
新智元报道
AI编程模型在SWE-bench上的表现十分出色,但仅限于处理小型仓库的简单修补工作。BeyondSWE则提出了一种新的评估方法,旨在测试AI模型在跨仓库检索、领域知识理解、依赖关系升级和从零构建系统等方面的能力,结果显示顶尖模型的通过率骤降至45%以下,揭示了它们在实际工程思维方面的不足。
近两年来,SWE-bench几乎是衡量Code Agent性能的唯一标准。
从最初的解决率不到30%,到如今前沿模型如Gemini 3 Pro和GPT-5.2突破80%,社区似乎达成了共识:AI正在迅速逼近人类程序员的水平。
但如果重新审视这份测试题,其中的一些数据令人担忧:SWE-bench Verified仅涉及12个仓库,每道题平均只需修改1.3个文件和11.6行代码,答案均可在仓库内部找到。即使在后来的SWE-bench Pro和SWE-bench Live版本中,尽管扩展了仓库数量和修改规模,但在知识来源方面依然局限于单一仓库。
这意味着什么?
当前的基准测试对Code Agent的考察,更像是让学生在开卷考试中完成填空题——答案就在手边,只需定位和填写。然而,真正的软件工程远不止于此。
最近,OpenAI宣布不再使用SWE-bench Verified作为内部评测标准,直言其已无法区分前沿模型的能力差异。当出题者都不再信任自己的试卷时,是时候更换新的评估标准了。
判断一个Code Agent是否真正具备写代码的能力,可以从两个维度来考虑:
解决范围:需要修改多大的代码范围?是修改一个函数,还是改造整个仓库?
知识来源:需要从哪里获取信息?仅限于仓库内部,还是需要外部知识?
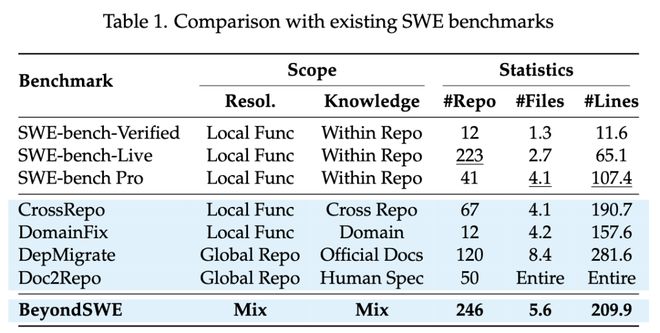
将这两项标准应用于现有的基准测试,差距一目了然——所有SWE-bench变体都集中在局部函数级别的解决范围和仓库内部的知识来源。然而,真实软件工程中最常见且棘手的问题往往是测试的盲区。
中国人民大学高瓴人工智能学院提出了BeyondSWE,首次在上述两个维度上实现突破,通过四类任务系统地覆盖了真实软件工程的多个领域。

项目主页:https://aweai-team.github.io/BeyondSWE/
论文链接:http://arxiv.org/abs/2603.03194
代码链接:https://github.com/AweAI-Team/BeyondSWE
Scaffold链接:https://github.com/AweAI-Team/AweAgent
Leadboarder链接:https://aweai-team.github.io/BeyondSWE_leaderboard/
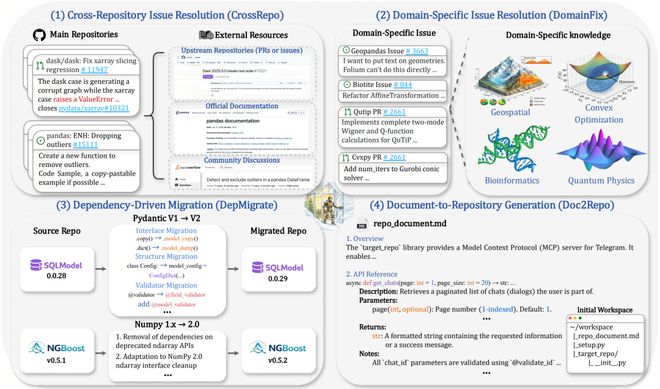
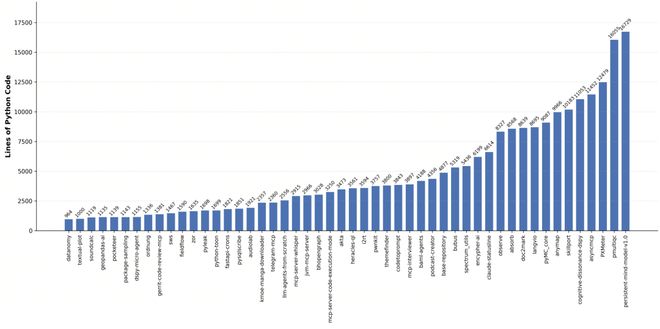
CrossRepo:答案不在这个仓库内(200条)
实际开发过程中,大量Bug的根源或修复方法并不在当前仓库中——开发人员往往需要查阅上游仓库的issue、Stack Overflow的讨论帖,甚至阅读另一个项目的源码才能定位问题。
BeyondSWE从3000个包含外部链接的GitHub PR中层层筛选,最终得到200条高质量样例,这些样例来自67个仓库,平均每个包含1.3个外部链接。
尽管修复所需的关键信息存在于外部,但测试中Agent仍然只在单一仓库中修改代码。这考察的不是「多仓库协同开发」的能力,而是对开源生态的广泛认知——这种认知既可以来自模型自身对生态的深度理解,也可以通过搜索外部资源来获取。
DomainFix:代码之外的知识壁垒(72条)
让一个后端工程师去修复量子计算库的Bug,但从未学过量子力学——这就是当前Code Agent在处理领域专业任务时面临的困境。
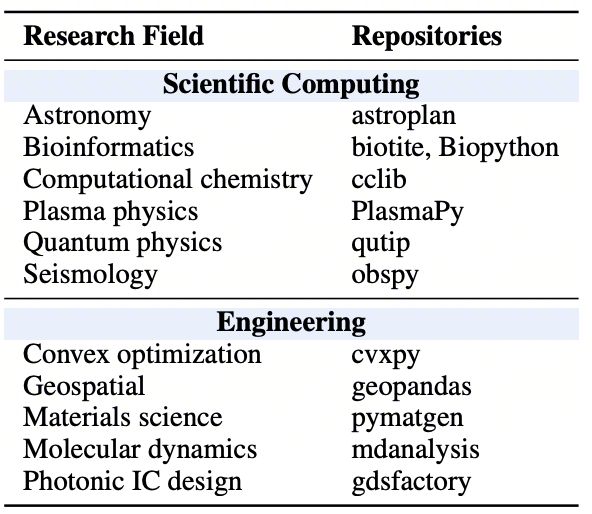
该任务由来自11个学科方向的领域专家合作构建,涵盖量子物理(QuTiP)、生物信息学(Biotite)、凸优化(cvxpy)、天文学(astroplan)、等离子体物理(PlasmaPy)等高难度领域。
每道题经过三位领域专家独立审核,只有同时满足环境正确性、领域知识必要性和解法非平凡性的样例才能入选。Bug的正确修复不仅需要读懂代码,更需要理解背后的物理公式、数学概念或生物学原理——写对了语法,算错了物理,照样得分零分。
DepMigrate:整个仓库的系统性改造(178条)
NumPy 1.x升级到2.x,或依赖关系发生变化——这些挑战在实际开发中极为常见。
BeyondSWE从3000个包含外部链接的GitHub PR中层层筛选,最终得到200条高质量样例,这些样例来自67个仓库,平均每个包含1.3个外部链接。
尽管修复所需的关键信息存在于外部,但测试中Agent仍然只在单一仓库中修改代码。这考察的不是「多仓库协同开发」的能力,而是对开源生态的广泛认知——这种认知既可以来自模型自身对生态的深度理解,也可以通过搜索外部资源来获取。
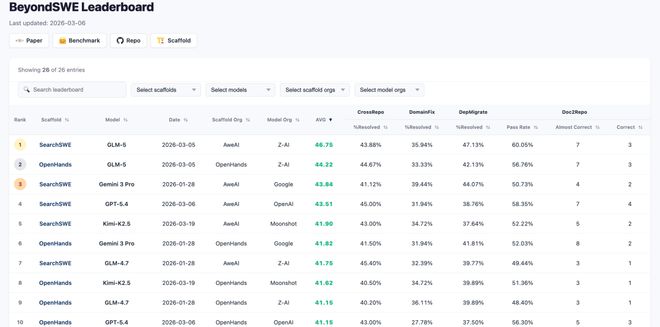
SearchSWE:联网搜索是解决方案吗?
一个自然的疑问是:如果Agent内部知识不足,赋予它联网搜索的能力,情况会有所改善吗?
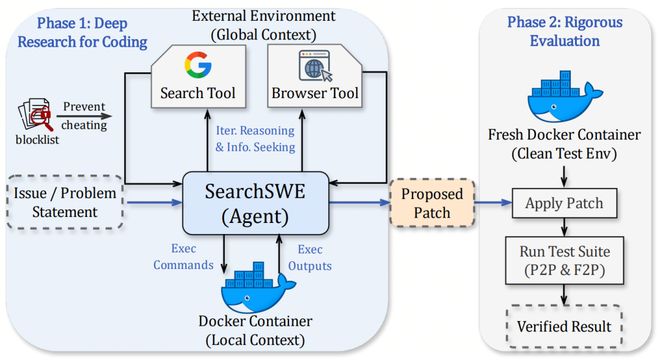
同期提出SearchSWE框架来系统研究这个问题。
SearchSWE在OpenHands基础上为Agent引入了两个工具:SearchTool(搜索引擎查询)和BrowserTool(网页内容浏览与理解)。Agent可以在编码过程中自主决定何时跳出本地环境,去查阅文档、翻阅论坛或检索领域知识——就像真实开发者随手打开浏览器一样。
为防止Agent直接搜到目标仓库的现成答案,SearchSWE设计了双重拦截机制:在搜索结果侧过滤所有指向目标仓库的URL,在执行命令侧拦截任何直接访问目标仓库的操作。Docker环境中也已清除目标commit之后的全部git历史。Agent别无捷径,只能靠真正的推理来解题。
搜索确实有用,但如何与编码有效融合才是真正的难题。
实验给出了一个微妙而真实的答案——既不是「联网万能」,也不是「搜索无用」。
实验结果
近乎腰斩
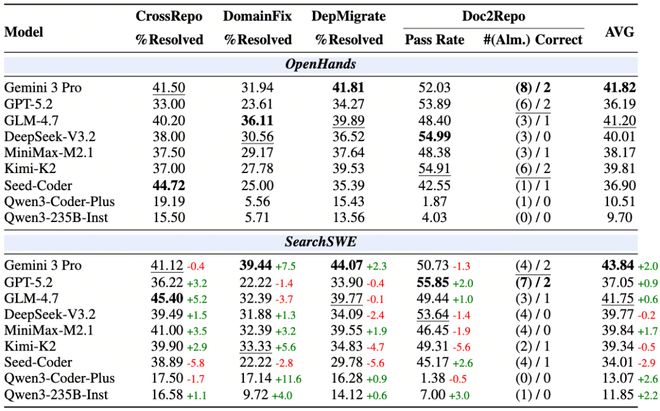
9个模型中,6个加入搜索后整体提升,3个反而下降。搜索对知识密集型任务帮助最为直接:Gemini 3 Pro在DomainFix提升+7.5%,外部文档确实弥补了内部知识的不足。但最反直觉的发现在于搜索频率与效果的关系:
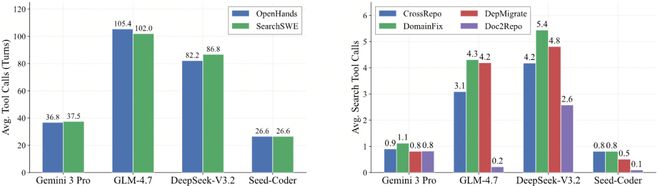
Gemini 3 Pro平均每任务只调用搜索0.8-1.1次,却拿下了最好的整体增益(+2.0%);DeepSeek-V3.2平均搜索4.2-5.4次,整体反而微降0.2%。搜索的价值不在于频率,而在于「知道什么时候该搜,搜到了怎么用」的精准判断。
三类失败模式:为什么搜索+编码这么难融合
对Agent搜索行为的深入追踪,揭示了三类根本性的障碍:
信息景观的鸿沟。搜索引擎经过几十年优化,擅长检索人类可读的高层文档。但代码任务所需的关键知识,往往深埋在源文件、commit diff和issue评论的只言片语中——搜索引擎对这类「技术原始制品」的索引能力天然不足。Agent拿到的是"概念上正确"的文档摘要,但它真正需要的是"逻辑上精确"的源码细节。
版本时间错位。搜索引擎天然偏向展示最新版本的文档,而SWE任务的本地环境往往锁定在某个历史版本。更麻烦的是,LLM自身的参数知识也倾向于最新的代码模式。两者叠加,Agent可能会「幻想」出一个不存在的新版本环境,然后用最新的API写法去改老代码——搜索不仅没有纠错,反而加速了错误的落地。
语义漂移与噪声污染。技术术语存在大量歧义。当Agent搜索一个小众库的专有概念时,搜索引擎往往返回来自完全不同领域的高权重结果。Agent缺乏有效的噪声过滤能力,会将"看起来合理"但完全不相关的信息纳入推理链路,导致修复方案偏离正轨。
深度研究与编码
这些实验共同指向一个清醒的判断:search能力和coding能力各自已经相当成熟,但两者的有效融合不会自动涌现。
过去几年,Deep Research(信息检索与知识整合)和Code Agent(代码生成与仓库级推理)各自取得了长足进步,但它们几乎沿着两条平行轨道独立发展。
当真实的软件工程天然要求两种能力的深度融合时——API会更新、依赖会变化、领域知识永远学不完——这种「各自为战」的发展路径就暴露了其根本局限。
Deep Research for Coding——让Code Agent真正具备在编码过程中流畅穿插搜索与推理的能力——是下一阶段进化的关键方向。
BeyondSWE提供了一个在「解决范围」和「知识来源」两个维度上都更全面的评测框架,SearchSWE则为系统研究搜索与编程的融合提供了实验基础。
两者共同的目标,是推动Code Agent从单一仓库的刷题者,真正走向能在开放世界中独当一面的工程智能体。
http://arxiv.org/abs/2603.03194
以上内容对原文进行了改写,确保了编号格式的一致性,并保持了文章的逻辑性和连贯性。
对Agent搜索行为的深入追踪,揭示了三类根本性的障碍:
信息景观的鸿沟。搜索引擎经过几十年优化,擅长检索人类可读的高层文档。但代码任务所需的关键知识,往往深埋在源文件、commit diff和issue评论的只言片语中——搜索引擎对这类「技术原始制品」的索引能力天然不足。Agent拿到的是"概念上正确"的文档摘要,但它真正需要的是"逻辑上精确"的源码细节。

版本时间错位。搜索引擎天然偏向展示最新版本的文档,而SWE任务的本地环境往往锁定在某个历史版本。更麻烦的是,LLM自身的参数知识也倾向于最新的代码模式。两者叠加,Agent可能会「幻想」出一个不存在的新版本环境,然后用最新的API写法去改老代码——搜索不仅没有纠错,反而加速了错误的落地。

语义漂移与噪声污染。技术术语存在大量歧义。当Agent搜索一个小众库的专有概念时,搜索引擎往往返回来自完全不同领域的高权重结果。Agent缺乏有效的噪声过滤能力,会将"看起来合理"但完全不相关的信息纳入推理链路,导致修复方案偏离正轨。

核心启示
Deep Research for Coding
这些实验共同指向一个清醒的判断:search能力和coding能力各自已经相当成熟,但两者的有效融合不会自动涌现。
过去几年,Deep Research(信息检索与知识整合)和Code Agent(代码生成与仓库级推理)各自取得了长足进步,但它们几乎沿着两条平行轨道独立发展。
当真实的软件工程天然要求两种能力的深度融合时——API会更新、依赖会变化、领域知识永远学不完——这种「各自为战」的发展路径就暴露了其根本局限。
Deep Research for Coding——让Code Agent真正具备在编码过程中流畅穿插搜索与推理的能力——是下一阶段进化的关键方向。
BeyondSWE提供了一个在「解决范围」和「知识来源」两个维度上都更全面的评测框架,SearchSWE则为系统研究搜索与编程的融合提供了实验基础。
两者共同的目标,是推动Code Agent从单一仓库的刷题者,真正走向能在开放世界中独当一面的工程智能体。
参考资料:
http://arxiv.org/abs/2603.03194