 本文由智东西编辑发布。
本文由智东西编辑发布。
当前,人工智能计算领域的军备竞赛正在如火如荼地进行中,无论是抢购芯片还是囤积算力资源,吉瓦级的数据中心如同雨后春笋般涌现,海外科技巨头更是投入巨资打造大规模的人工智能基础设施建设。
但这些巨额投资是否真正被充分利用呢?或者说,所储备的计算能力是否得到了最大化利用?
据国内RISC-V架构人工智能芯片领域的主要参与者奕行智能的研究团队分析,各类加速器的实际性能远低于理论峰值。
当前的问题并不在于硬件本身不够强大,而是现有的软件调度方式无法在运行时灵活地优化资源分配。有人将售卖算力比作是出售挖掘金矿的铲子,然而同样的工具,在熟练工和新手手中效率会有显著差异。
因此,下一波人工智能计算领域的突破点在于提高芯片利用率,确保每一单位算力都被充分利用。
近期,智东西与奕行智能进行了深入交流,了解到其最新的研究成果正针对这一行业痛点。公司内部已经研发出基于Tile级虚拟指令集实现动态调度的技术(TISA)。
简单来说,TISA提供了一种让芯片在运行时自主决策的架构——通过建立编译器和硬件之间的新调度语义契约,使芯片能够根据实时状态智能分配任务。
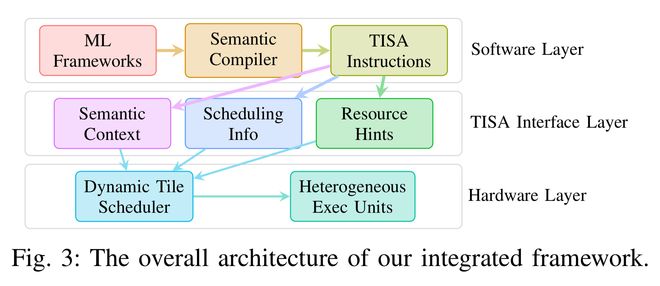
▲TISA的整体结构图
值得注意的是,TISA动态调度技术论文《Dynamic Scheduling for AI Accelerators via TISA》已被ISCA 2026会议接受。这是国内AI芯片公司在该领域的重要突破。
ISCA在计算机体系结构领域具有极高的权威性,被比作是Nature杂志的地位,奕行智能的技术路线因此获得了国际同行的认可。
奕行智能的这一创新为那些寻求高效利用计算资源的人提供了新的途径,帮助他们在人工智能时代更好地把握机遇。
一、买来了算力,为什么效率提升跟不上?解析TISA三大核心技术突破
目前市面上的各种前沿AI芯片单卡性能已经达到每秒千万亿次浮点运算(PFLOPS)甚至更高的水平,峰值计算能力大幅提升,但实际使用中的利用率却远未达到理论极限。
从硬件架构上看,矩阵计算单元、向量计算单元以及数据搬运单元需要协同工作才能实现最高效率。然而传统的“编译时静态调度”模式在程序运行前就确定了所有任务的执行顺序。
这种方法就像工厂管理者预先排定生产计划而不考虑工人请假或设备故障等突发情况,导致资源浪费。
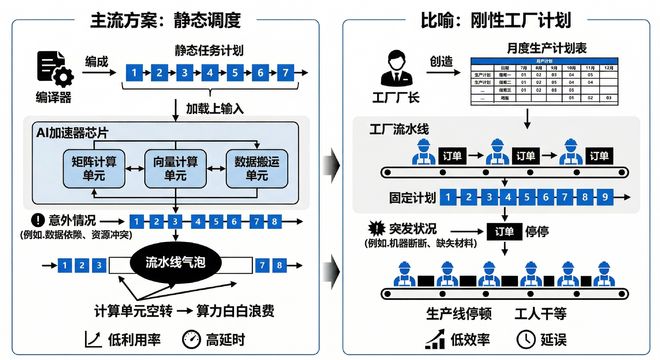
尽管现代GPU已经开始引入动态调度机制,但这些机制仅限于指令级别的调整,并不能有效协调数据搬运单元、张量核心与CUDA Core之间的并发执行问题。
相比之下,TISA架构在突破这一局限方面做出了重要贡献。总体来看,主要体现在三个方面。
其一,开发了一种基于Tile级虚拟指令集的智能编译器技术,可以实时描述任务意图。
其二,设计了能够根据硬件实际状态动态调整调度策略的硬件机制。
其三,实现了自动管理指令间依赖、指令顺序流水和内存切分等功能,显著提高了编程效率。
这些创新技术让奕行智能在开源社区中获得了广泛的关注和支持。与vLLM、Triton等国内外顶尖社区合作,共同推动RISC-V DSA的CUDA生态建设,并计划举办面向高校及科研院所的研发竞赛,加速产学研一体化进程。
三、旗舰级AI芯片已全面上市,赢得市场认可
奕行智能在TISA技术方面的突破已经可以快速应用到自家产品中。公司在产业落地和商业化方面取得了显著成果。
公司已经推出了多款人工智能芯片,并且其最新一代EPOCH芯片已经在行业内主要客户处获得广泛应用,实现了真正的商业价值。

芯片赛道的核心竞争力在于技术创新,奕行智能团队来自业界顶尖系统与芯片公司,在国内多个城市布局研发中心和生产线。从内核架构设计、编译器开发到封装测试,建立了完整的产业链条。
作为唯一一家实现RISC-V云端AI算力芯片大规模量产的企业,奕行智能已成为该领域的重要参与者之一。
结语:从性能竞赛转向能效比竞争,人工智能计算架构迎来新变革
奕行智能相关负责人表示,TISA技术突破的意义不仅在于提升了性能指标,更推动了AI芯片系统设计理念的重大转变——由静态确定性向运行时动态调整。
这一变化离不开一系列关键技术的创新和软件工具链的支持。在追求更高能效比的时代背景下,奕行智能为行业提供了新的解决方案。
面对未来的挑战,AI算力产业已从“通用性能竞赛”转向了“能耗比竞争”的新时代,而以TPU为代表的专用领域计算架构凭借出色的能耗效率在市场上占据领先地位。奕行智能作为其中的佼佼者之一,在这场变革中表现出色。
在国内人工智能芯片市场竞争日益激烈的背景下,奕行智能已经成为强有力的挑战者和赋能者。

▲EVAS解决方案亮点
实际上,近期RISC-V架构在数据中心领域的应用已经成为行业重要趋势方向,包括英伟达重金投资RISC-V龙头企业SiFive以推动其数据中心业务与RISC-V生态系统的融合、Meta面向数据中心的AI芯片MTIA 300也利用了RISC-V向量核心、谷歌将RISC-V作为TPU芯片的底层指令集架构,与此同时,高通、Tenstorrent等相关领域全球科技巨头也在持续加大对“RISC-V+AI”的投入。
奕行智能可以说很早就看清并认定了这一方向,在其团队看来,RISC-V是当前最适合构建AI芯片的指令集架构:开放的图灵完备指令天然支持复杂控制流,可以补上ASIC/NPU的灵活性短板;RVV向量则天然契合AI张量计算,掩码操作原生支持稀疏矩阵;允许在标准之上扩展专用指令的定制化潜力,则让AI芯片可以更好地兼顾通用性与专用性。
在当前全球大国博弈日益激烈的背景下,相较于需授权的Arm和x86架构,RISC-V作为开源开放的指令集架构,天然具有中立性,在打破垄断、构建开放生态、构建自主可控的AI算力底座方面,有着不容忽视的战略意义。
在RISC-V的基础上,奕行智能在芯片架构设计方面有别于传统通用GPU,类谷歌TPU架构专门针对AI计算场景进行了原生优化,可以实现更高能效比,进一步提升AI训练与推理效率,降低算力部署成本。
其自研的E Link互联技术,既可作为AI计算模组内部的芯片间高速互联方式,同时还支持Scale Up与Scale Out融合组网,集合通信库加速,可以满足多种互联拓扑下对大带宽、低延迟的智算互联需求,支持前沿的在网计算。
可以说,这是国产自主高速互联的重要突破。
奕行智能的芯片产品已经面向国产主流大模型进行了深度适配优化,实测性能可以达到国内领先、对标国际一流的水准。在实测中,相比国际竞品,奕行智能芯片在模型推理速度显著提升:RestNet50提升52%,BERT-Base提升31%,GPT-J-6B提升25%,LLAMA2-13B提升43%,提升幅度明显。
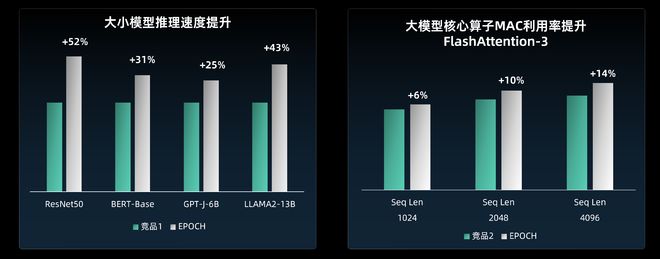
▲EPOCH与竞品芯片性能对比
实际上,类谷歌TPU的专用AI加速芯片通常都会在性能和能效比上有着比通用GPU更大的优势,但其主要挑战来自于生态适配成本,这也是行业努力的方向。
在降低生态适配成本、吸引开发者高效编程方面,基于Tile的编程模式本就能提供更友好的编程接口,提升算子开发效率,而此次入选顶会的独创Tile级动态调度架构,由Tile级虚拟指令集、智能编译器和硬件调度器组成,原生适配Tile生态范式,能实时适配硬件行为,充分挖掘芯片潜力,在编程方面也更为干净简洁。
Tile级动态调度架构的自动管理指令间依赖、指令顺序流水和内存切分,都可以显著提高编程易用性。
生态层面,奕行智能正积极与vLLM、Triton、gitee等国内外开源社区互动,与Triton国际社区合作,把Triton编译导流到RISC-V DSA后端,并将开源其虚拟指令集,合力打造针对RISC-V DSA的CUDA生态,对于RISC-V DSA整个产业的发展具有重要的战略意义。
值得一提的是,奕行智能还计划举办RISC-V AI 应用大赛,面向高校及科研院所开放合作,包括资源支持、技术培训交流等,进一步加速RISC-V产学研生态的发展和成熟。
三、最新旗舰AI芯片已大规模量产,拿下行业头部客户
此次奕行智能在TISA技术方面的突破可以快速落地到自家芯片以及各类主流算力芯片中,并非只是停留在实验室中的技术。实际上,在产业落地和商业化方面,奕行智能已经取得了长足进展。
奕行智能已经发布了多款AI芯片产品,据称其最新一代EPOCH在行业头部客户中持续取得商业突破,可以说是真正走到产业中去了。

当然,芯片赛道归根结底是“技术为王”,扎实的技术研发和产线体系的建立是奕行智能长期在坚持推进的,其核心团队来自业界顶尖系统与芯片公司,目前布局北京、上海、深圳、杭州、南京、广州等地。
从AI内核架构、编译器、ESL 建模,到芯片前后端设计、封测与量产的全链条自研能力,奕行智能均有布局。简单来说,他们有着全流程端到端交付能力和全链路商业化闭环能力。
作为国内唯一实现RISC-V云端AI算力芯片大规模量产的公司,奕行智能无疑已经成为AI时代RISC-V阵营在AI芯片赛道的核心扛旗手。
结语:从通用算力竞赛到能效比对决,AI芯片设计转向“运行时智能”
在交流中,奕行智能相关负责人提到,TISA架构突破带来的并不是一个简单的性能数字提升,而是AI芯片系统设计思路的一次重要转变:从“静态确定性”向“运行时智能”,编译器可以描述意图,进而让硬件实现实时决策。
当然,这背后离不开多项关键技术的创新以及完善软件工具和生态的支撑,在追寻更高能效比、更极致成本的今天,奕行智能着实给行业提供了一种新思路。
面向未来,行业变革仍在继续,成本的重压有增无减,AI算力产业已经从 “通用算力竞赛”进入了“能效比对决”时代,以TPU为代表的专用领域AI计算架构,以突出的能效比取得了市场成功,而奕行智能是其中跑的最快的一批。
在算力版图逐渐重塑、国内AI芯片竞争激烈之下,奕行智能已经成为强有力的行业挑战者和行业赋能者。