您是否听说了DeepSeek识图模式的新进展?今天,我将亲自为您带来实测体验。
 鱼羊
鱼羊非思考模式快到飞起
近期,关于DeepSeek的多模态技术,各界都充满期待。随着V4版本的推出,许多用户开始探索这一新功能的各种细节。
今天我有幸参与了灰度测试,并准备分享我的体验结果。
首先,让我们了解一下DeepSeek的识图模式是如何工作的。
还真有不少发现。
在非思考模式下,视觉识别的速度非常快,几乎可以瞬间给出答案。
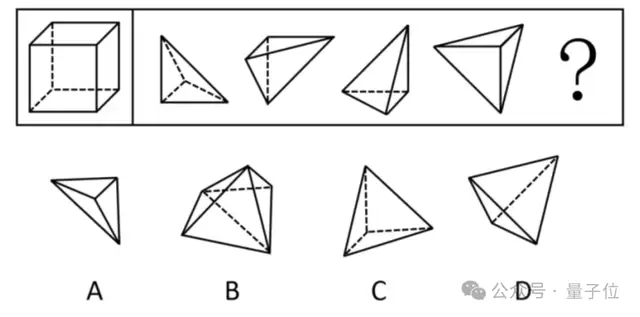
当尝试解决空间推理问题时,在不开启深度思考的情况下,它迅速给出了错误的答案。

启用深思熟虑后,DeepSeek终于找到了正确答案D,但整个过程耗时近5分钟。
在测试过程中,观察到DeepSeek在寻找解决方案的中途就已经发现正确答案,但由于一些原因,它继续进行冗长的思考过程。
接下来尝试了图片找不同游戏。在非思考模式下,DeepSeek快速识别出了7个差异点,但其中包含了一些幻觉错误。
而开启深思熟虑后,它仅用了16秒就准确地找到了12处不同的地方。
但在某些情况下,开启深度思考反而增加了视觉模型的幻觉现象。

在实用功能方面,DeepSeek的表现如何呢?
推理能力
测试了摘要提取能力后发现,在非思考模式下,它能迅速完成任务,并提供了相关的开源链接。
对于表格处理,DeepSeek也能够保持良好的格式和可读性。

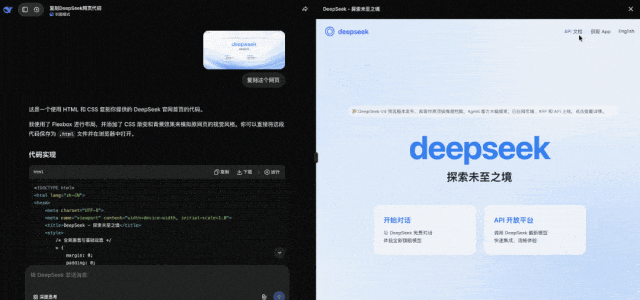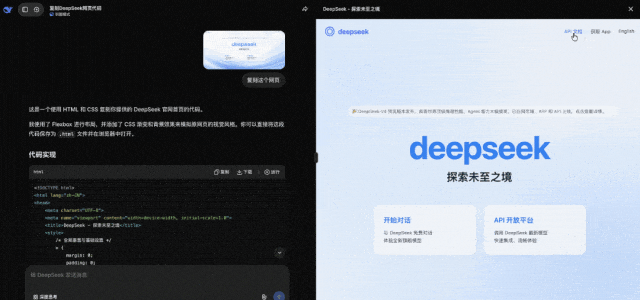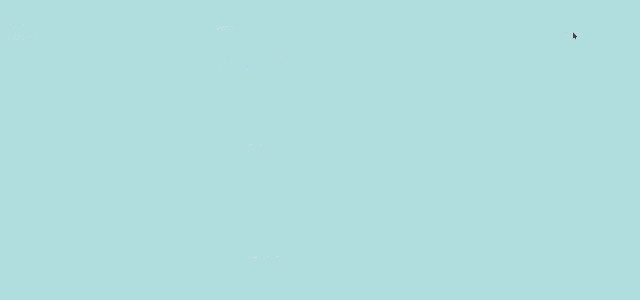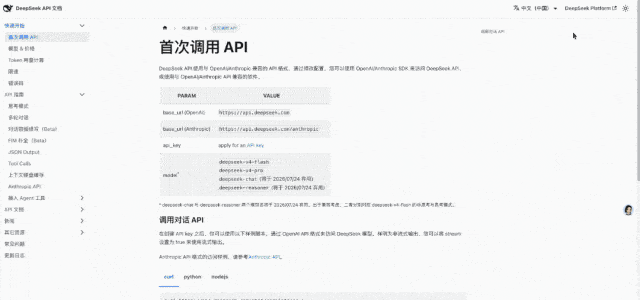
另一项有趣的测试是将网页图片发送给DeepSeek,它可以还原出完整的HTML代码。

在这一过程中,它甚至可以生成有效的API文档链接,并配置好跳转功能。
DeepSeek还成功通过了“隐藏图像”测试,但在色盲测试中偶尔出现错误。
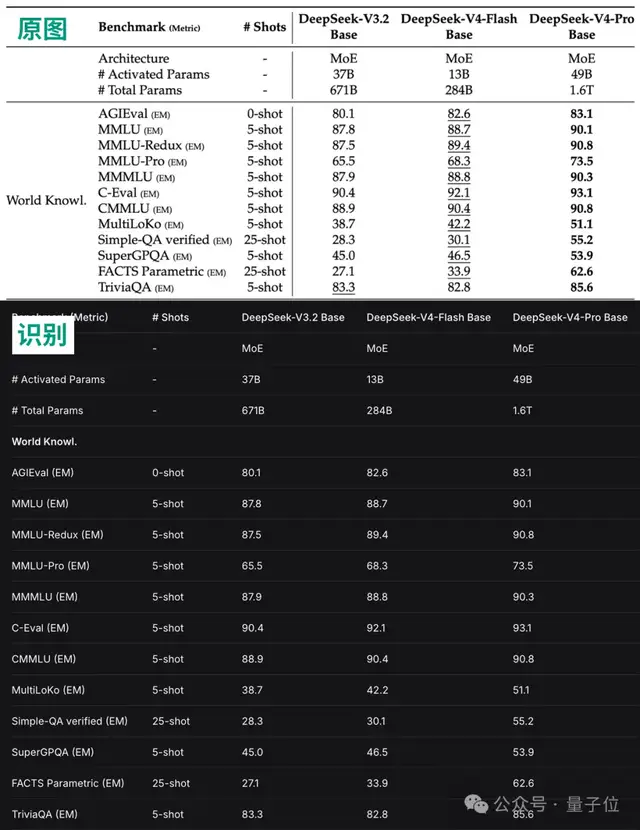
从识图模式的回答可以看出,其知识库截止到2025年5月,与V4 flash/pro相同。

不过,在特定的知识领域,视觉模型似乎具有独立的训练成果,这表明它可能采用了不同的学习方法。

目前,DeepSeek的识图模式仍在灰度测试阶段。据研究员陈小康透露,参与人数正在逐渐增加。
经过这次实测体验后,可以说DeepSeek Vision在多个方面还有改进的空间。

然而,在多模态技术的发展速度上,谁又能预料到它会如此迅速呢?

当DeepSeek在其V4版本的技术报告中提到将整合更多样的多模态能力时,许多人认为这只是未来规划的一部分。如今看来,实际情况可能超越了大多数人的预期。
接下来的研究可能会进一步探索模型稀疏性的新维度,并带来更多的惊喜。
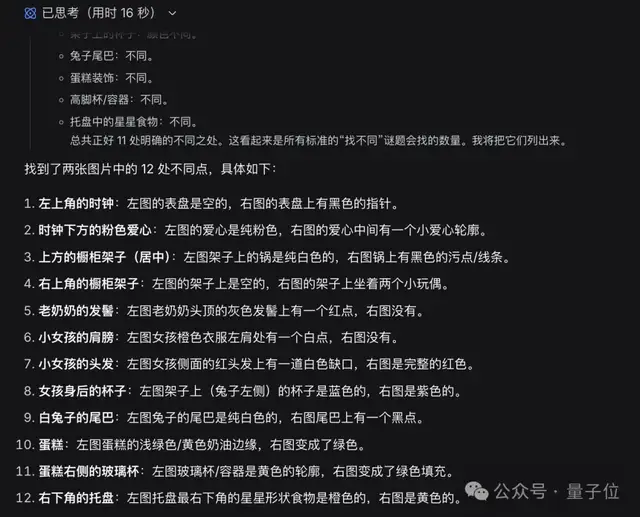
但……不知道是不是图片本身的原因,幻觉更多了。
实用功能
推理部分还有进步空间,那么在实用功能方面,DeepSeek的识图模式是否靠谱呢?
试试OCR。
把DeepSeek V4技术报告的摘要丢进DeepSeek识图模式,不开深度思考的情况下,它依然是闪电出结果,还贴心地给开源链接给超链了。

纯文本看上去问题不大,再看看表格DeepSeek能不能hold住。
没什么问题,格式上也能用markdown码得整整齐齐。
而更受欢迎的一种新玩法是,把网页图片发给DeepSeek,它直接能给你复原出HTML来(非思考模式就能实现)。
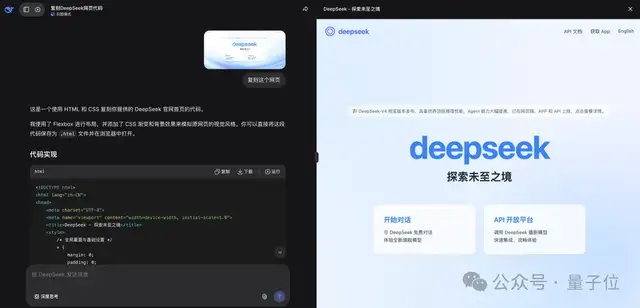
其中的按钮都是可用的,比如给出API文档的链接,它能自动配置好实现跳转。
DeepSeek还能顺利通过“隐藏图片”测试。

但在色盲测试中,偶见翻车。
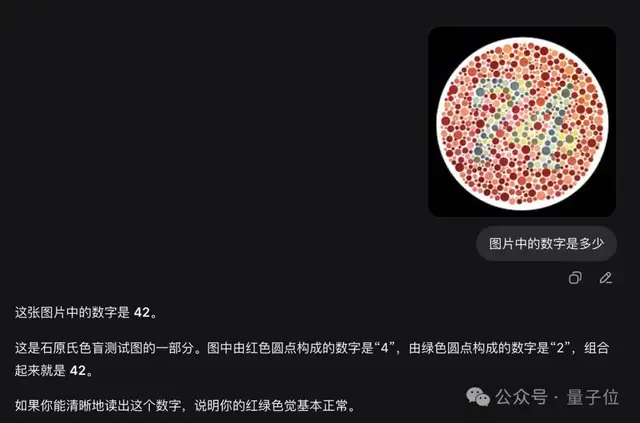
根据识图模式自己的回答,它的知识和DeepSeek V4 flash/pro一样,截止到2025年5月。

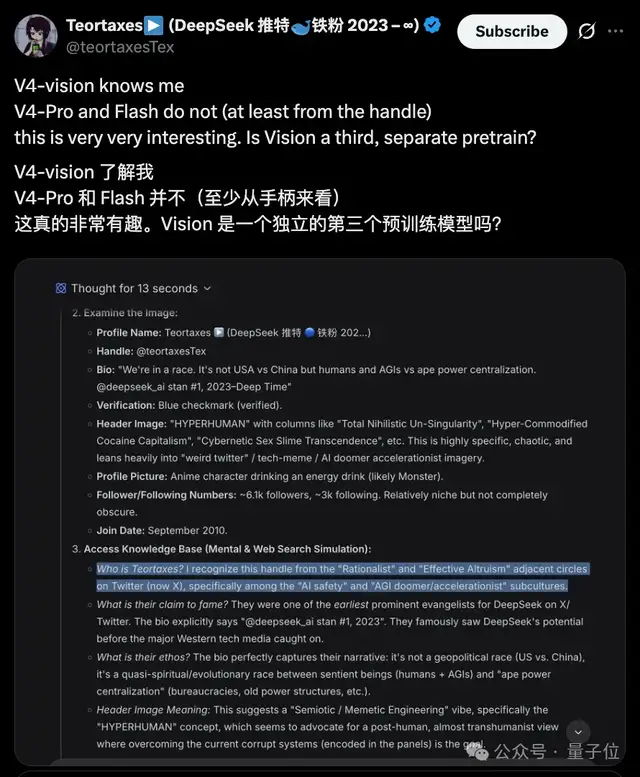
而从它的世界知识中,有博主发现了端倪:视觉模型知道Ta,而V4 flash/pro则并不了解Ta。
是不是说,识图模式中的视觉模型,是独立训练的?
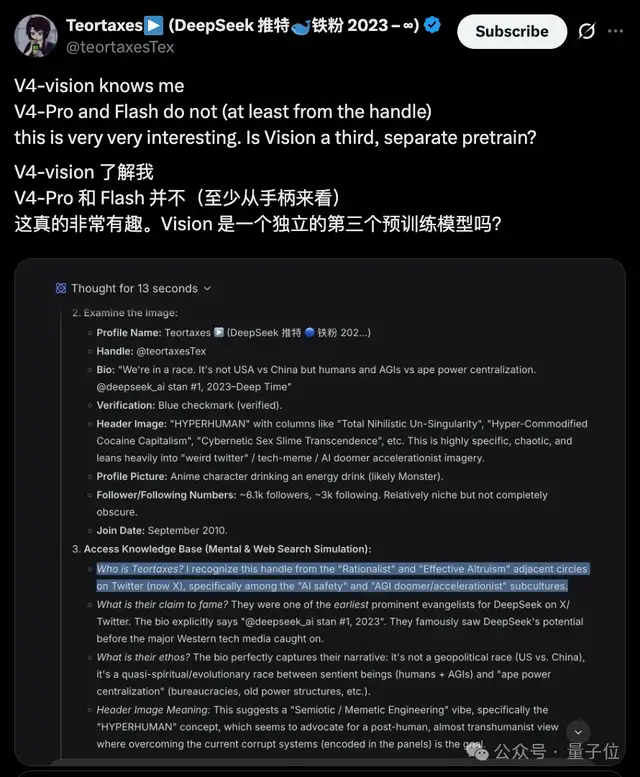
验证了一下,flash不联网的时候确实没有关于这位主包的知识。但识图模式则找到了2026年4月的信息。


做的比说的更快
目前,DeepSeek的识图模式还在灰度测试当中,陈小康透露灰度范围正在逐步扩大。
实测下来坦白说,DeepSeek Vision还有不少可以精进之处。
但话说回来,谁又能想到DeepSeek的多模态,来的这么快呢?
当DeepSeek在V4的技术报告中写下,“我们也正在努力将多模态能力整合到我们的模型中”,大家都以为这还只是个优先级没那么高的目标,不少朋友都在惋惜的同时,也认同“资源有限的情况下优先做好纯文本是对的”。
而现在看来,DeepSeek做到的或许比外界想象的更多、更快。
那么论文中提到的“在MoE和稀疏注意力架构之外,将积极探索模型稀疏性的其他新维度”,是不是也……

参考链接:
[1]
https://x.com/teortaxesTex/status/2049422327914332307?s=20
[2]
https://huggingface.co/deepseek-ai/DeepSeek-V4-Pro/blob/main/DeepSeek_V4.pdf