观:KITTI 00 上 Scal3R 的 ATE 是 4.298,VGGT-Long 是 8.637;Oxford Keble 04 和 Oxford Quarter 01 上 ATE 分别是 2.448 和 1.624。蓝线基本能贴住真值轨迹,其他方法更容易漂成局部团块。
再看三维重建精度
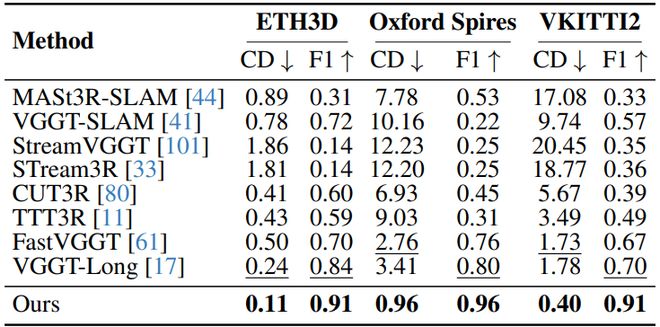
三维重建点云评测,指标为 Chamfer Distance(越低越好)和 F1(越高越好)
这张表更直接。Scal3R 在 ETH3D、Oxford Spires、VKITTI2 三个数据集上六个指标都是最优:ETH3D 是 0.11 / 0.91,Oxford Spires 是 0.96 / 0.96,VKITTI2 是 0.40 / 0.91。对比最强的 VGGT-Long,ETH3D 从 0.24 / 0.84 提到 0.11 / 0.91;Oxford Spires 从 3.41 / 0.80 提到 0.96 / 0.96;VKITTI2 则从 1.78 / 0.70 提到 0.40 / 0.91。这里的差距不只是局部几何更准,也和前面的位姿稳定性有关:轨迹一旦漂了,后面拼出来的点云通常也会散。

重建对比图,展示 Oxford Keble 04 和 ETH3D Terrains 等场景。
定性图也对得上表格。像 Oxford Keble 04 这种大尺度校园场景,Scal3R 的建筑轮廓和庭院结构更完整;ETH3D Terrains 红框里的墙面和门框边界也更规整。FastVGGT、VGGT-Long、TTT3R 在不同场景里会出现局部破碎、漂散或者结构发糊,原因往往不是某一帧深度错了,而是长序列位姿和局部几何没有一起稳住。
精度之外再看下资源和扩展性。Scal3R 可以在单张 RTX 4090 上完成推理,它不是吞吐最快的方案,但在精度、长序列稳定性和可扩展性之间做了一个比较实用的取舍。补充材料里还分析了随序列变长的趋势:从 150 帧涨到 990 帧,整体运行时间基本呈线性增长,相对位姿误差则稳在 0.07 到 0.08 m,说明它不是只适配某个固定长度。
结语
Scal3R 最值得留意的地方,不只是又做出来一个更强的长序列 3D 重建方法,而是它把问题的重点重新摆过一遍。
它没有把 "大规模 3D 重建" 简单理解成更大的 backbone、更多 token 或者更激进的压缩,而是问了一个更靠前的问题:模型要想在测试时吞下长序列,训练时是不是也得先真正学过长序列?
顺着这个视角往下看,Scal3R 提出的其实不只是一个记忆模块,更像是一种把局部几何、可更新上下文、长序列训练和测试时同步串起来的思路。对 3D 重建如此,搬到更广泛的长视频场景理解任务上,可能也差不多。
如果你正在关心这几件事 —— 长视频怎么做高质量 3D 重建;foundation model 怎么扩展到公里级场景;test-time training 除了语言和分类任务,还能怎么真正落到 3D 视觉里 —— Scal3R 值得花点时间细读。

视频链接:https://mp.weixin.qq.com/s/Yi8AMQ3BxcTCLUDlzvLlcg