
机器之心编辑部
在当今时代,人工智能(AI)的发展已经达到了新的高度,其中就包括了AI内容检测工具的应用。
随着AI生成的内容越来越多,尤其是在追求真实性和可靠性的领域,如学术论文写作中,对AI内容的检测变得越来越重要。
那么,这些AI检测工具的准确性如何呢?
可能远远不及预期。
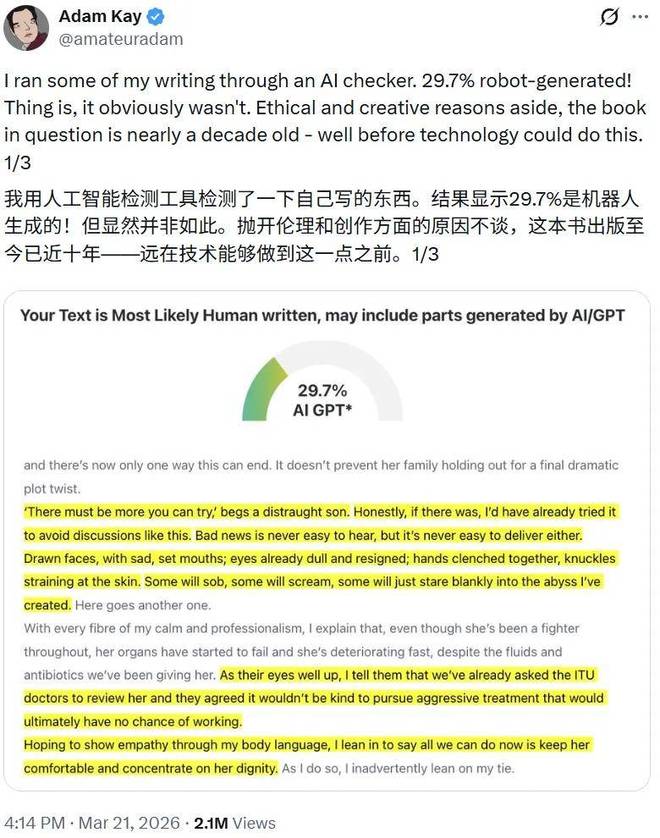
近日,知名作家亚当·凯在社交媒体上分享了他的体验:他将自己的一部作品输入到一款AI检测器中,结果显示有29.7%的内容可能是机器生成的。
这一结果令人啼笑皆非,因为该书早在十年前就已经出版,当时的AI技术根本无法理解书中的复杂句子。
这一事件很快在网络上引起了广泛关注,目前该帖子的浏览量已超过210万次,引发了广泛的“测谎仪挑战”热潮。
学术界成为了误判现象的重灾区。例如,爱丁堡大学的公共卫生教授戴维·斯里达尔的早期文章被检测出有90%的内容是AI生成的。

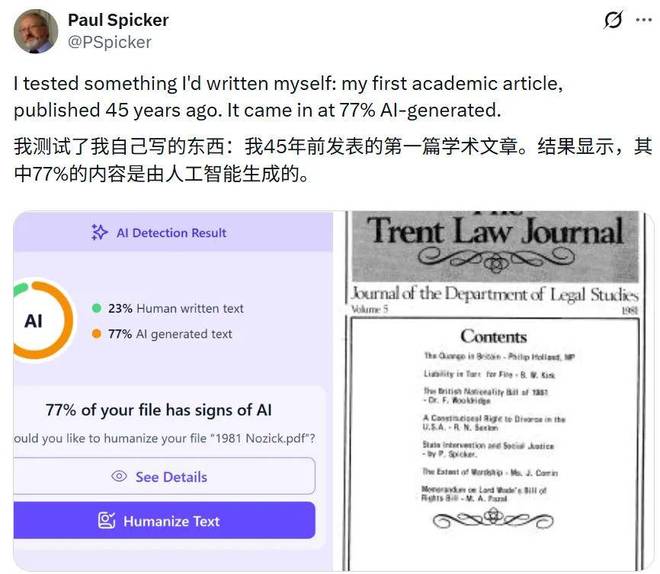
苏格兰阿伯丁罗伯特戈登大学的公共政策荣誉退休教授保罗·斯皮克的一篇论文也被判定有77%的内容是由AI创作的。
众多网友也分享了他们的检测结果。一位网友用自己2008年发表的一篇关于AI的论文进行了检测,结果显示这篇论文完全是由AI生成的,这位网友戏称自己使用的是“GPT负6”版本。

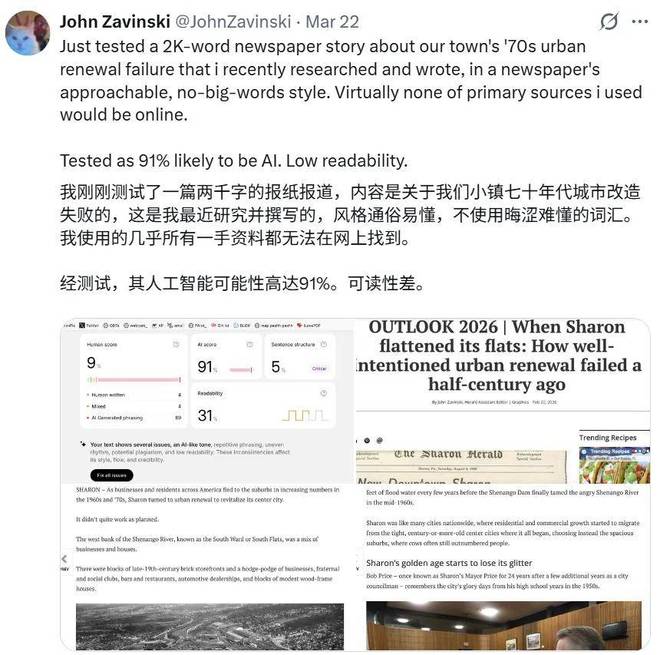
不仅仅是学术圈,新闻报道也未能幸免于被误判的命运。例如,Zavinski测试了自己的新作,一篇关于小镇七十年代城市改造失败的历史报道,该报道使用了通俗易懂的语言且所有一手资料从未在网上公开过。然而,检测结果却判定这篇报道有91%的可能性是AI生成的。
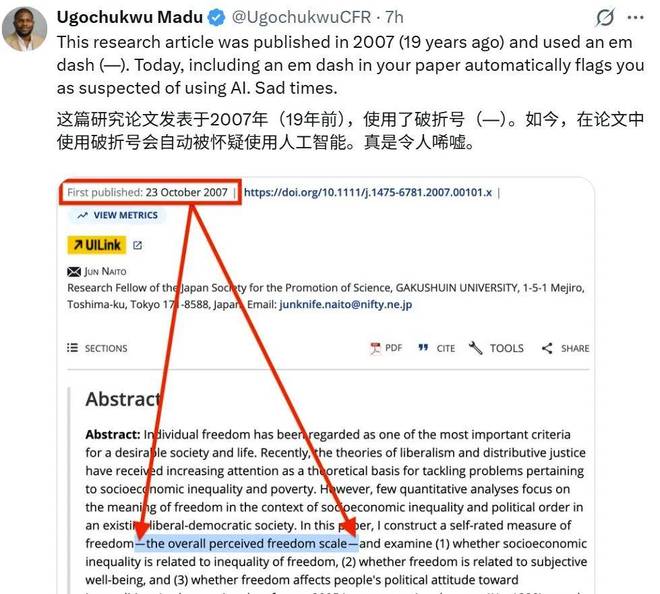
此外,破折号的使用也成为了一项常见的误判指标,这促使许多作者调整了自己的写作习惯。
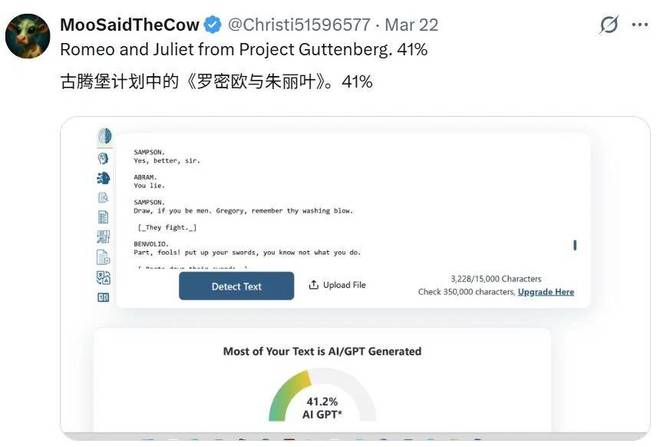
连莎士比亚的经典作品《罗密欧与朱丽叶》也被认为有41%的内容是由AI生成的。
连同《独立宣言》也被AI检测器误判为有99.99%的内容来自AI。

为什么AI检测器会出现这样的误判?
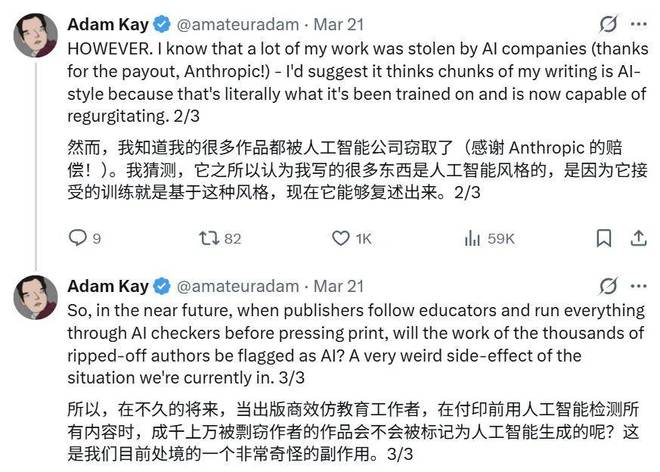
作家亚当·凯提出了一种可能的解释:人类创作的大量内容被用于训练AI模型,因此当AI模型判断某些段落像是AI风格时,实际上是AI再现了它曾经学习过的人类表达。
这种情况在未来可能会导致一个荒诞的后果:当出版商像教育机构一样,在出版前对所有内容进行AI检测时,那些用于训练AI的成千上万的作者的作品可能会被误标为AI生成的。
更令人困惑的是,写作水平越高的作品(如词汇丰富、语法规范),反而越容易被AI检测工具误判为AI生成的。

有评论者认为,“这些AI检测工具简直就是笑话。它们是基于人类创作的数据训练出来的,却反过来质疑人类的智慧和原创性。仅凭这一点就判定某人的作品是AI生成的,既不合理也不公平,更不具备逻辑性。”
这样的质疑并非个例。

一名网友指出,“这些所谓的AI检测工具本质上是荒谬的,它们首先使用人类的知识来训练AI,然后再用这些AI来判断一段内容是否由AI生成,而这个判断本身建立在最初训练所依赖的人类智能之上。从逻辑上讲,这确实是一种荒诞的循环。”

既然AI生成的内容本身源自人类,我们又如何区分这些内容是否真的是AI生成的呢?像不像AI这个问题本身,或许已经失去了明确的界限。