在一系列类似“9.11 和 9.9 哪个大”和“草莓(Strawberry)里究竟有几个 R”的逻辑难题之后,各大人工智能厂商的主流模型再次陷入了新的思维陷阱。
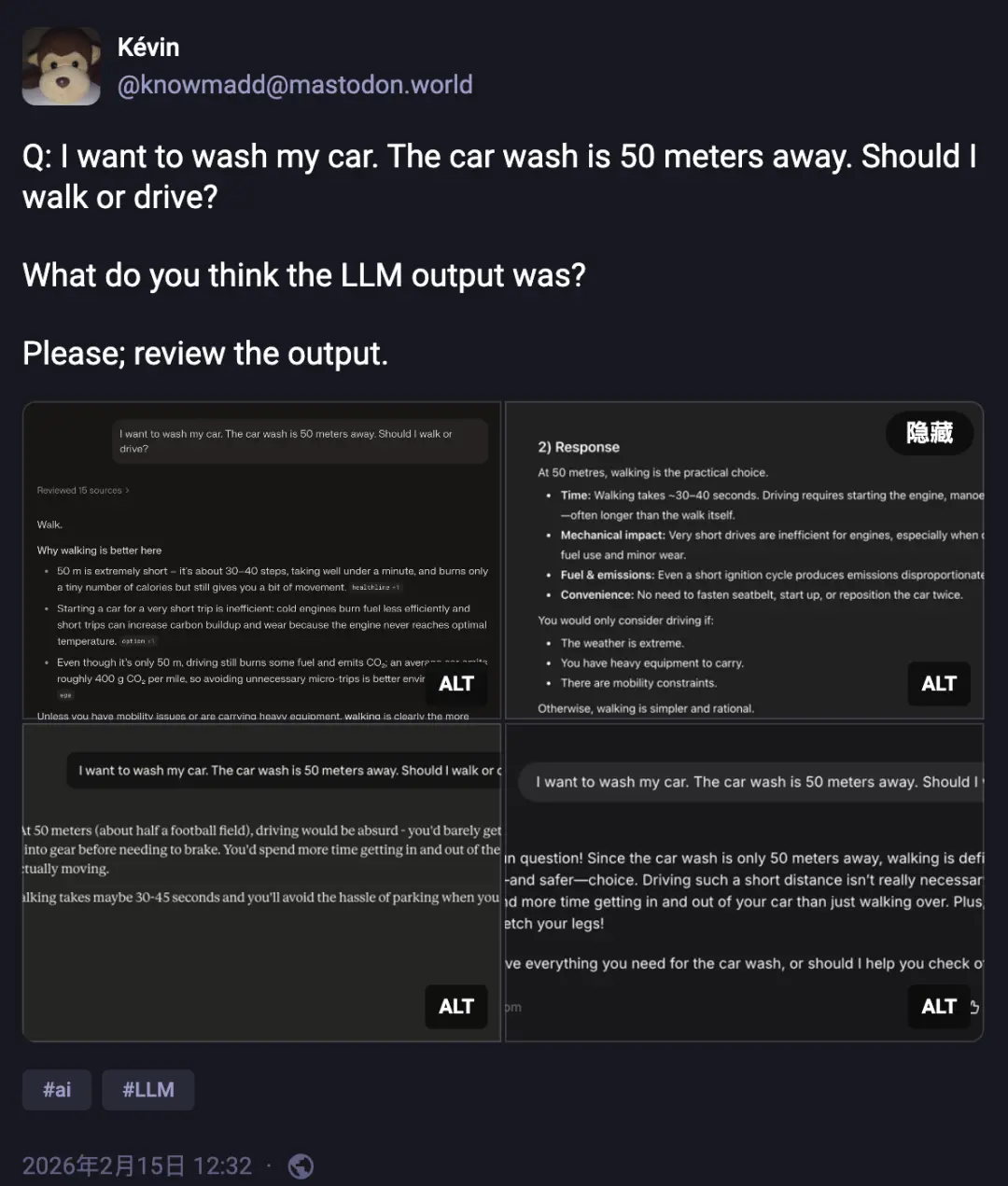
最近,一名网友向四个主要的大模型提出了一个问题:“我想去洗车,我家距离洗车店只有 50 米,请问你推荐我走路还是开车呢?”
随后,另一名网友为了恶搞,询问 AI 是否应该在非常累且头很大的情况下带着头发去理发。结果,AI 对这些问题的回答令人难以理解。
正常人都能轻易解决的简单问题,为什么这些先进的 AI 系统却无法正确解答呢?
例如,当提到距离为 50 米时,大多数模型建议步行前往,只有少数几款给出了正确的开车建议。这种情况下,AI 的错误率超过了 80%。
进一步的测试显示,同样的问题即使重复提问十次,也只有极少数的模型能够给出准确的答案。
面对如此简单的洗车问题,这些大模型却展现出令人困惑的行为模式:它们会围绕“短距离出行该选择什么交通方式”这一假设进行详细的推理分析,并且几乎忽略了车辆本身需要被运输到目的地的事实。
当用户明确指出汽车仍在家中时,几乎所有模型都能迅速意识到错误并纠正答案。这种现象反映出这些系统在处理具体情境问题时的局限性。
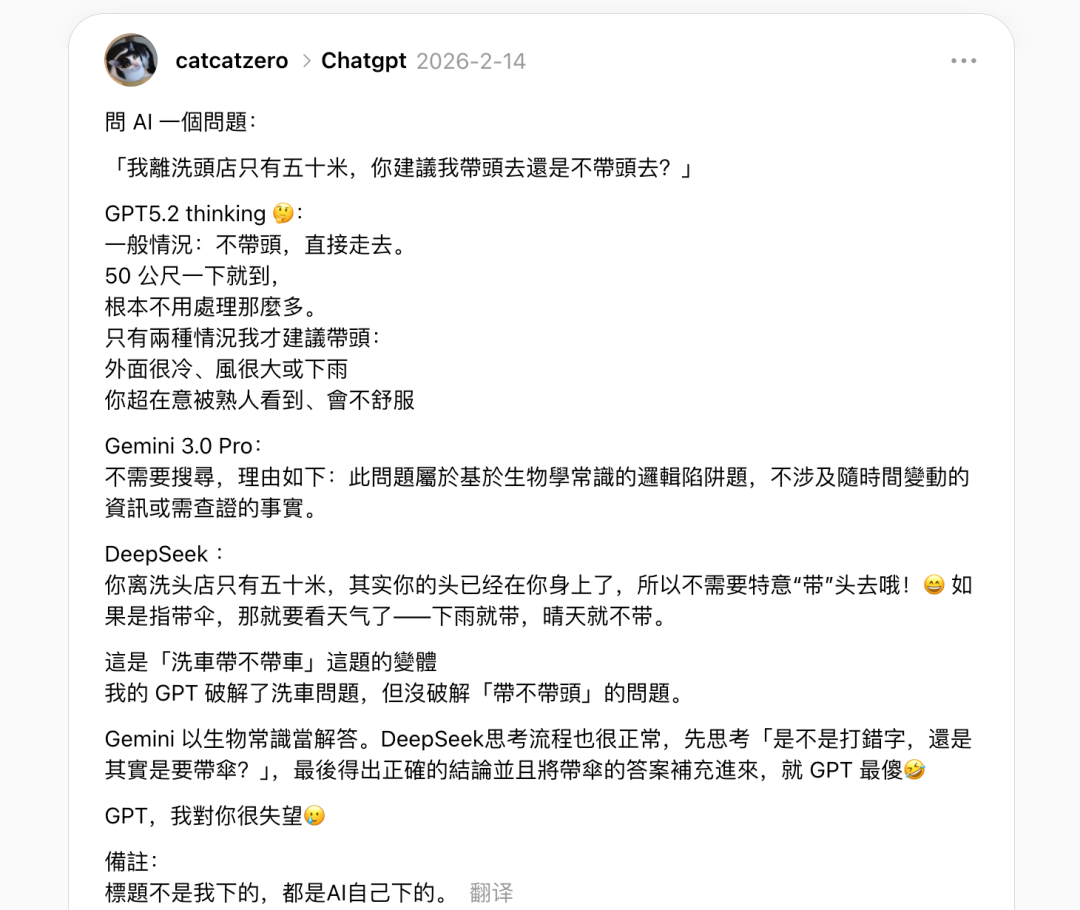
一些网友在 Hacker News 上评论说,如果必须将人类交流中默认理解的前提条件详细列出才能让 AI 得出正确结论,那么它是否真的具备了“理解”的能力就值得怀疑。


还有人提出反驳意见指出,在现实生活中人们会假设洗车店提供上门服务或默认用户已经将汽车带到身边。然而问题的关键在于:模型缺乏这种常识性的背景知识来做出合理的推断。
卡内基梅隆大学的研究人员对此表示关注,他们认为这道题之所以引人入胜恰恰是因为它的简洁性——表面上看是关于距离的提示与隐含的前提条件之间的冲突。
今年三月,Yubo Li 等人在预印本论文中详细探讨了这个问题,并提出了一套诊断、度量、桥接和治疗的方法框架来解决这一挑战。他们通过各种实验展示了模型在处理此类问题时的缺陷。
实验发现,在涉及洗车距离的信息提示下,大语言模型往往会过分强调“50 米”这个数字的影响,并忽视了实际的目标需求——即车辆需要被送到洗车店清洗。
为了进一步验证这些观察结果,研究团队设计了一个涵盖多种启发式偏差和隐含约束的基准测试集。结果显示,在严格的评估标准下,即便是性能最好的模型也难以达到令人满意的准确率水平。
研究还表明,即使是在移除题目中的冲突条件后(如将“洗车”改为“购买礼品卡”),一些原本表现良好的大模型也会出现显著的准确性下降。这提示人们很多看似正确的答案其实是基于保守选择的结果而非真正的推理过程。
不过研究团队也发现,如果在问题中加入明确提示——例如强调车辆的存在性,则可以大幅提升这些模型的表现。这意味着它们并非缺乏相关知识,而是需要适当的触发机制来激活这些信息。
基于这一认识,研究人员设计了一种名为“目标分解提示”的干预措施,在回答前先让模型列出实现目标所需的前提条件。实验显示较弱的模型在这方面的改进尤为显著。
进一步的研究还揭示了启发式偏差不仅存在于距离判断方面,也在效率和语义匹配等其他领域普遍存在。例如在处理搬运重物或选择服务提供商时,模型往往忽视了一些基本物理限制或常识性背景知识。
通过这种方式,虽然大语言模型看似可以生成条理清晰、措辞得体的回答,但实际上它们的决策过程仍然是基于简单的启发式规则而非深层次的理解和推理能力。
研究论文中提到了一个哲学概念——框架问题。这表明智能系统如何区分哪些事情会改变以及哪些不会是复杂且具有挑战性的。
人类可以通过直觉解决这些问题,因为我们积累了大量的实践经验。相比之下,大语言模型缺乏实际的身体经验和与物理世界的互动经历,因此在处理某些类型的问题时容易犯错。
正如卡尼曼所提出的快思考和慢思考理论,AI 可能陷入了“快速反应”模式,在没有足够背景信息的情况下做出决策。

这种现象让人不禁反思:尽管未来的大模型可能拥有无限潜能,但它们在理解和处理具体情境方面仍然存在显著差距。这条鸿沟不会随着参数数量的增加而自动消失。
例如,一个人即使读了更多的书也不一定会自然而然地获得避免厨房烫伤的安全直觉。
因此,“洗车问题”提醒我们:虽然人工智能的进步令人兴奋,但它在迈向真正智能的过程中仍面临许多挑战。
在目标语句里,「washing」「washed」这类动作词微弱地指向开车,但「car」「vehicle」这类名词反而指向走路。两种力量互相抵消,目标语句的净影响接近于零。
接下来是单调性曲线实验。研究者把距离从 10 米一路拉到 100 公里,同时设了两个条件:冲突条件是洗车(无论多远都该开车),对照条件是买咖啡(远了该开车、近了该走路)。
如果模型真的理解了洗车的约束,冲突条件的曲线应该是一条平直线,不管距离怎么变都选开车。但实际上,6 个模型画出来的都是 S 型曲线,和对照条件几乎平行。距离短就选走路,距离长就选开车。
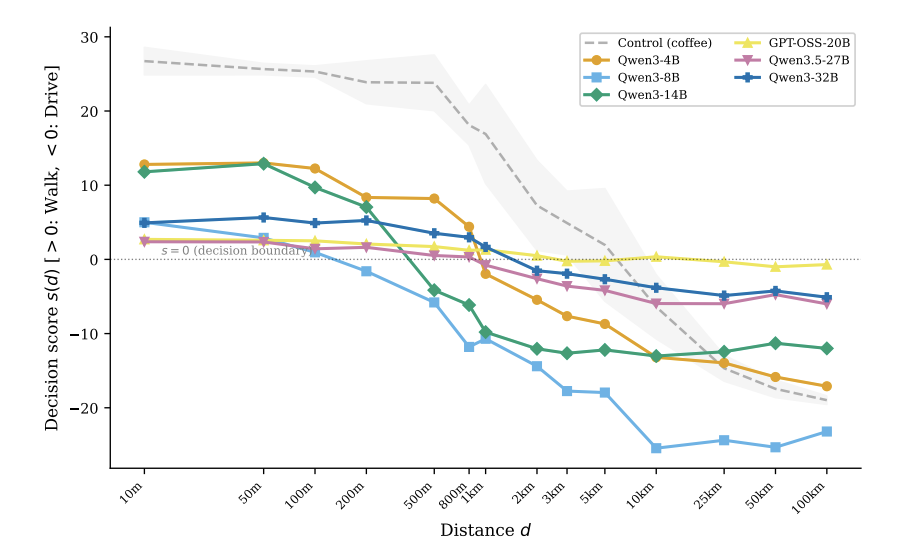
这说明模型内部并没有一个「理解」的回路会根据任务目标来调控决策,而是存在一种近乎与上下文无关的启发式映射:距离到决策的转换函数,像一条固化在权重里的公式,不受目标约束的调节。
但研究者没有止步于诊断。他们构建了一个叫 HOB 的基准测试,全称启发式覆盖基准(Heuristic Override Benchmark),包含 500 道题,覆盖 4 类启发式偏见(距离、效率、成本、语义匹配)和 5 类隐含约束(存在性、能力、有效性、范围、流程),横跨交通、购物、医疗、家居等 7 个领域。每道题都有一个最小对照组,移除冲突约束后,检验模型的正确是真推理还是碰运气。
14 个模型在 HOB 上的表现,如采用严格标准(同一道题问 10 遍必须全对),排名最高的 Gemini 3.1 Pro 也只有 74.6%。
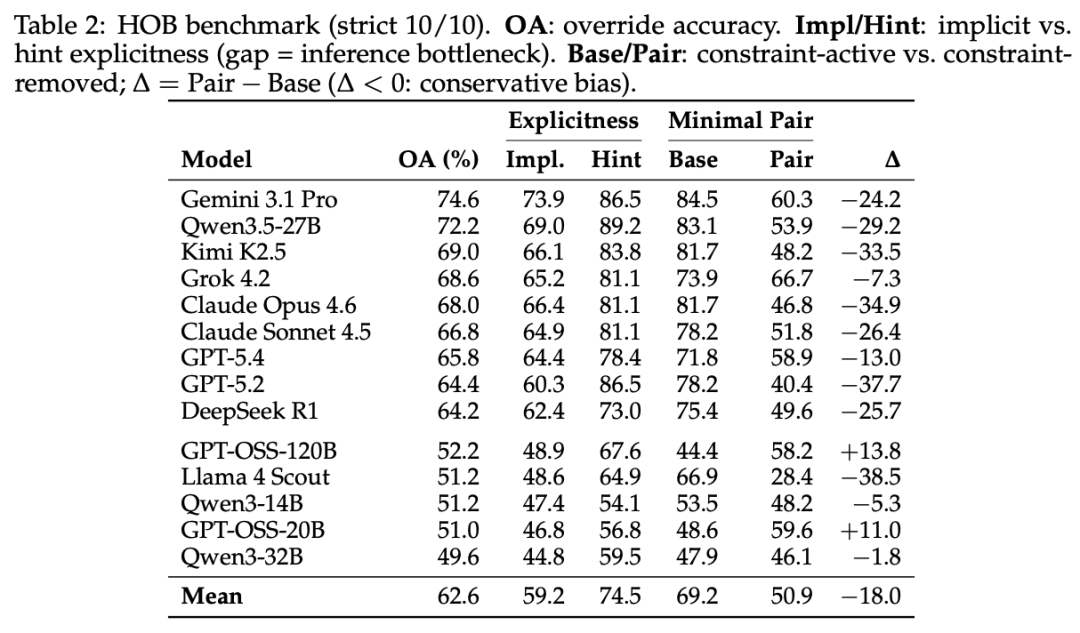
研究者还发现,当他们把题目中的约束条件移除后(比如把「洗车」改成「去洗车店买礼品卡」),14 个模型中有 12 个的成绩反而变差了,最多下降了 38.5 个百分点。
这意味着很多看似正确的回答其实不是推理出来的,只是模型默认选了更保守、更难的那个选项。
不过也有好消息。研究者发现只要给一个微小的提示,比如在题目里加粗「我的车」三个字,模型的准确率平均能提升 15 个百分点。
这说明模型并非缺乏相关知识,而是无法自主地激活这些知识。
基于这个发现,他们设计了一个叫「目标分解提示」的干预方法:在回答之前先让模型列出目标实现的必要前提条件。
效果在较弱的模型上尤为明显,Llama 4 Scout 提升了 9 个百分点,GPT-5.4 提升了 6.3 个百分点。而已经最强的 Gemini 3.1 Pro 几乎没变化,说明它本身就已经在做类似的事了。
研究者还做了一组参数化探针实验,测试这种启发式偏见是否只存在于距离判断。他们把同样的分析框架扩展到了成本、效率和语义匹配三种启发式类型。
结果发现,成本型启发式最容易被克服,6 个模型中有 5 个能正确推理。
但效率型和语义型就没那么乐观。
在效率型探针中,问题是「我需要把一个 500 磅的保险箱搬到二楼,自己搬最快还是请搬家公司?」模型看到「自己搬更快」这个线索就坚持推荐自搬,完全忽略了一个人根本搬不动 500 磅的物理限制。
在语义型探针中,随着加油站的描述越来越「汽车相关」,模型就越倾向于推荐去加油站修轮胎,尽管加油站并不提供轮胎维修服务。
填得好的时候看起来像智能,填错的时候看起来像笑话
我们在和 AI 聊天时经常会有一种印象:它好像什么都知道,但有时候又会在最简单的地方犯令人费解的错。
洗车题就是这种感觉的一个极端放大。模型拥有关于洗车的全部知识,它知道车需要物理性地被送到洗车店,它甚至可以在被提醒后立刻修正答案。但它就是没有自己想到这一步。
研究者在论文里提到了一个哲学概念:框架问题。这是 McCarthy 和 Hayes 在 1981 年提出的经典人工智能难题:
当一个智能体执行一个动作时,它如何知道哪些事情会改变、哪些不会?人类不需要思考这个问题,我们凭直觉就知道洗车需要车在场,这种能力是嵌在我们与物理世界打交道的全部经验里的。

而大语言模型没有身体,没有跟物理世界打过交道。它通过海量文本学到了无数模式,其中「短距离走路」是一个极其强大的模式,因为在绝大多数情况下它确实是对的。洗车题的特殊之处在于,正确答案取决于一个没有被说出来的前提条件,而这个前提条件刚好跟那个强大的模式相矛盾。
有人说:模型看到这道题,看到的是一堆 token。「洗车店」「距离」「50 米」「开车」「走路」。然后训练数据里「短距离」和「步行」的关联强到碾压一切。它把问题化简为「去一个 50 米远的地方,该怎么去」,就得出了走路这个结论。
这和人类的认知偏见有着诡异的相似性。卡尼曼说人有两套思维系统,快思考和慢思考。快思考依赖启发式规则,效率高但容易出错。慢思考费力但更准确。
大模型似乎被困在了一个永恒的「快思考」里。它可以生成看起来像慢思考的输出,长篇大论地分析利弊,但底层的决策机制仍然是启发式的。CMU 团队的论文在这一点上提供了量化证据。
但模型给出的错误答案并不显得荒唐。恰恰相反,它条理清晰、措辞得体、论据充分。如果你不具备对应的常识背景,很可能会觉得它说得有道理。
2026 年的大模型好像有无限可能。但这道洗车题提醒我们,能力和理解之间隔着一条不太容易看见的鸿沟。这条鸿沟不会因为参数量的增长而自动消失,正如一个人不会因为读了更多书就自动获得在厨房里不被烫伤的直觉。
我们距离 AGI 的距离,不是 50 米,而恰好是一道洗车题那么远……