
新智元报道
近期,AI技术的进步令人瞩目:从Claude解决复杂算法问题引发的震惊到GPT 5.2 Pro在数学难题上的突破性进展……尽管如此,在某些高难度测试中,这些模型的表现却不尽如人意。
AI领域每天都有新的重大发现或颠覆性的创新出现,让人应接不暇。
即便有夸大的成分,AI的进步速度和成果确实不容小觑。
算法分析权威高德纳对Claude成功解答一道难题表示震惊,并连续使用了“shock”一词来描述这一事件。
数学大师陶哲轩宣布GPT 5.2 Pro已经解决了数学界的Erdos难题,且其解题方法与人类以往完全不同,足以获得博士学位。

此前,Claude Code引发的编程热潮也引起了广泛关注。
在众多长期存在的基准测试中,AI模型的表现已达到优秀标准,这不再令人感到意外。
然而,研究人员已经注意到这些测试在评估现代AI系统的真实能力方面存在局限性。
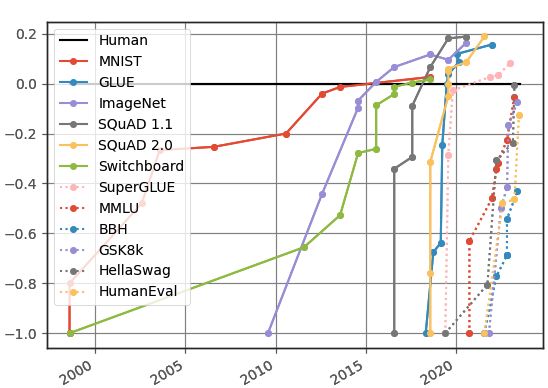
比如大规模多任务语言理解(MMLU)这样的热门评测项目,如今难以充分检验先进系统的实际性能水平。
随着AI模型发展迅速,基准测试的难度也显得相对落后,这影响了对AI安全性的评估准确性。

在诸如MMLU等流行基准测试中,大语言模型的准确率已超过90%,显示出饱和状态。
为了应对这些挑战,“人类最后的考试”这一新基准应运而生,旨在提供更全面和严格的测评标准。
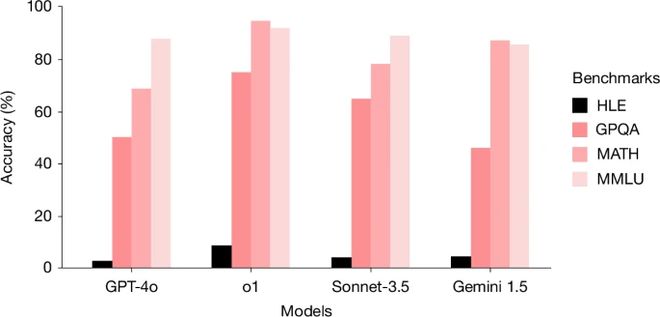
各个大型语言模型在不同基准上的准确性对比
最近,一项由众多研究人员共同撰写的合作论文正式发表于顶级期刊《自然》杂志上!

详情请访问:https://www.nature.com/articles/s41586-025-09962-4
当Alexandr Wang还在Scale AI工作时,这项研究成果就已经在预印本平台Arxiv上发布。
对AI的基准测试变得越来越重要,需要不断进行新的尝试和改进。
为了确保大语言模型的安全性和有效性,在其正式发布前会对其进行多种评估,包括抵抗恶意使用的能力等。
此外,还有一些独立机构对这些系统进行了全面评价,比如检查它们被用于自主识别并利用软件漏洞的风险。
然而,大多数测试往往只覆盖特定学科或包含有限的任务集。
为了建立更广泛、标准化的基准以比较不同模型的表现,MMLU项目使用了大约一万六千道选择题来评估语言理解和解决问题的能力。
随着时间推移,许多之前被认为是难题的问题现在对AI来说已经变得相对简单。
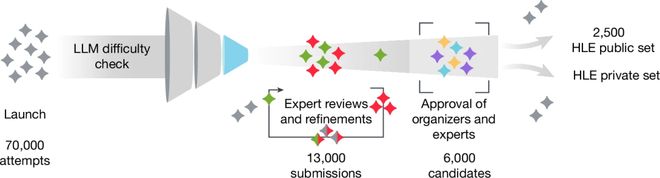
为了弥补这一差距,一个由近1000名研究人员组成的全球联盟开发出了“人类最后的考试”(HLE)。
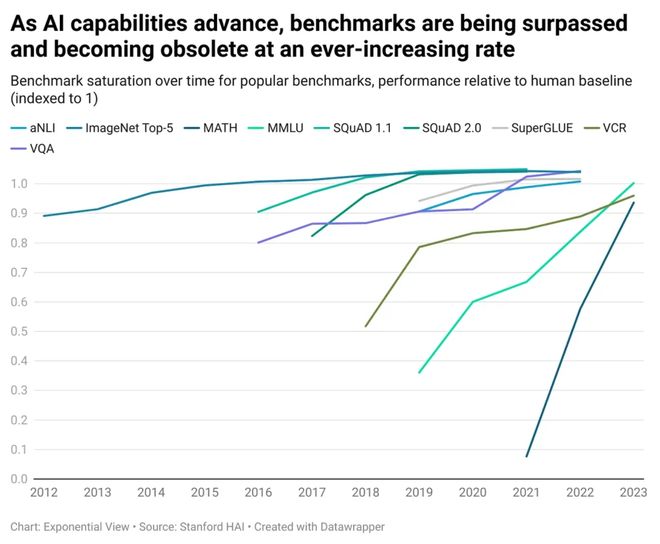
这项测试由CAIS和Scale AI团队联合创建,包含了3000道极具挑战性的题目,旨在成为评估大语言模型能力的一个终极标准。

HLE覆盖了广泛的学科领域,包括数学、人文学科、自然科学以及古代语言等,并且每个问题都经过了严格筛选以确保其难度足够高。
该考试的题目非常专业:从翻译古代巴尔米拉的铭文到分析圣经希伯来语发音的特点等等。
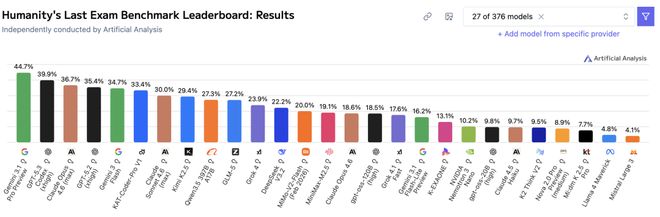
这些题目在设计上充分考虑到了当前最强AI模型的能力边界,保证了测试的有效性和公正性。
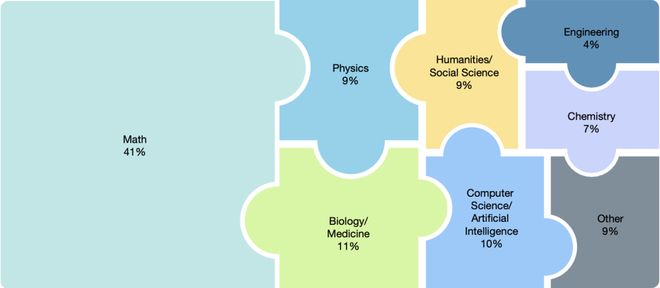
问题学科分布
在提交的数万道难题中精挑细选出了其中最为挑战性的两千五百道题作为最终考试内容。

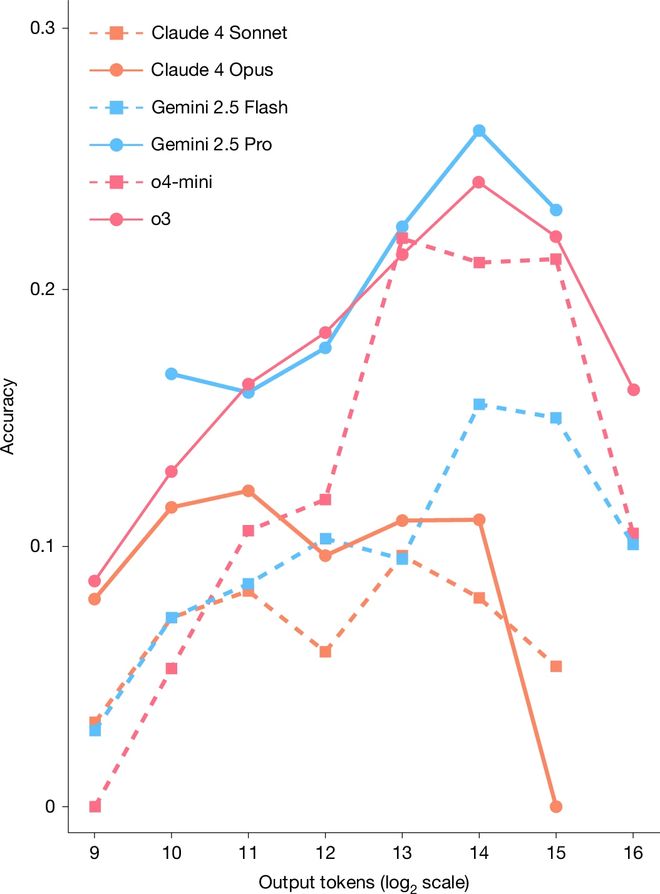
早期的结果显示,即使是顶尖的大语言模型也在这些问题面前难以应对:
GPT-4o得分仅为2.7%;
结果也证实了这一点。
Claude 3.5 Sonnet得分为4.1%;
- OpenAI的旗舰模型o1仅取得8%的成绩。
- Tung Nguyen表示,当AI系统在传统基准测试中表现出色时,人们往往会误以为它们已经接近人类的认知水平。
- 这项考试并非要难倒人类专家,而是为了更准确地揭示AI在特定领域的局限性。
新基准为何重要
Tung Nguyen指出,如果没有适当的评估工具,政策制定者、开发者和用户可能会误解AI系统的实际能力。

尽管名称听起来略显夸张,但“人类最后的考试”并非暗示人类重要性的终结。
相反,它展示了仍有大量知识领域是独一无二地属于人类的,并且AI在这些方面还有很长一段路要走。
Tung Nguyen坦诚说:“这个名字确实带有一些戏谑意味。”
这项考试可以被视为人类为测试AI设立的最后一道难关。如果某款模型能够通过所有考验,就表明它达到了一种专业化的人类专家水平。
HLE涵盖了从核物理到古代史的各种领域,所以没有任何人能独立完成全部题目。
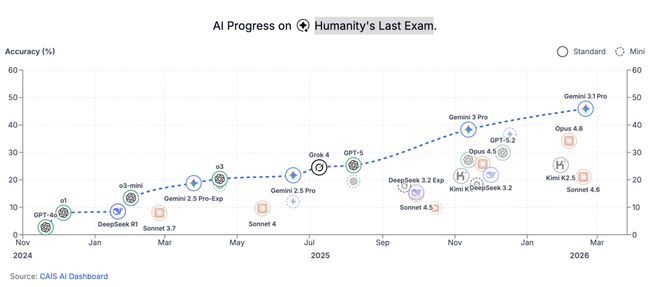
然而,特定领域的专家可以轻松解答自己专业范围内的问题,而AI在几乎所有类别中都表现不佳。
AI擅长模式识别和总结现有数据,但在处理深度背景知识方面却显得力不从心。
HLE中的题目需要多年专门研究才能解决,在这些问题上,“猜测”是行不通的。
https://www.nature.com/articles/s41586-025-09962-4
https://stories.tamu.edu/news/2026/02/25/dont-panic-humanitys-last-exam-has-begun/
相反,它突显了仍有大量知识是独一无二地属于人类的,以及AI还需要走多远。
Tung Nguyen坦言:「这个名字有点半开玩笑的意味」。
重要的是背后的理念:
这是人类对AI的设置的最后一道难关。如果AI能通过这项考试,就意味着它达到了某种专业化的人类专家水平,而这在以前被认为是机器不可能做到的。
因为HLE涵盖了从核物理到古代史的所有领域,所以没人能通过单打独斗的通过整个考试。
然而,特定领域的人类专家可以轻松回答其专业领域内的问题,而AI在几乎所有类别上都失败了。

为什么AI还会失败?
原因在于AI擅长模式识别和总结已知数据,但它难以处理深度、专业化的背景知识。
HLE提出的问题需要多年的专门研究。在这些问题上,基于常见互联网数据的「猜测」行不通。
参考资料:
https://www.nature.com/articles/s41586-025-09962-4
https://stories.tamu.edu/news/2026/02/25/dont-panic-humanitys-last-exam-has-begun/